お気軽にお問い合わせください
協調フィルタリングとは?「あなたへのおすすめ」の正体を徹底解説!

目次
協調フィルタリングとは
協調フィルタリング(Collaborative Filtering)とは、ユーザーの行動履歴(購買・閲覧・評価など)をもとに「似たユーザー」または「好んだアイテム」を探索し、まだ触れていないアイテムを推薦するレコメンド手法です。
アイテム属性やユーザー属性を使わずに分析ができるため、業界特有の専門知識がなくても、思いがけない関連性や発見を得られる点が特徴です。
| アプローチ | 仕組み | レコメンドイメージ |
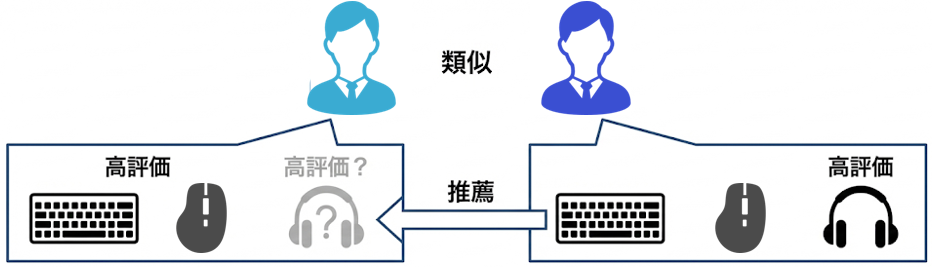
| ユーザーベース協調フィルタリング(UserCF) | ターゲットユーザーと嗜好が似ている他ユーザーを探し、その人たちが高評価したアイテムを推薦する | 「あなたに似たユーザーは○○も購入しています」 |
| アイテムベース協調フィルタリング(ItemCF) | ターゲットユーザーが過去に好んだアイテムに似ているアイテムを推薦する | 「この商品を購入したはこんな商品も買っています」 |
ユーザーベース(UserCF)とアイテムベース(ItemCF)は名前は似ていますが、「何を基準に類似度を算出するか」によって得意・不得意が分かれます。
この違いを理解しておくことで、後述する各手法の仕組みや活用シーンを整理しやすくなります。
ユーザーベース協調フィルタリング(UserCF)
2種類の手法について仕組み、活用シーンの観点で整理すると下表の通りです。
| 項目 | 概要 | 解釈・補足 |
| 仕組み | ターゲットユーザーに対して好みが近い他のユーザーを上位数十名選び、その人たちが高評価したアイテムを推薦 | 似た人が好きなものはターゲットユーザーも好きだろうという発想 |
| 活用シーン | 興味関心が共通するコミュニティ | 例えば専門フォーラム、ファンサイトなどでは、ユーザー間の嗜好パターンが明確に現れやすく、類似ユーザーの特定精度が高まるため効果的 |
アイテムベース協調フィルタリング(ItemCF)
| 項目 | 概要 | 解釈・補足 |
| 仕組み | ユーザーが過去に高評価した(または購入した)アイテムと似ているアイテムを見つけ出し推薦 | ECサイトなどで見る「この商品を購入した人は…」という表示が典型例 |
| 活用シーン | アイテム数が多く、ユーザー 1 人あたりの購買・視聴履歴が豊富なサービス | 例えばEC、動画配信などと相性が良く、ロングテール商品まで含めた多様な推薦が可能 |
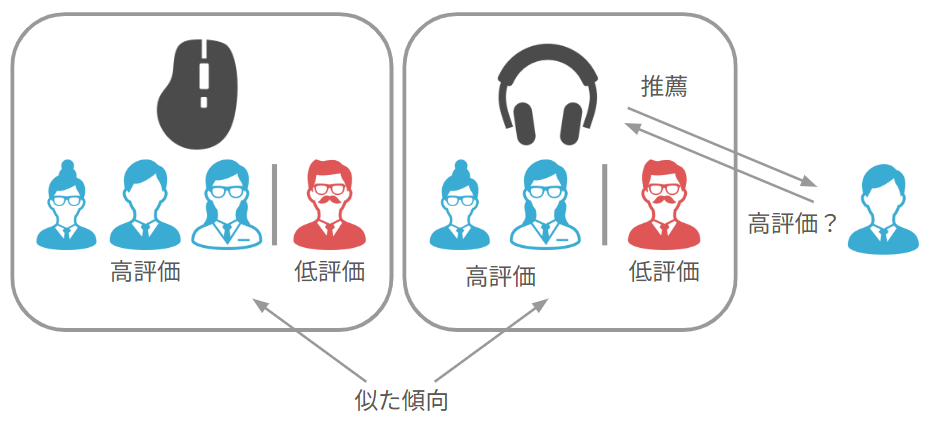
UserCF は「似た人」、ItemCF は「似たモノ」を基準にした推薦手法です。
どちらもユーザーの行動履歴から類似性を見つけ出し、まだ触れていないアイテムを推薦する点は共通していますが、「人に着目するか」「アイテムに着目するか」という視点の違いによって、適した活用シーンが異なります。
サービスの特性やデータの構造に応じて使い分けることで、より自然で納得感のある推薦が可能になります。
協調フィルタリングによるレコメンド手順(仕組み・理論)
協調フィルタリングでは、行をユーザー、列をアイテムとする「ユーザー・アイテム評価行列」をまず作成します。
各セル \((u,i)\) には、例えば 5 段階評価や購買・視聴などの行動量が格納されます。実務で扱うこの行列は、多くのセルが空欄(未評価)です。分析の目的はシンプルで、この空欄に「嗜好の強さ(好きの度合い)」を予測して埋めることです。そのためにまず、「誰(または何)が似ているのか」を定量化する類似度計算を行います。
