
お気軽にお問い合わせください
傾向スコア分析とは?観察データで因果を推定する手法をわかりやすく解説!
目次
傾向スコア法とは
因果推論とは、「ある施策や処置が結果にどのような影響を与えたのか」を明らかにするための分析アプローチです。
因果推論において最も信頼性が高い方法とされているのが、RCT(ランダム化比較試験)です。RCTでは、介入群と対照群を無作為に割り当てることで、両群の属性の偏りを排除できるため、処置の効果をより正確に推定できます。しかし、実際のビジネスの現場では、倫理的・時間的な制約などにより、RCTの実施が難しい場合も少なくありません。
その場合、観察データを用いた分析をおこなうことになりますが、そこでは「どの人が処置を受けるか」がランダムではないため、選択バイアスが生じやすいという課題があります。
傾向スコア法は、このような選択バイアスを低減するために、介入群と対照群の属性を統計的に調整し、両群をできるだけ比較可能な状態に近づけることで、因果推論の妥当性を高めるための分析手法です。
傾向スコアとは
傾向スコア(Propensity Score)とは、「ある個体が介入群に割り当てられる確率(スコア)」です。
傾向スコアは0から1の範囲をとり、0に近い場合は対照群に入りやすく、1に近い場合は介入群に入りやすい特徴を持っています。
観察データでは、介入群と対照群の属性が偏ることで、処置とアウトカムの両方に影響する交絡因子が存在する可能性があります。例えば、薬を服用する人は、服用しない人に比べて年齢が高く、持病を抱えている場合が多い傾向があります。
このような背景の違いを考慮せずに薬の効果(アウトカム)の平均を直接比較すると、本来知りたい薬そのものの効果ではなく、年齢や健康状態といった交絡因子の影響を含んだ差を測ってしまい、処置効果を過大または過小に評価してしまう可能性があります。
そこで、傾向スコアを推定し、介入群と対照群のスコアが重なる範囲に注目します。この「両群に共通して観測されるスコア範囲」を共通サポートと呼びます。共通サポートが十分に存在する領域に限定して比較することで、似た属性を持つ個体同士の比較が可能になります。
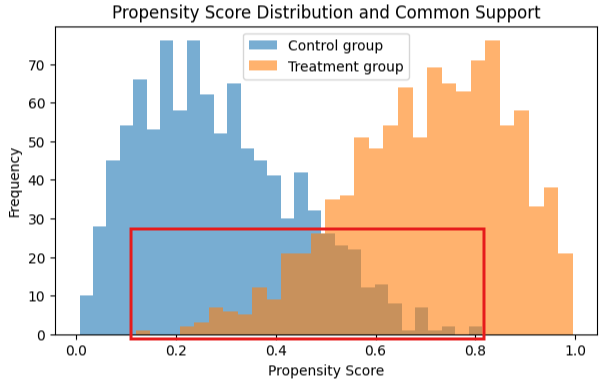
傾向スコアを用いることで、処置の有無と結果の両方に影響を与えて観測結果をゆがませる要因である交絡の影響を緩和しながら、RCTに近い条件で処置効果を推定することができます。傾向スコアは、年齢・性別・収入などの共変量を説明変数とし、「処置を受ける確率」を目的変数とする統計モデルによって推定されます。
代表的な手法は以下の通りです。
ロジスティック回帰による傾向スコア推定
ロジスティック回帰を用いると傾向スコア\(e(x) \) は、次の式で計算されます。
$$
e(x) = \frac{1}{1 + \exp\left( -(\beta_0 + \beta_1 x_1 + \cdots + \beta_p x_p) \right)}
$$
ロジスティック回帰では、係数\(\beta\)や統計量に注目することもありますが、傾向スコア推定においては、各個体が介入群に割り当てられる「予測確率」が重要であり、この予測確率が傾向スコアになります。
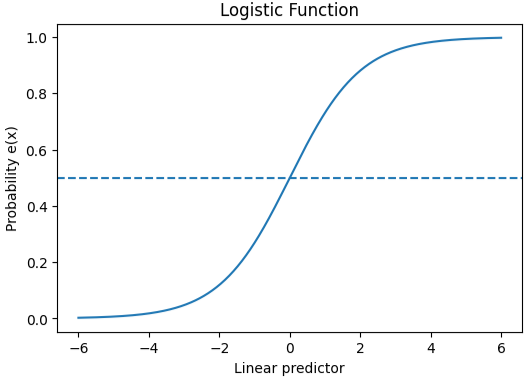
傾向スコア\(e(x)\)は0から1の範囲の値をとりますが、ロジスティック関数の性質上、傾向スコアが0や1に近い領域では、線形予測子(共変量の重み付け合計)の変化に対する確率の変化は小さく、0.5 付近では変化が大きくなります。そのため、分布や群間の重なりをより正確に確認する際には、傾向スコアをロジット値(オッズの対数)に変換することがあります。
