
Index
1. はじめに
データアナリティクスラボ株式会社 データソリューション事業部の佐藤です。
今回は弊社の研修の技術習得の一環として、私は以前から注力していた「衛星データ(衛星画像)×深層学習」をテーマに本記事を執筆いたしました。
本記事では衛星データについての概要と、深層学習(CNN)を用いた衛星画像からの道路網抽出タスク及びその技術トピックについて説明いたします。
なお、本記事における道路網抽出タスクの検討にあたっては、Ayala ら(2021)による既存研究を主な参考文献の一つとしています。特に、10m 解像度画像から高解像度な道路マップを生成するという課題設定や、高解像度化のためのモデル設計に関する考え方は、本記事における技術検証の出発点となっています。
2. 衛星データの概要
「衛星データ」という言葉は一般的にも広く浸透していますが、本記事で扱うデータが具体的にどのような性質を持つのかを改めて説明します。
一般的に衛星データとは、人工衛星に搭載されたセンサーが取得した観測データを指します。その中でも今回は、可視光(RGB)などの波長帯を観測して生成される画像データに着目します。
これらの画像データは「ラスターデータ」と呼ばれ、格子状に並んだ最小単位であるピクセルごとに数値情報が格納されています。拡大すると格子状の境界(ジャギー)が顕著になるのが特徴です。これとは対照的に、点・線・面といった幾何学的な数値として形状を表現する形式を「ベクターデータ」と呼びます。
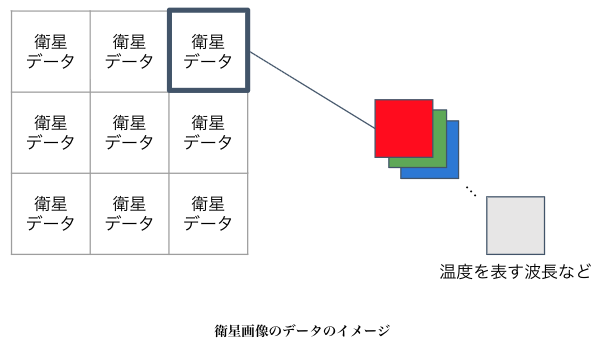
ただし、画像のようなラスターデータは衛星データの一側面に過ぎない点には注意が必要です。実際には、地表面温度、標高、植生指数、あるいはレーダーによる観測値など、さまざまな物理量が含まれます。そのため、衛星データは単なる画像ではなく、地球の状態を多角的に捉えるセンサーデータの集まりと理解するのが適切です。
また、衛星データ活用の大きな利点として、無償で利用可能なオープンデータが豊富であることが挙げられます。代表的な例として、欧州宇宙機関(ESA)が運用する「Sentinel-2」があります。こちらの衛星のデータは、高頻度かつ高解像度な観測データとして世界中で広く活用されており、研究開発やプロトタイプ作成において非常に強力なリソースです。以下の図はこちらの衛星が提供する観測データについてまとめたものです。
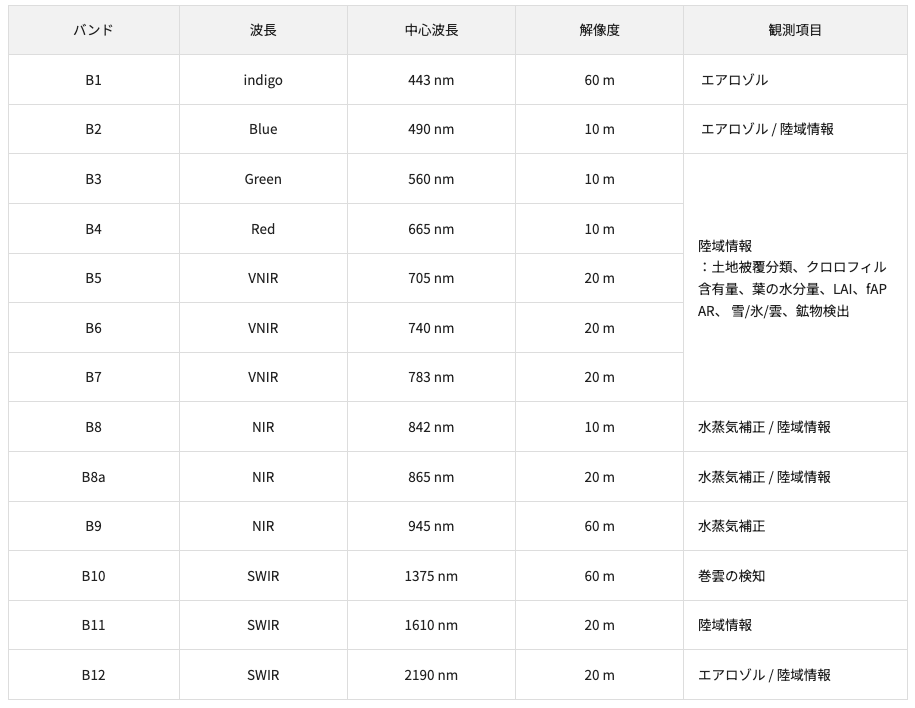
衛星データにおいて「バンド」とは、観測する周波数帯・波長帯の区分を指します。各衛星には観測可能なバンドが規定されており、それによって取得できる情報の種類が決まります。例えば、Sentinel-2において可視光(RGB)に対応するバンド(B4, B3, B2)を選択した場合、10m×10mの解像度でデータを取得することが可能です。ピクセルがカバーする面積が小さいほど高解像度なデータとなりますが、高解像度化には以下のようなトレードオフが伴います。