1. 類似度の計算
代表的な指標はコサイン類似度とピアソン相関係数の2種類です。
- コサイン類似度
評価ベクトルの角度に着目し、スケールよりも方向性の近さを測ります。
共通して評価したアイテム集合を \(I_{uv}\)とすると、ユーザー \(u,v\) のコサイン類似度は次式で表されます。
\begin{equation}
\mathrm{sim}_{\cos}(u,v) =
\frac{\displaystyle\sum_{i \in I_{uv}} r_{u,i}\, r_{v,i}} {\sqrt{\displaystyle\sum_{i \in I_{uv}} r_{u,i}^{2}}\; \sqrt{\displaystyle\sum_{i \in I_{uv}} r_{v,i}^{2}}}
\end{equation}
- ピアソン相関係数
各ユーザーの平均評価\(\overline{r}_{u}\), \(\overline{r}_{v}\) を引いて正規化し、評価スケールの違いを補正します。
例えば「厳しめに★3を多用する人」と「甘めに★5を多用する人」でも、傾向の上下動が似ていれば高い相関を示します。
\begin{equation}
\mathrm{sim}_{\mathrm{pearson}}(u,v) =
\frac{\displaystyle\sum_{i \in I_{uv}} \bigl(r_{u,i} – \bar{r}_u\bigr)\,\bigl(r_{v,i} – \bar{r}_v\bigr)}{\sqrt{\displaystyle\sum_{i \in I_{uv}} \bigl(r_{u,i} – \bar{r}_u\bigr)^2}\; \sqrt{\displaystyle\sum_{i \in I_{uv}} \bigl(r_{v,i} – \bar{r}_v\bigr)^2}}
\end{equation}
コサイン類似度は「好みの方向性」が似ているかを見ており、ピアソン相関係数は「評価の上がり下がりのパターン」が一致しているかを見ている点が異なります。
クリックや視聴時間などの間接的な反応データ(暗黙的データ)の場合は、数値の偏りを調整してからコサイン類似度で方向性を比較する方法がよく採用されています。逆に5段階評価など(明示的データ)、ユーザーによって甘め、厳しめのばらつきがある場合は、ピアソン相関係数でスケールの違いを吸収したうえで評価する方法が採用されることが多いです。
| 観点 | コサイン類似度 | ピアソン相関係数 |
| 考え方 | 評価ベクトルの角度を測る(方向性の一致) | 各ユーザーの平均からのズレを基準に相関を測る(相対的な強弱の一致) |
| 強み | 暗黙的データ(クリック数・視聴秒数など) に強い | 明示的データ(★評価など)に強い |
| 弱み | スケールの違いを考慮できない | 評価分布が平坦な(ばらつきが小さい)ユーザーでは相関が不安定 |
数式・文字式の解説
\begin{eqnarray}
u, v &:& 類似度を比較する2人のユーザー(ここではuを基準ユーザー、vを比較対象)\\
i &:& アイテムを表すインデックス(例:映画、商品、コンテンツなど)\\
r_{u,i} &:& ユーザーuがアイテムiに付けた評価値(★評価、閲覧回数など)\\
\bar{r}_u &:& ユーザーuの平均評価値(uがこれまでに付けた評価の平均)\\