ロジットは次のように定義されます。
$$
logit(e(x)) = log(\frac{e(x)}{1-e(x)})
$$
このようにロジット変換をおこなうことで、非線形性が緩和され、傾向スコアの分布や群間の重なりを直感的に把握しやすくなります。
重要な注意点として、傾向スコアの推定(ロジスティック回帰など)では、一般的な機械学習モデルのような「予測精度(正解率やAUC)の高さ」が必ずしも最優先されるわけではありません。機械学習の目的が「未知のデータに対して介入の有無を正しく当てること」であるのに対し、因果推論の目的は「介入群と対照群の背景因子(共変量)を均一に揃えること」にあります。
Data Analytics Magazine


「0,1判別」の定番手法!ロジスティック回帰分析とは? | Data Analytics Magazine
ロジスティック回帰分析は、特定の事象が発生する確率を推計する手法でビジネスシーンでも活用しやすい分析手法です。ロジスティック回帰分析の考え方や活用方法について解…
分類木による傾向スコア推定
分類木は、共変量をもとに「処置を受けるかどうか(0=対照群、1=介入群)」の目的変数を分類する木構造のモデルです。モデルの学習では、各分岐で「どの変数が処置の有無を最もよく分けるか」を繰り返し判定していきます。その結果として、各個体が属する葉ノードにおける介入群の割合を「処置を受ける確率」として解釈することで、傾向スコアを推定することができます。
分類木の特徴として、ロジスティック回帰のように線形性を仮定しないため、変数同士の複雑な交互作用や、特定の値を境に処置の有無が変わるような閾値効果も自然に扱うことができます。一方で、単一の木は過学習を起こしやすいため、後述の勾配ブースティングなどのアンサンブル手法を使うことで、より安定した傾向スコア推定が可能になります。
勾配ブースティングは、分類木を多数組み合わせて予測精度を高めるアンサンブル学習手法です。複数の弱い分類木を順に学習させ、前の木の誤差を次の木が補正する形でモデル全体を改善していきます。
多数の木を組み合わせることで、単一の決定木よりも精度が高く安定した推定が可能であり、学習率や木の深さなどを調整することで、汎化性能を高められることが特徴的です。
Data Analytics Magazine

決定木分析(デシジョンツリー)とは?ビジネス活用や注意点を解説 | Data Analytics Magazine
決定木分析は、使用できるデータの柔軟性や結果の見やすさから多くのビジネスシーンで活用されてきた分析手法の一つです。決定木分析の考え方や活用方法について解説します…
お気軽にご相談ください!
当サイトの運営会社であるデータアナリティクスラボ株式会社は、データサイエンティストのプロフェッショナルサービスを提供しています。因果推論をはじめとした各種手法を用いた分析実績も多数ございますので、お気軽にご相談ください。
ご相談・お問い合わせはこちらから
傾向スコアを用いた手法の紹介
傾向スコアは先述したように推定されますが、推定しただけでは因果効果を評価できません。重要なのは、このスコアを使って介入群と対照群を「公平に比較できる状態」に整えることです。ここでは、代表的な3つの手法「マッチング」「層別化」「逆確率重み付け」を紹介します。
マッチング