- 観測範囲の限定: 解像度が高まるほど、一度に撮影できる範囲は狭くなる傾向にある。
- コスト: 数十センチ単位の極めて高い分解能を持つデータは、一般的に有償で提供されることが多く、広域の解析においてはコストが大きな障壁となる。
したがって、解析の目的に応じて「無償で広域をカバーできる中解像度データ」か「有償だが詳細な判読が可能な高解像度データ」かを選択する、適切なデータ選定の視点が不可欠です。
3. 道路網抽出タスクの目的
ここでは衛星画像から道路網を自動抽出する技術が、具体的にどのような課題解決に寄与するのか、代表的な2つの活用シーンを挙げます。
- 災害時の迅速な状況把握
- 地震や豪雨災害時には、倒木や土砂崩れにより現地への物理的なアクセスが困難な場合があります。衛星画像から「通れる道・通れない道」を即座に解析できれば、以下の対応が可能になります。
- 救援ルートの確保:救急車両が通行可能なルートを瞬時に特定する
- 孤立集落の発見:道路が寸断され、支援が届かない地域を早期に発見する
- 地震や豪雨災害時には、倒木や土砂崩れにより現地への物理的なアクセスが困難な場合があります。衛星画像から「通れる道・通れない道」を即座に解析できれば、以下の対応が可能になります。
- 地図情報の自動更新
- 発展途上国では、地図データ(OpenStreetMap等)の更新が追いつかず、実際の道路状況と一致しないことがあります。高頻度で撮影される衛星画像とAIによる自動マッピング技術を組み合わせることで、以下のメリットが生まれます。
- 最新地図の維持:低コストで常に最新の道路情報を反映できる
- 未踏地域のマッピング:地図が整備されていない地域でも道路網を抽出できる
- 発展途上国では、地図データ(OpenStreetMap等)の更新が追いつかず、実際の道路状況と一致しないことがあります。高頻度で撮影される衛星画像とAIによる自動マッピング技術を組み合わせることで、以下のメリットが生まれます。
詳細には、異常検知課題として使用する手法を変えたりすることなどが別途考えられますが、道路網抽出タスクは道路の状況を広域で把握し、災害対応や都市計画などに利用できる情報を提供するなど、多角的な社会実装の可能性を秘めています。
4. 道路網抽出タスクにおける技術課題解決のための手法
今回の道路網抽出のタスクでは、衛星画像特有の性質に起因するいくつかの検討事項があります。ここでは、まずタスクの定義を明確にした上で、直面する課題とその解決方針について記述します。
4.1. タスクの定義
今回行うタスクは、「10m解像度の衛星画像から、道路網を抽出する2値セマンティックセグメンテーション」です。
セマンティックセグメンテーションとは?