I_{uv} &:& ユーザーuとvが共通して評価したアイテムの集合\\
\mathrm{sim}_{\cos}(u,v) &:& ユーザーuとvのコサイン類似度(評価の方向性の近さ)\\
\mathrm{sim}_{\mathrm{pearson}}(u,v) &:& ユーザーuとvのピアソン相関係数(評価の上下傾向の近さ)\\
\end{eqnarray}
2. 予測の計算
類似度を求めた後は、未評価項目のスコアを予測します。
基本的な考え方は、「類似度に応じて重みづけをし、平均を算出する」という考え方で、ユーザーベースとアイテムベースどちらも共通です。
- ユーザーベースの場合
対象ユーザー\(𝑢\)と似ている上位\(k\)人のユーザー集合\(𝑁_{𝑘}(𝑢)\)(近傍という)の評価を集め、類似度に応じて重み付けしながら平均を算出します。平均値の補正も含めた一般的な計算式は以下です。
\begin{equation}
\hat{r}_{u,i}= \bar{r}_u+ \frac{\displaystyle \sum_{v \in N_k(u)} \mathrm{sim}(u,v)\,\bigl(r_{v,i}-\bar{r}_v\bigr)}{\displaystyle \sum_{v \in N_k(u)} \bigl|\mathrm{sim}(u,v)\bigr|}
\end{equation}
- アイテムベースの場合
アイテムベースでは、今回推薦したいアイテム \(i\) と似ている上位 \(k\) 個のアイテム集合 \(S_k(i)\) を用います。そのうち、ユーザー \(u\) がすでに評価しているアイテムに対する評価値を取り出し、アイテム間類似度に応じて重み付け平均を行います。
\begin{equation}
\hat{r}_{u,i}= \frac{\displaystyle \sum_{j \in S_k(i)} \mathrm{sim}(i,j)\, r_{u,j}}
{\displaystyle \sum_{j \in S_k(i)} \bigl|\mathrm{sim}(i,j)\bigr|}
\end{equation}
3. ランキングと更新
最後に、各ユーザーに対して未評価アイテムの \(\hat{r}_{u,i}\)を算出し、スコアが高い順に並べてランキングを作ります。画面上では「あなたへのおすすめ」や「この商品を見た人はこんな商品も見ています」といった形で上位何件かを表示し、クリック率や購入率、動画であれば視聴完了率などの指標で効果検証します。
類似度計算 → 予測 → ランキング作成という一連の処理を効率よく回すためには、定期的な更新と、ユーザーの最新行動を即時反映するリアルタイム更新を使い分けることが実務上のポイントとなります。
補足:ノイズ対策と信頼度の確保
協調フィルタリングでは、共通して評価したアイテム数が極端に少ない場合、類似度が安定せず誤判定につながることがあります。特に、データが少ない領域では、偶然同じ評価を付けただけでも高い類似度が計算されてしまう場合もあります。
こうした状況を避けるために、共通評価数が一定以上(例:5件)ある場合のみ類似度を信頼する、など最低ラインの設定が有効です。この考え方は、例えば映画推薦で共通して評価した作品が1本しかないユーザー同士を「似ている」と判断しない、といったイメージです。
この点は、協調フィルタリングを安定して動かすための前提条件のひとつとして、意識しておく必要があります。
お気軽にご相談ください!