マッチングは、推定した傾向スコアに基づき、スコアが近い個体同士を対応づけて比較する方法です。似た特徴をもつ個体同士の比較になるため、交絡の影響を減らすことができます。
マッチングはペアの組み方や、マッチングの条件設定によって分析に利用される個体がどの程度残るかといった違いにより、さらに手法が細分化されます。代表的なアプローチとして「最近傍マッチング」「キャリパーマッチング」「最適マッチング」の3種類があります。
マッチングのアプローチを選択するにあたり、共通して以下の2つを事前に決める必要があります。
対応比
1人の介入個体に対して、何人の対照個体を割り当てるか
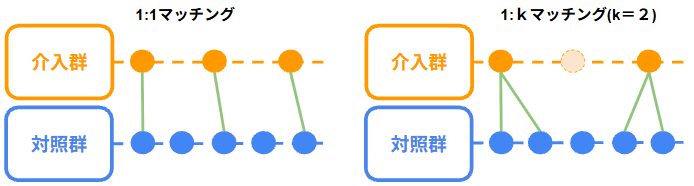
- 1対1マッチング
最も近い対照を1人と比較- メリット:バランスが取りやすく、バイアスが小さくなりやすい
- デメリット:サンプル数が減りやすく、推定の精度が下がる可能性がある
- 1対kマッチング
近い対照をk人集め、平均(単純平均 または 加重平均)で比較- メリット:より多くのデータを利用でき、推定の安定性が向上する
- デメリット:傾向スコアが遠い対照個体が含まれ、バランスが悪化する可能性がある
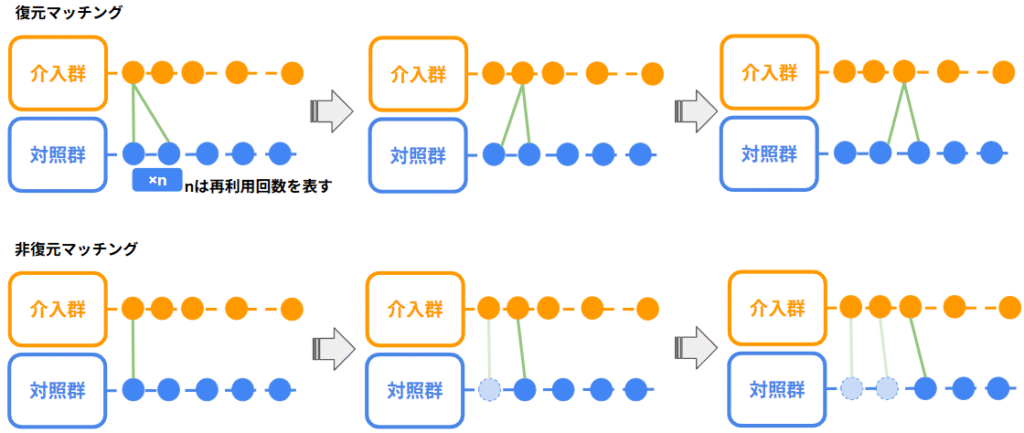
復元の有無
対照個体の再利用を許す場合と許さない場合
- 復元マッチング
同じ対照個体を複数の介入個体に対して繰り返し使用- メリット:最も近い対照個体を何度でも使えるため、マッチング精度が高い
- デメリット:特定の対照個体に依存しやすく、分散が大きくなる可能性がある
- 非復元マッチング
一度マッチに使用した対照個体は、それ以降のマッチングには使用しない- メリット:対照個体が均等に利用され、推定の安定性が高い
- デメリット:後半のマッチングで適切な対照が見つからない可能性がある
これらの前提知識を踏まえ、具体的なマッチングアプローチ(最近傍、キャリパー、最適)がどのように機能するのかを、簡単なデータ例を用いて確認してみます。
以下のデータを用いて、3種類の方法でマッチングを実施します。

最近傍マッチング
介入群の各個体に最も近いスコアの対照群を割り当てます。介入群の傾向スコアの一番大きい値である0.90(または一番小さい値である0.63)からマッチする値を見つけます。

非復元マッチングの場合、対照群の0.41と0.39は未使用となります。
復元マッチングの場合、対照群の傾向スコアが0.65の個体は、介入群の傾向スコアが0.67のと0.63の個体に2回選択されるため、対照群で除外される個体は、傾向スコアが0.39, 0.41, 0.59の3個体となります。
キャリパー制約付きマッチング
キャリパーマッチングは、介入群と対照群の傾向スコアの差が、あらかじめ設定した許容範囲(|スコア差| ≦ 閾値(キャリパー))以内にある場合のみペアを組む方法です。この方法では、傾向スコアが大きく離れた個体はマッチされないため、すべての介入群の個体に対応する対照群が見つかるわけではありません。マッチ数は減少しますが、選ばれたペアはより傾向スコアが近い個体同士となり、共変量のバランスが改善されやすいという特徴があります。
キャリパー幅は、以下の式で求めることができます。
$$
b = 0.25 \times SD(logitPS)
$$
- \(SD(logitPS)\):ロジット変換後の傾向スコアの標準偏差
- \(0.25\):キャリパー幅を決定する係数 ※実務では0.2~0.25などの経験則で設定されることが多い