画像の1ピクセル単位で「ここは道路」「ここは背景」と色を塗るように判定しながらセグメンテーションしていく方法。道路のような定まった形状を持たないものに対しては、画素レベルで判定するセグメンテーションが必要。
4.2. 道路網抽出における特有の課題とアプローチ
4.2.1. 線の教師ラベルをどのように面の教師ラベルに変換するか
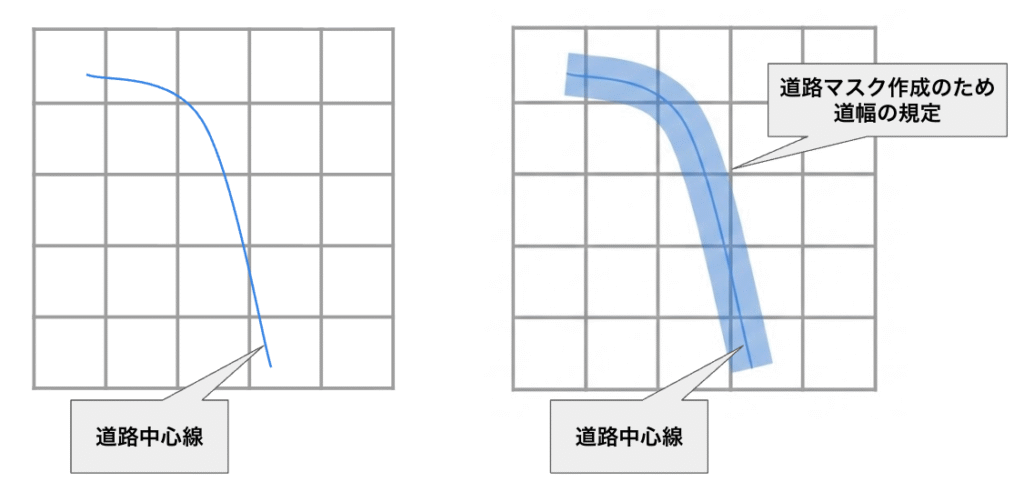
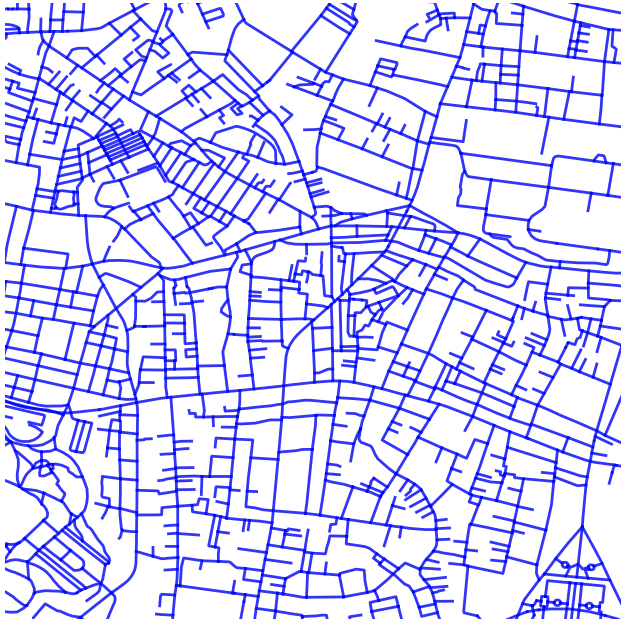
今回の道路網抽出における教師ラベルは、コンサベーションGISコンソーシアムジャパン様から提供いただいた、道路の中心線データから作成をしております。各道路に対して中心線のデータがマッピングされています。以下が可視化をしたものです。青いラインが道路の中心線を表していて、赤い線が道の縁を表しています。
⚠️地理的なデータ処理により、道路中心線の位置情報に若干のズレが生じる場合があります。また、道路中心線の対象となっていない道が存在します。
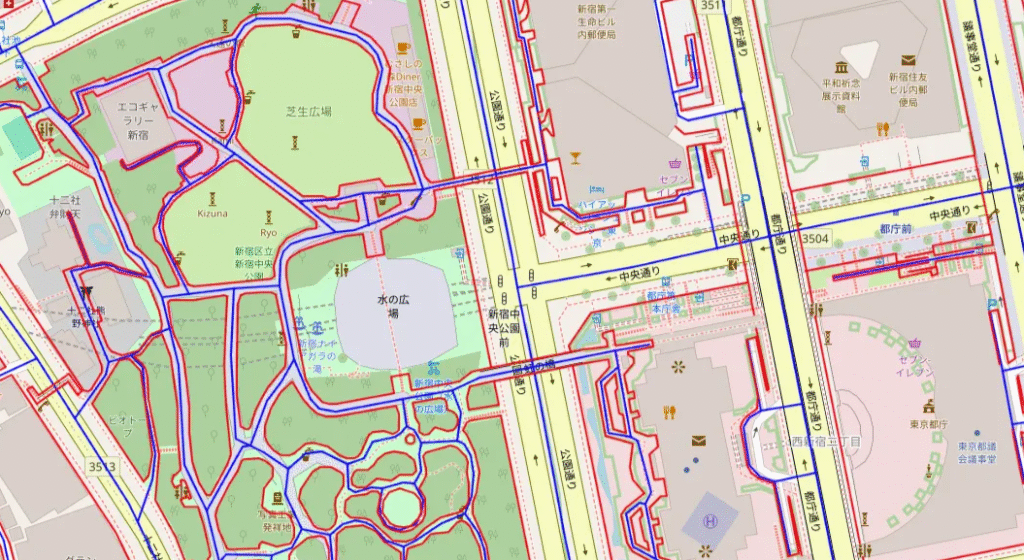
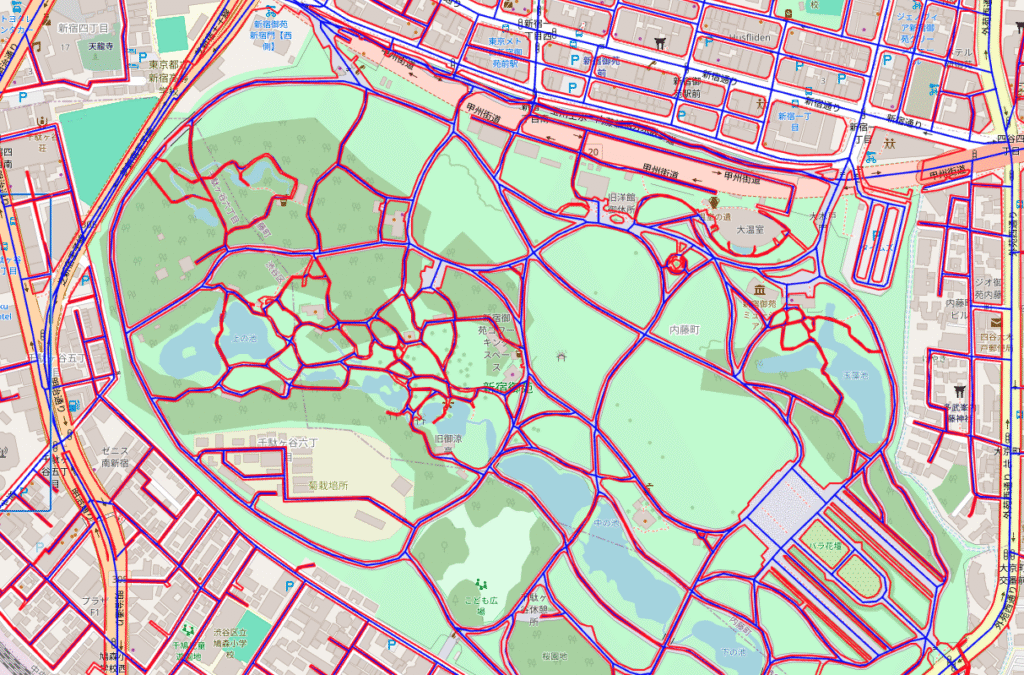
道路の中心線のデータのみでは、ピクセル毎に道路であるかどうかのラベルをつけることが難しく、面である道路のマスクをうまく表現できません。そのために、道路中心線を基準にして、ある程度の道路幅を設けたものを道路のマスクとします。しかし、かなり幅の広い道路もあれば、車1台がようやく通れるような狭い道路も存在するため、この幅をどう規定するか、というのが問題になってきます。
そこで今回は道路マスクの幅を、道路中心線データともに提供されている他データを利用して規定します。「vt_width」カラムを利用して各道路に対して道路幅を規定します。このカラムにはcm単位で道路幅が記入してあります。その幅を半分にしたうえで中心線を基準にしてマスク作成を行います。