当サイトの運営会社であるデータアナリティクスラボ株式会社は、データサイエンティストのプロフェッショナルサービスを提供しています。協調フィルタリングをはじめとしたデータ分析の実績も多数ございますので、お気軽にご相談ください。
ご相談・お問い合わせはこちらから
必要なデータ
協調フィルタリングは、利用者が過去に何を「評価した・使った」かという記録から好みを算出する仕組みです。その精度を左右するのは、主にデータの種類・詳細さ・データ量の3点です。これらが不十分だと、行列内に空欄のセルが多くなり、推薦の精度が安定しません。
データの種類
実際の運用ではデータを直接的な反応と間接的な反応に分けて扱います。
| 区分 | 内容 | 例 |
|---|---|---|
| 直接的反応(明示的データ) | ユーザーが明確に好みを示すもの | ★1〜★5の評価、レビューコメントなど |
| 間接的反応(暗黙的データ) | 行動から好みを推定するもの | 履歴(購入・閲覧・視聴)、 クリック数、滞在時間など |
クリック数や購入回数といった指標も、明示的な評価が得られない場面では、間接的な反応として推薦に活用できます。
例1:明示的データ(★1〜★5の評価)
| アイテムA | アイテムB | アイテムC | アイテムD | アイテムE | |
|---|---|---|---|---|---|
| ユーザー1 | 5 | 3 | — | — | 4 |
| ユーザー2 | 4 | — | 2 | — | — |
| ユーザー3 | — | 5 | 4 | 2 | — |
| ユーザー4 | 1 | — | — | 4 | 3 |
「—」は未評価です。協調フィルタリングでは、この空欄(例:ユーザー1×アイテムCなど)に対し、嗜好の強さ \(\hat{r}_{u,i}\) を予測して埋めます。
例2:暗黙的データ(閲覧/視聴回数など)
| アイテムA | アイテムB | アイテムC | アイテムD | アイテムE | |
|---|---|---|---|---|---|
| ユーザー1 | 12 | 4 | — | 3 | 7 |
| ユーザー2 | 1 | — | 2 | — | — |
| ユーザー3 | — | 15 | 9 | 2 | — |
| ユーザー4 | 0 | — | — | 6 | 5 |
暗黙的データでは 0 は「観測はあるが行動なし」、「—」 は「未観測」と扱う場合が多いです。
また暗黙的データでは再生数やいいね数のように、値のばらつきが極端に大きい場合や、指標ごとにスケールが異なる場合があります。
評価の予測計算に用いる際は、例えば対数変換などでスケールを圧縮し、擬似的な好みスコアに変換することが推奨されます。
その後は明示的データと同様に、類似度の計算 → 近傍の重み付き平均による予測 → ランキング作成という流れで「—」のセルを推定し、「おすすめ」として提示します。
データの詳細さ
詳細さとは、データがユーザーの嗜好をどの程度細かく表せるかを意味します。
例えば、単純なクリック有無よりも滞在時間や購入金額を扱う方が、関心の強弱をより正確に捉えられることがあります。同様に、5段階評価よりも10段階評価の方が、細やかな好みの差を反映できます。
ただし、これらの行動データのうちどれが嗜好を把握する上で影響が大きいかは、推薦対象となる商材やサービスの性質によって異なります。そのため、必ずしもすべての項目を詳細に取得するわけではなく、影響の大きい行動データを重点的に詳細化する、という視点でデータ設計を行うことも重要です。
また、年齢・地域・ジャンルといった属性情報は必須ではありませんが、他手法と組み合わせる際の補助データとして有用です。
データの量
精度の良い分析を行うためには、データの量は重要です。データが少ないと、わずかな情報で判断することになり、誤った推薦につながる恐れがあります。
そのため、十分な件数を確保するとともに、
- 項目をカテゴリ単位にまとめる
- 一定の出現回数を満たさないデータを除外する
などの工夫でスパースネス(疎なデータ、詳細は「分析における注意点・弱点」)への対策を講じます。
この考え方は、類似ユーザーや類似アイテムを探索するときにも同様に当てはまります。
信頼できる推薦には、多様で十分な行動記録が必要不可欠です。
協調フィルタリングの活用例
映画推薦システムの例
本節では、協調フィルタリングがどのように「おすすめ」を作成するのか、映画データを用いて具体的な流れを説明します。