例えば、\(SD(logitPS)\) = \(0.2\)の場合、キャリパー幅は以下のようになります。
$$
b = 0.25 \times 0.2 = 0.05
$$
この場合、全ての介入群の個体に対して、キャリパー内に対照群の個体が存在するため、介入群はすべてマッチングされます。一方で、対照群の0.41と0.39は、いずれの介入群個体ともキャリパー内に存在しないため、未マッチとなります。1:kや復元ありにした場合でも同様であり、キャリパー外の個体は採用されないため、0.41と0.39は未マッチのままとなります。
さらに、キャリパー幅を0.03とした場合には、傾向スコア差が「b=0.05(0.90, 0.85)」や「b=0.04(0.63, 0.59)」となるペアは、いずれもキャリパー幅を超えるため、マッチングされません。
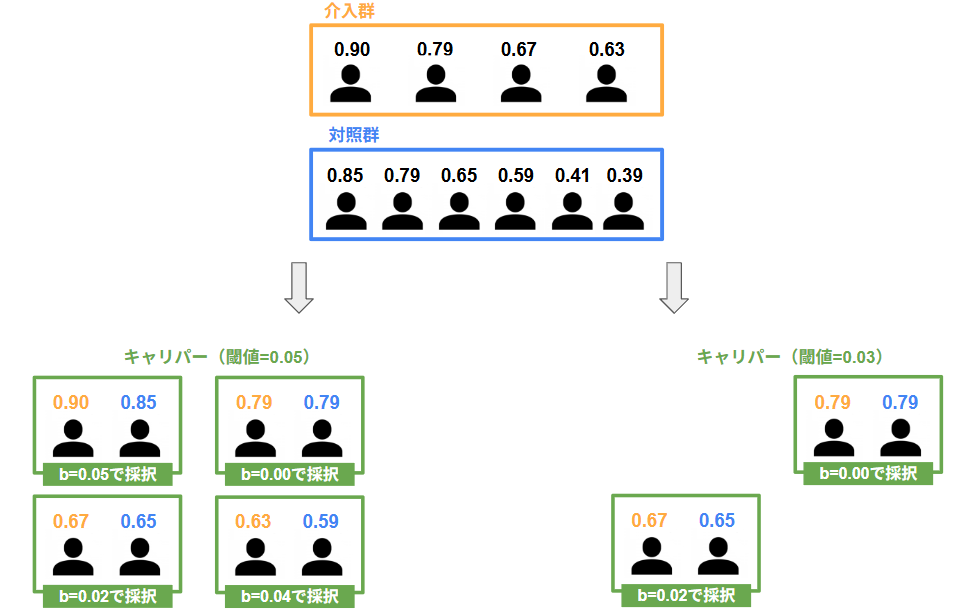
なお、キャリパーが決めるのは「マッチングしてよい候補(許可されたペア)」の集合だけであり、キャリパー内=必ずマッチする、という意味ではありません。実際にどのペアが組まれるかは別フェーズでおこなわれ、「復元あり/復元なし」や「割り当ての順番(並び順)」といったルールによって最終結果が決まります。
例1:キャリパー幅が「b=0.05」で復元ありの場合
・介入群 0.67 は、対照群 0.65 とマッチ可能
・介入群 0.63 も、対照群 0.65 とマッチ可能
どちらの介入個体も 0.65 に最も近く、また差もどちら0.02 と 0.04のため、両方キャリパー内となり、マッチ可能です。
例2:キャリパー幅が「b=0.05」で復元なしの場合
・介入群 0.67 は、対照群 0.65 とマッチ可能
・介入群 0.63 は、対照群 0.65とキャリパー内にあるが、既に割り当てられているため、マッチ不可
つまり、キャリパー内でも、相手の取り合いでマッチできないことがあります。
最適マッチング
最適マッチングは、すべての介入群と対照群の組み合わせを考慮し、マッチングされたペア全体のスコア差の合計が最小になるようにペアを決定する方法です。最近傍マッチングは「近い相手を順に取っていく(局所最適)」という考え方ですが、最適マッチングは「全体の距離の総和が最小になるように組み合わせを選ぶ(全体最適)」点が異なります。
距離=|介入個体のPS-対照個体のPS|
| 対照 0.85 | 対照 0.79 | 対照 0.65 | 対照 0.59 | |
| 介入 0.90 | 0.05 | 0.11 | 0.25 | 0.31 |
| 介入 0.79 | 0.06 | 0.00 | 0.14 | 0.20 |
| 介入 0.67 | 0.18 | 0.12 | 0.02 | 0.09 |
| 介入 0.63 | 0.21 | 0.16 | 0.02 | 0.04 |
この例では、距離の総和が 0.05 + 0.00 + 0.02 + 0.02 = 0.09 となる組み合わせが最適解となります。
今回の例は、復元ありマッチングを想定しているため、同一の対照個体(PS = 0.65)が複数の介入個体に割り当てられています。非復元マッチングの場合は、対照個体を重複して使用できないため、最小化できる距離の総和は0.11となります。
このように最適マッチングでは順番に依存しないため、もしスコアの近い相手が複数存在する場合でも、全体の距離を最も小さくする組み合わせを自動的に選び出すことができます。
層別化