▶道路中心線 他データ概要(CGISのサイトから引用)
- fid (INTEGER)
図形を一意に指す数値で連番。データ処理の関係上オリジナルデータと順番は一致しない。 - geom (MULTILINESTRING)
図形情報。この属性は編集できず、QGISの属性テーブルでは表示されない。 - vt_code (MEDIUMINT)
地物種別コード(2701-2734の値)。
例:2701(道路中心線通常部)、2711(2条道路中心線庭園路通常部)、2721(徒歩道通常部)など。 - vt_rdctg (Text)
道路分類。
属性値:国道、都道府県道等、市区町村道等、高速自動車国道等、その他、不明。 - vt_lvorder (MEDIUMINT)
道路の階層順(地図上における表示階層の順番)。0〜4の数値を取るが、殆どの場合0。 - vt_drworder (MEDIUMINT)
同一の階層順における描画優先順(高速道路、国道、都道府県道等の表示順序)。 - vt_rnkwidth (Text)
幅員区分。
属性値:3m未満、3m-5.5m未満、5.5m-13m未満、13m-19.5m未満、19.5m以上、その他、不明。 - vt_width (MEDIUMINT)
WEBMAP表示用の仮想的な幅員(実幅員とは異なる)。緯度によっても異なる。 - vt_tollsect (Text)
有料区分(無料、有料)。 - vt_motorway (MEDIUMINT)
自動車専用道路区分。
属性値:0(高速道路以外)、1(高速道路)、9(不明)。 - vt_flag17 (MEDIUMINT)
ズームレベル16と17での表示区分。
属性値:0(ズームレベル16を表示)、1(両方表示)、2(ズームレベル17を表示)。
マスク作成には大きく分けて2つの方法がありますが、今回は比較的小さい道路も拾え、道路の連結性をより考慮できる方法を採用しました。ただ、解像度が低い状態だと一つのピクセルに複数の道路の情報が重なってしまうことがあります。低解像度の際には気をつけるべき点であり、今回のような道路網マスク作成の障壁ともいえます。両者の違いについては「6.1. 検証①」で詳述します。