使用するデータは、データサイエンス・機械学習のオンラインプラットフォームの『Kaggle』で公開されている 「The Movies Dataset」です。
ある特定のユーザーに対して、アイテムベース協調フィルタリング(ItemCF) による推薦を行います。
ItemCFでは、ユーザーがまだ見ていない映画の評価を直接得ることができないため、まずは「これまでに高評価した映画と似ている作品」を特定する必要があります。また、ここでの類似度はコサイン類似度を用いるため、多くのユーザーがどのように評価したかという評価パターンの類似性を確認します。評価パターンが近い映画同士は、視聴者の感じ方が似ていると考えられるため、推薦の基礎として利用されます。
STEP
類似度の算出
ではまず、全映画同士の組み合わせで、アイテム間のコサイン類似度を算出します。ここでは計算コスト削減のため、あらかじめユーザーの評価が100件以上ついている映画のみに絞って行列を算出することにします。
本来は「意外な発見」を期待するため、絞り込む本数は計算コストだけでなく、ビジネスサイドの要件や目的も考慮したうえで決定するのがよいと考えられます。
その結果151×151の類似度行列が算出されました。ここではその一例として「タイタニック」に関して類似度が高い上位8本を下表にまとめます(これがタイタニックの近傍\(S_{k}(i)\)となります)。
つまり、下記のような近傍が計151映画分あることになります。
| タイトル | コサイン類似度 |
|---|---|
| Men in Black | 0.561 |
| The Sixth Sense | 0.555 |
| The Truman Show | 0.533 |
| Forrest Gump | 0.526 |
| Saving Private Ryan | 0.522 |
| Jerry Maguire | 0.515 |
| There’s Something About Mary | 0.508 |
| Good Will Hunting | 0.502 |
STEP
予測スコアの算出
次に、おすすめを表示したい特定の1ユーザー(以降目的のユーザーと呼ぶことにします)に絞って、その人がまだ評価していない映画の評価値を予測をしていきます。
ここで冒頭でお伝えした予測式を確認します。
\begin{equation}
\hat{r}_{u,i}= \frac{\displaystyle \sum_{j \in S_k(i)} \mathrm{sim}(i,j)\, r_{u,j}}
{\displaystyle \sum_{j \in S_k(i)} \bigl|\mathrm{sim}(i,j)\bigr|}
\end{equation}
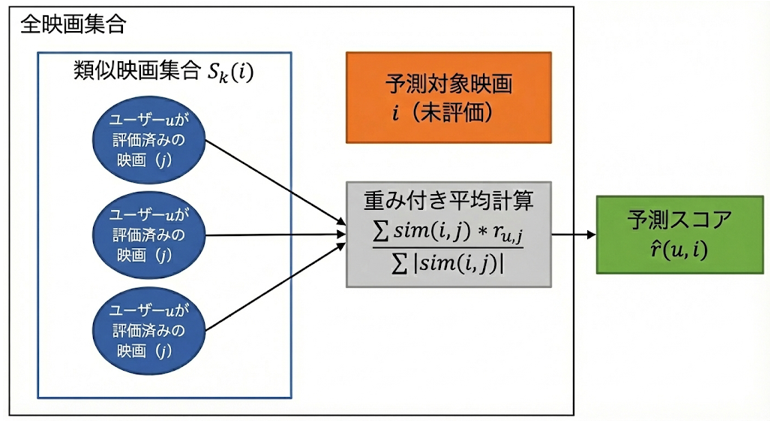
前述の\(S_{k}(i)\)は全映画に対する近傍でしたが、この時点で\(j\)として選出されるのは、\(S_{k}(i)\)のうち目的のユーザーが評価をつけたことがある映画に絞られている、という点に注意です。
一方で\(i\)は、今回予測対象となる映画なので目的のユーザーがまだ評価していない映画となります。
1つの映画\(i\)に対して\(j\)個分の類似度が存在しますので、それらを加重平均し、1つの予測値\(\hat{r}_{u,i}\)を算出します。
STEP
ランキングの算出
全ペアに対して加重平均を計算し、その予測値が高い順にランキングしたものが下表です。
| タイトル | ジャンル | 評価の予測値 |
|---|---|---|
| Sleepless in Seattle | Comedy / Drama / Romance | 4.02 |
| Ghost | Comedy / Drama / Family / Fantasy / Horror / Mystery / Romance / Thriller | 4.00 |
| Interview with the Vampire | Horror / Romance | 3.99 |
| The Net | Action / Crime / Documentary / Drama / Mystery / Thriller | 3.99 |
| GoldenEye | Action / Adventure / Thriller | 3.98 |
| Batman | Action / Adventure / Comedy / Crime / Family / Fantasy / Science Fiction | 3.98 |