層別化は、全ての個体における傾向スコアを推定し、その値に基づいてデータをいくつかの層に分割する方法です。各層内では、介入群と対照群の平均値の差を算出し、層のサイズに応じた重み付け平均をとることで、全体のATEまたはATTを推定します。
層を作る際の区切り方には、主に2つの方法があります。
- 等区間分割:傾向スコアの値そのものを一定幅(「0.00〜0.25」)で均等に区切る方法
- 等割合分割:個体数が各層で均等になるように分ける方法
まずは5層(五分位)に分けるのが古典的な出発点で、共変量のバイアスを大きく減らすことができるとされています。層別化では「各層に介入群と対照群の両方が存在すること」が重要ですが、層を増やしすぎてしまうと、一部の層で個体数が少なくなったり、どちらかの群が欠けてしまうことがあります。そのような場合は、隣り合う層を統合したり、共通サポートの外とみなして対象外にする対応が必要です。
| 層 | 区間 | 介入群 | 対照群 |
| 1 | 0.00以上 0.25未満 | – | – |
| 2 | 0.26以上 0.50未満 | – | 0.39, 0.41 |
| 3 | 0.51以上 0.75未満 | 0.63, 0.67 | 0.59, 0.65 |
| 4 | 0.76以上 1.00以下 | 0.79, 0.90 | 0.79, 0.85 |
| 層 | 区間 | 介入群 | 対照群 |
| 1 | 0%以上 25%未満 (0.000以上 0.230未満) | – | – |
| 2 | 25%以上 50%未満 (0.230以上 0.455未満) | – | 0.39, 0.41 |
| 3 | 50%以上 75%未満 (0.455以上 0.688未満) | 0.63, 0.67 | 0.59, 0.65 |
| 4 | 76%以上 100%以下 (0.688以上 1.000以下) | 0.79, 0.90 | 0.79, 0.85 |
用語解説
- ATE(平均処置効果)
- 母集団に対する平均的な介入効果
- ATT(介入群平均効果)
- 実際に介入を受けた集団(介入群)に対する平均的な介入効果
逆確率重み付け(IPTW)
逆確率重み付けは、傾向スコアを用いて、各個体に重みを付与し、処置割り当てが仮想的にランダムであったかのような母集団を構成する手法です。これにより、交絡の影響を補正したうえで、介入群と対照群の平均を公平に比較することが可能になります。
例えば、教育支援プログラムの効果を評価したい場合を考えます。
支援を受けた学生は、もともと学習意欲が高かったり、家庭の教育支援が手厚い可能性があります。一方、支援を受けなかった学生は、家庭環境の制約などにより、もともと進学しにくい背景を持っているかもしれません。
このような背景の偏りを考慮せずに単純に進学率を比較すると、家庭環境の差まで教育支援プログラムの効果として誤って評価してしまう可能性があります。
そこで家庭環境の偏りを補正するため、逆確率重み付けをおこないます。
逆確率重み付けでは、各個体に次のような重みを付与します。
- 介入個体(\(Ti=1\))
$$
wi = \frac{1}{e(xi)}
$$
- 対照個体(\(Ti=0\))
$$
wi = \frac{1}{1-e(xi)}
$$
この重み付けにより、本来は処置を受けにくいにもかかわらず実際には処置を受けた個体には大きな重みが与えられます。同様に、処置を受けやすいにもかかわらず処置を受けなかった個体にも大きな重みが与えられます。この重み付けをおこなうことで、すべての個体が同じ確率で処置を受けるような仮想的な状況を再現することができます。