| Outbreak | Action / Drama / Science Fiction / Thriller | 3.98 |
| The Firm | Drama / Mystery / Thriller | 3.97 |
| While You Were Sleeping | Comedy / Drama / Romance | 3.97 |
| Clear and Present Danger | Action / Drama / Thriller | 3.96 |
上位の作品を確認すると、いずれもロマンス寄りのヒューマンドラマ(Romance, Drama)や、ほどよい緊張感をもつサスペンス・スリラー(Thriller)作品が多く含まれていました。
ちなみに、この目的のユーザーが過去にどのような映画に高評価をつけていたのかも確認します。
これにより、この推薦が妥当であるのかを確認します。
このユーザーが実際に★5を付けていた映画は以下の通りです。
| タイトル | ジャンル | 評価 |
|---|---|---|
| Undertow | Drama / Thriller / Romance / Mystery | 5.0 |
| Duel | TV Movie / Action / Thriller | 5.0 |
| Crash | Drama / Thriller | 5.0 |
| Stolen Kisses | Comedy / Drama / Romance | 5.0 |
| Aparajito | Drama | 5.0 |
| The Shawshank Redemption | Drama / Crime | 5.0 |
| Mr. Smith Goes to Washington | Comedy / Drama | 5.0 |
| Run Lola Run | Action / Drama / Thriller | 5.0 |
| The 400 Blows | Drama | 5.0 |
| Cinema Paradiso | Drama / Romance | 5.0 |
| The Princess Bride | Adventure / Family / Fantasy / Romance | 5.0 |
| Nights of Cabiria | Drama | 5.0 |
| Pleasantville | Fantasy / Drama / Comedy | 5.0 |
これらはヒューマンドラマ系の名作が中心で、ドラマ性に加えて、葛藤・驚きといった感情を動かす要素を持つ点で類似しています。そのため、今回の推薦結果は単に同ジャンルの抽出では見抜けなかった、ユーザーが好んできた作品の持つ情緒的な特徴も反映しており、一定の納得感がある結果になったと考えられます。
以上の結果から、ItemCFは単に「似た作品を並べる」だけの仕組みではなく、ユーザー自身の評価履歴に基づいて、どの作品がより好まれる可能性が高いかを定量的に推定できる手法であることが確認できます。
特に本例のように、ユーザーが過去に高く評価した作品群と推薦結果のテーマ性が整合している場合、モデルが捉えている好みの傾向には一定の納得感があります。
また、作品内容を直接参照せずとも、評価パターンからユーザーの関心軸や好みを推測できる点は、協調フィルタリングの強みといえます。
こうした特徴から、ItemCF は実務においても、なぜその映画が選ばれたのかを説明しやすく、ユーザー体験の向上に寄与する技術として有用です。
その他の活用事例
そのほかにも、協調フィルタリングはユーザーの行動履歴をもとに、サービスの利用頻度を高める仕組みとして、さまざまな分野で活用されています。以下の例はいずれも、ユーザーが自然な形でコンテンツや商品に触れる機会を増やし、結果としてサービス全体の利用価値を高めることを目指しています。
- ECサイト
閲覧・購入履歴から似ている商品を見つけ、商品詳細ページやカート画面で
「よく一緒に買われている商品」「あなたへのおすすめ」として表示可能です。
関連商品の購入(ついで買い)を自然に促し、一回の購買金額の向上に貢献します。 - 音楽ストリーミングサービス
再生・プレイリスト作成・お気に入り登録といった行動ログをもとに、好みの近い利用者グループから
「新しい発見」向けのプレイリスト(例:今週のおすすめ)の自動作成が可能です。
ユーザーがまだ出会っていない楽曲の発見を促し、利用時間とエンゲージメントを向上させます。
お気軽にご相談ください!
当サイトの運営会社であるデータアナリティクスラボ株式会社は、データサイエンティストのプロフェッショナルサービスを提供しています。協調フィルタリングをはじめとしたデータ分析の実績も多数ございますので、お気軽にご相談ください。
ご相談・お問い合わせはこちらから
分析における注意点・弱点
協調フィルタリングはシンプルで納得感のある推薦を実現できる一方で、実務の場ではいくつかの注意点があります。
ここでは代表的な5つの注意点を整理します。
1. コールドスタート問題
コールドスタート問題(Cold Start Problem)とは、新規ユーザーや新規アイテムに関するデータが不足しているために正しく推薦が行えない状況を指します。
協調フィルタリングは過去の行動履歴をもとに類似性を算出するため、新しく登録したユーザーや、リリース直後のアイテムには履歴が存在せず、「似ている人」「似ているモノ」を見つけることができません。
この結果、以下のような問題が生じます。
- 新商品や新作の露出が少なくなる
- 初回利用時のユーザー体験が弱くなる
実務では、初期段階のみ人気順・編集者推薦・広告連携など別の施策を組み合わせて、ユーザーの目に触れる機会を確保する必要があります。
2. データスパースネス問題(データが疎な状態)
ユーザー数やアイテム数が増加すると、評価行列の大部分が空欄(未評価)のままとなり、
共通して評価された項目が極端に少なくなります。
特に、購入頻度の低いロングテール商品が多いサービスでは、類似度が安定せず推薦精度が低下します。
例えば下表では、ロングテール商品C, D, Eを評価しているユーザーが少ないため、推薦精度が不安定になります。
| 人気商品A | 人気商品B | ロングテールC | ロングテールD | ロングテールE | |
|---|---|---|---|---|---|
| ユーザー1 | 5 | 4 | ー | ー | ー |
| ユーザー2 | 3 | 4 | ー | ー | ー |
| ユーザー3 | 4 | 5 | 2 | ー | ー |
| ユーザー4 | 5 | ー | ー | 4 | ー |
| ユーザー5 | ー | 3 | ー | ー | 3 |
対策としては以下のような方法が考えられます。
- 商品カテゴリ単位での集約
- 最低出現回数のしきい値設定
- アイテム属性情報を併用したハイブリッド化
これにより、疎なデータ構造でも類似関係を保ちながら計算を安定化できます。
3. 人気バイアス
推薦結果が「多くの人が閲覧・購入している人気アイテム」に偏りすぎると、多様性が失われ、個別性のない推薦になります。
ユーザーは「どこでも見かける定番ばかりが出る」と感じ、新しい発見の機会を失う可能性があります。
対応策としては、以下のようなアプローチが考えられます。
- 人気度に応じてスコアを補正(正規化)
- 極端に人気なアイテムを意図的に除外
- ランダム推薦を混ぜて探索性を確保
4. プライバシー・倫理上の懸念
協調フィルタリングは大量の行動ログを利用するため、データの匿名化が不十分な場合、個人の嗜好や属性が推測されるリスクがあります。
特に医療・金融・政治などセンシティブな領域では、「本人が意図しない形で行動傾向を分析される」こと自体が倫理的問題となります。
そのため、以下のようなことが求められます。
- 利用規約での明示的な同意取得
- 匿名化・差分プライバシーなどの技術的保護
- 推薦根拠の説明可能性の確保
5. 計算コスト
ユーザー数やアイテム数が数百万以上になると、ユーザー同士・アイテム同士の類似度を全探索する計算コストが急増します。
そのため実務では、下記のような方法でコスト削減を図れないか検討します。
- 近似的な類似探索
- クラスタリングによる探索範囲の制限