このように、「その属性(背景)で見れば処置を受けるのが珍しいケース」ほど高く評価することで、属性による偏りを相殺します。この重み付けをおこなうことで、すべての個体が背景因子によらず等しい確率で処置を受けるような、共変量のバランスが取れた仮想的な状況(疑似集団)を再現することができます。
構成された疑似集団では、介入群と対照群の間で共変量のバランスが取れた状態となります。これにより、観察データでありながらランダム化比較試験(RCT)に近い状況を再現でき、選択バイアスを排除した平均処置効果(ATE)の推定が可能になります。
ビジネス活用シーン
ここまでで、RCTを実施できない観察データに対して、傾向スコアを用いた因果推論の考え方について説明しました。ここからは、その中でも代表的な手法である傾向スコアマッチングに焦点を当て、具体的なビジネスシーンでの活用例を紹介します。
本事例では、「サプリメントを摂取したことによって血圧は改善したのか?」という問いを題材に、傾向スコアマッチングを用いた因果推論をおこないます。
今回使用するダミーデータは、健康診断・生活習慣に関する観測データです。このデータは実験データではなく、各個人が自発的にサプリメントを摂取しているため、摂取有無はランダムではありません。
- 処置変数(T)
- サプリメント(1= 摂取あり、0= なし )
- 共変量(X)
- 性別
- 年齢
- 体脂肪量(BFM)
- 骨格筋量(SMM)、BMI
- アウトカム(Y)
- 一週間の血圧変化量
STEP
傾向スコアの推定
性別・年齢・体脂肪量・骨格筋量・BMIを用いて「その人がサプリを摂取する確率(傾向スコア)」をロジスティック回帰で推定します。
STEP
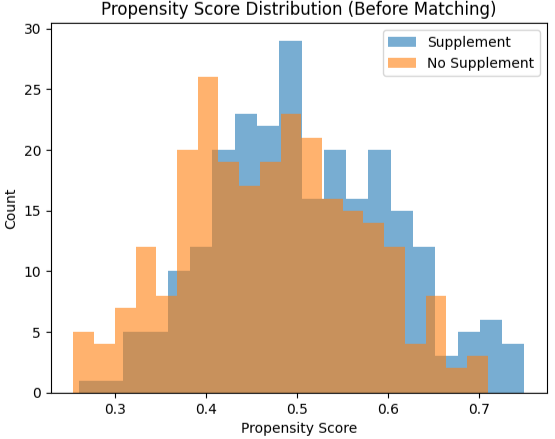
傾向スコア分布の確認(マッチング前)
マッチング前では、両群の傾向スコア分布にズレがあり、背景が異なる集団であることがわかります。
STEP
最近傍マッチング(1:1 / 非復元)
本例では、解釈をシンプルにするため、1人の介入個体に対して最も傾向スコアが近い1人の対照個体を割り当てる1:1の非復元最近傍マッチングを採用しました。
STEP
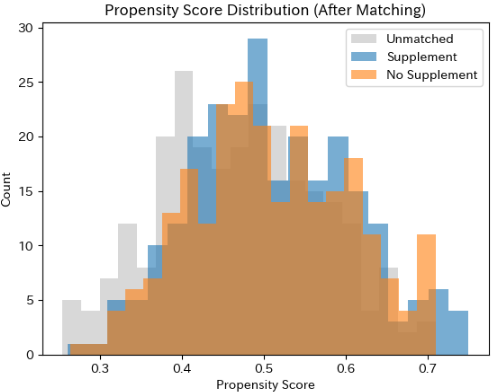
マッチング後の分布確認
マッチング後には、両群の傾向スコア分布の重なりが改善していることが確認できます。
STEP
共変量バランスの確認(Love plot)
マッチング前は一部の共変量でSMD(標準化平均差)が大きかったが、マッチング後には多くの共変量でSMDが0.1前後まで改善し、背景条件のバランスが大きく改善していることが確認できます。SMDは、介入群と対照群の共変量分布の差を尺度に依存せずに比較できる指標です。
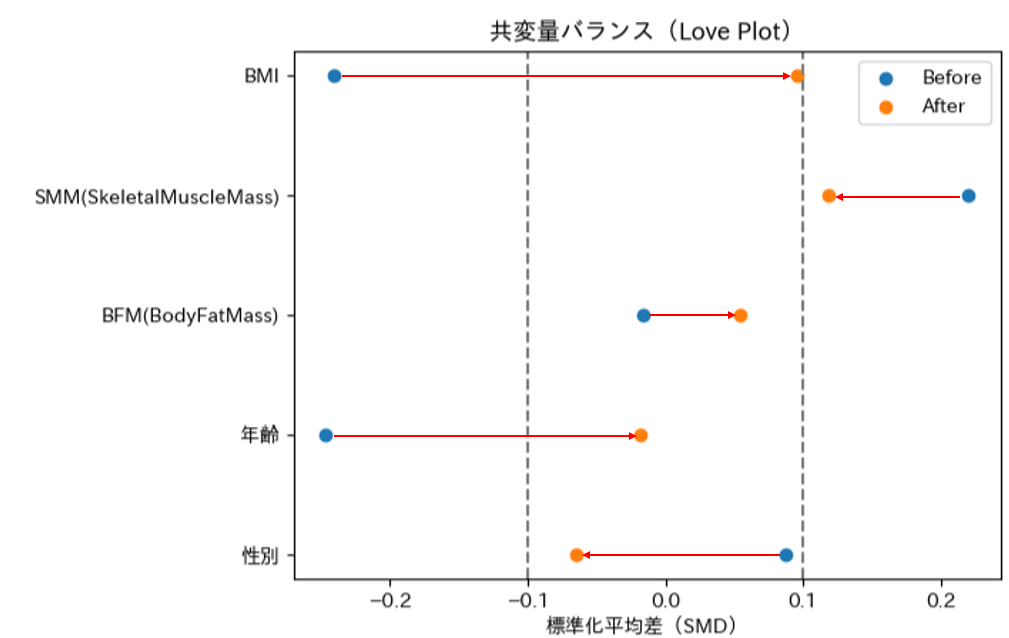
STEP
効果推定(ATT)
$$
\hat{ATT}
=
\frac{1}{N_T}
\sum_{i:T_i=1}
\left(
\text{血圧改善量}_{i,\ supplement}
–
\text{血圧改善量}_{j(i),\ no\ supplement}
\right)
$$
ATT = 2.72
サプリを摂取した人において、摂取しなかった場合と比べて、血圧の改善量が平均で約2.7大きいと推定されます。
STEP
(参考)IPTWによる効果推定
$$
\hat{ATE}_{IPTW}
=
\frac{\sum_{i=1}^{N} \frac{T_iY_i}{e(X_i)}}{\sum_{i=1}^{N} \frac{T_i}{e(X_i)}}