近似的な類似探索とは、精度をわずかに犠牲にする代わりに、計算時間を大幅に短縮できることが特徴です。例えば、全映画を1本ずつ比較する代わりに、特徴が近いものだけを候補として取り出し、似ていないものは最初から比較しないといった仕組みを使います。これにより、「最も似ているものを厳密に1位から10位まで求める」代わりに「実務上ほぼ問題ないレベルで似ている候補」を素早く見つけることができます。
また、クラスタリングとは、似たユーザーやアイテム同士をあらかじめグループ分けしておく方法です。
例えば映画であれば、ヒューマンドラマ中心のグループ、アクション・スリラー中心のグループ、ファミリー向け作品のグループといった形で、性質の近いもの同士をまとめておきます。推薦時には、すべての映画と比較するのではなく「同じグループ内」だけで類似度を計算するようにすることで、探索範囲を大きく絞れます。これにより、計算量を減らしつつ、一定の効果が期待できそうな比較だけを行えるようになります。
このような技術的工夫により、リアルタイム性と精度の両立が期待できます。
まとめ
本記事では、協調フィルタリングの基本概念、仕組み、必要なデータ、実装例、そして実務で注意すべき点について整理しました。協調フィルタリングは、ユーザーの行動履歴から嗜好パターンを抽出し、属性情報を用いずに「似た人」「似たモノ」を見つけられる点に特徴があります。EC・動画配信・音楽ストリーミングなど、多くのサービスで採用されている、実用性の高い推薦手法です。
一方で、コールドスタート問題やデータスパースネスといった構造的な制約があり、人気バイアスやプライバシーの観点にも十分な配慮が必要です。また、計算負荷が大きくなりすぎる場合は、近似探索などの実装工夫も必要に応じて検討します。これらの課題を考慮しつつ、十分なデータ量の確保と、必要に応じた補完的手法の組み合わせが、現実的な推薦精度の向上につながります。
本稿の内容が、協調フィルタリングの導入や改善を検討する際の一助となれば幸いです。
お気軽にご相談ください!
当サイトの運営会社であるデータアナリティクスラボ株式会社は、データサイエンティストのプロフェッショナルサービスを提供しています。協調フィルタリングをはじめとしたデータ分析の実績も多数ございますので、お気軽にご相談ください。
ご相談・お問い合わせはこちらから
こちらもご覧ください
データアナリティクスラボ
2024年版「働きがいのある会社」に初認定のお知らせ | データアナリティクスラボ
当社はこの度、Great Place to Work® Institute Japan(以下「GPTW Japan」)が実施する2024年版「働きがいのある会社」に初認定されましたことをお知らせいたします。 社員…
データアナリティクスラボ
量子コンピュータ技術への取り組みについて | データアナリティクスラボ
この度、日本量子コンピューティング協会の主催する量子エンジニア(ゲート式)講座ー認定講座-、量子エンジニア(アニーリング式)講座-認定講座-両方において当社社員…
データアナリティクスラボ
サッカーベルギー1部リーグ、シント=トロイデンVVとスポンサー契約を締結 | データアナリティクスラボ
サッカーベルギー1部リーグ、シント=トロイデンVV(以下STVV)と2023-2024シーズンのスポンサー契約を締結したことをお知らせいたします。 欧州の5⼤リーグに迫る勢いと…
データアナリティクスラボ

MBPS(混合ベイズ時系列結合)の実装 | データアナリティクスラボ
Indexはじめに1.論文紹介2.MBPS(混合時系列結合)2.1 ベイズ予測合成(BPS)数式変数利点例: ポアソン分布を用いたMBPS:MBPSが優れている理由3.複数か国での金融時…