–
\frac{\sum_{i=1}^{N} \frac{(1-T_i)Y_i}{1-e(X_i)}}{\sum_{i=1}^{N} \frac{(1-T_i)}{1-e(X_i)}}
$$
- \(e(X_i)\) :個体 \(i\) の傾向スコア(サプリ摂取確率)
IPTW ATE ≒ 2.82
参考として、同じデータに対して逆確率重み付けでATEを算出したところ、推定された効果はATTと近い値でした。共変量で補正した仮想的な母集団において、サプリ摂取は血圧の改善量を平均して約2.8増加させる効果があると推定されます。
本例では、サプリ摂取の効果を単なる相関ではなく、因果効果として評価できた点がポイントです。このように、マーケティング施策・健康施策・価格施策など、「施策を受けた人・受けなかった人」を比較する多くのビジネス場面で応用できます。
お気軽にご相談ください!
当サイトの運営会社であるデータアナリティクスラボ株式会社は、データサイエンティストのプロフェッショナルサービスを提供しています。因果推論をはじめとした各種手法を用いた分析実績も多数ございますので、お気軽にご相談ください。
ご相談・お問い合わせはこちらから
注意点
傾向スコア法は観察データから因果効果を推定する有用な手法ですが、適用にあたってはいくつかの前提条件や注意点を理解しておく必要があります。ここでは、傾向スコア分析を実務で適用する際に重要となるポイントを整理します。
1. 傾向スコア分析の前提と限界
1-1. 共通サポート
観測可能な共変量で傾向スコアを適切に推定しても、介入群と対照群の傾向スコア分布に十分な重なり(=共通サポート)がない場合、比較可能な集団を作ることができません。共通サポートが乏しいと、極端な傾向スコアを持つ個体が除外されやすくなり、結果として「平均的な個体」だけに基づく推定となり、元の母集団の多様性を反映できなくなります。
例えば、治療Aの効果を全患者に対して評価したいにもかかわらず、傾向スコアが重なっている中年層のみがマッチされ、若年層や高齢層が除外されてしまいます。この場合、推定された効果は「中年層に対する治療効果」であり、全患者に対する効果とは限りません。
1-2. 共変量バランスの確認
傾向スコアを用いた調整(マッチングや重み付け)の後は、群間で観測された共変量のバランスが取れているかを評価する必要があります。
共変量バランスは、SMDを用いて評価されます。共変量バランスとは、介入群と対照群の共変量分布がどれだけ似ているかを示す概念であり、バランスが取れているほど群間の交絡が小さいと考えられます。一般的に、SMDが 0.1 以下であれば、その共変量については群間で十分にバランスが取れていると判断されます。
1-3. 未観測交絡
未観測交絡が存在する場合には、傾向スコアを用いてどれだけ調整しても、因果推定にバイアスが残る可能性があります。未観測交絡とは、傾向スコア推定モデル(ロジスティック回帰や分類木など)に含めることができていないにもかかわらず、処置の割り当てとアウトカムの両方に影響する要因を指します。
例えば、データ上では観測できていない「健康意識」が、治療の受けやすさと回復のしやすさの両方に影響しているケースを考えます。「健康意識が高い人ほど自ら進んで治療を受け(処置)、かつ普段から不摂生をしないため回復も早い(アウトカム)」という構造がある場合、治療そのものの効果が実際よりも大きく見積もられてしまう(過大評価)といったバイアスが生じます。
このような未観測交絡の影響を完全に排除することは難しいため、推定結果が未観測要因にどの程度影響を受ける可能性があるかを評価する「感度分析(Sensitivity Analysis)」がおこなわれることがあります。感度分析とは、分析に含まれていない潜在的な交絡要因が存在した場合に、推定された因果効果がどの程度変化する可能性があるかをシミュレーションなどによって検証する手法です。
2. 手法選択のトレードオフ
傾向スコアを用いた因果推論の手法(マッチング、逆確率重み付けなど)を選択・設定する際に最も重要なのは、「バイアスの低減」と「分散増大」のトレードオフをどう調整するかです。
2-1. マッチングにおけるトレードオフ
非復元マッチングや厳しすぎるキャリパーの設定をすると、傾向スコアが非常に近い個体だけが残るため、群間のバイアスは大きく低減できます。一方で、その代償として多くの個体がマッチされずに除外され、以下の問題が生じます。
- 分散の増大:有効サンプルサイズが減り、推定値が不安定になる
- 検出力の低下:分散が大きくなるため、有意差を検出しにくくなる
- 外的妥当性の低下:残った標本が偏り、結果の一般化可能性が下がる
そのため、実務では「復元マッチング」や「1:kマッチング」を採用し、キャリパーも0.2×SD(logitPS)程度から調整するなど、バイアスの低減と情報量確保のバランスをとることが重要です。
2-2. 逆確率重み付け(IPTW)のトレードオフ
逆確率重み付けは、原理上はすべての標本を広く活用し、バイアスを低減しやすい手法です。一方で、以下のような問題が生じることがあります。
- 傾向スコアが0や1に近い個体が存在すると、その個体に極端な重みが付与される
- その結果、推定が不安定になり、標準誤差が増大(分散が増大)しやすくなる
上記の問題を解決するため、重みの上限を設定(トリミング)や極端な傾向スコア(共通サポート外)を除外、傾向スコアモデルの改善(変数やモデリング手法の見直し)などがおこなわれます。このようにすることで、逆確率重み付けの「バイアス低減能力」を生かしつつ、「分散の増大」を抑えることができます。
Data Analytics Magazine

因果フォレストとは?概要とビジネス活用例を徹底解説! | Data Analytics Magazine
因果フォレストは、異質性を分析する手法です。誰に・どのくらい施策が効果的かわかるので、マーケティングなどで活用されています。本記事は、因果フォレストについて解説…
まとめ
傾向スコア分析とは、観察データの偏りをできるかぎり取り除き、より公平に効果を比較するための手法です。
マッチングや重み付けなど目的に応じた使い方ができ、実務でも幅広く応用できます。
ぜひ、これらの方法を使って「もしランダムに割り付けられていたら」という視点をデータで再現してみてください。
お気軽にご相談ください!
当サイトの運営会社であるデータアナリティクスラボ株式会社は、データサイエンティストのプロフェッショナルサービスを提供しています。因果推論をはじめとした各種手法を用いた分析実績も多数ございますので、お気軽にご相談ください。
ご相談・お問い合わせはこちらから
こちらもご覧ください



データアナリティクスラボ
データアナリティクスラボ
Journal | データアナリティクスラボ
JOURNALについて データアナリティクスラボ株式会社では、ITやデータサイエンスに関する技術の研究活動を行っています。このブログでは、研究活動で得られた知見や検証結果…