4.2.2. 道路構造の連続性の問題
道路網は、単なる領域の集合ではなく、相互に接続された構造を持っています。解析の実用性を考慮すると、道路が密集するエリアを漠然と道路領域として抽出するだけでは不十分です。個々の道路が網目状に分離・接続されている構造を正確に捉えなければ、ルート検索やインフラ管理といった後続のタスクに支障をきたします。
この網目構造をモデルに学習させるため、今回はDice LossとBCE(Binary Cross Entropy)を組み合わせた複合的な損失関数を採用しました。
Dice Lossは、対象領域の重なりを重視するため、道路のような細い対象の検出には有効です。一方で、過検出に対するペナルティが相対的に弱く、道路密集地を塗りつぶすような予測になりやすい傾向があります。
これに対してBCEは、各ピクセルごとの予測確率と正解ラベルのズレに応じて誤差を与えるため、過検出を抑えやすい特徴があります。ただし、構造の連続性そのものを直接は評価しないため、細い道路が途切れやすくなることがあります。
そのため、両者を組み合わせることで、道路の見逃しを抑えつつ、過剰な塗りつぶしも抑制することを狙いました。損失関数の内容と処理結果については「6.1. 検証②」で詳述します。
4.2.3. 解像度の壁
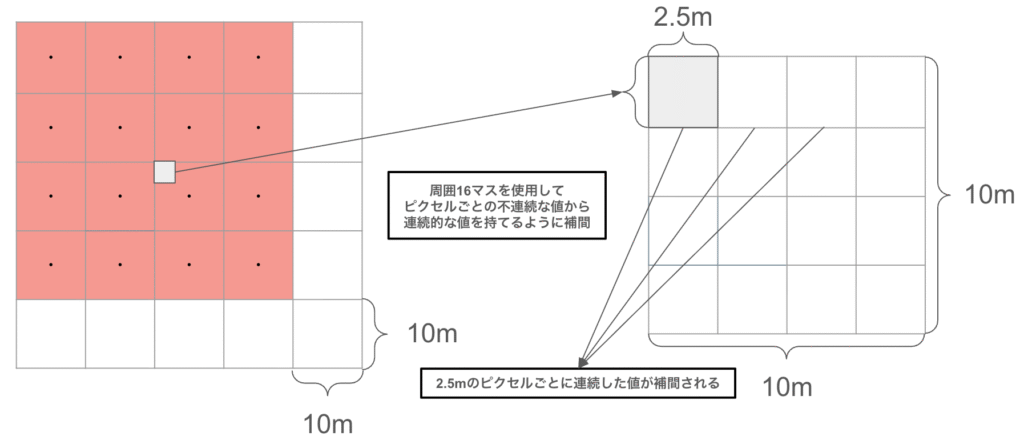
今回使用している画像は10m解像度の衛星画像です(図6)。入力が10m解像度で、出力も10m解像度である場合、評価を行う際のマスク画像において、複数の道路が1ピクセル内に混在し、ラベルが重複・干渉すると言う問題が避けて通れません(図7)。出力が2.5m解像度の道路ラベルの判定であれば、高精度な連結構造を把握できる解像度の高い道路マスク(図8)を使用して評価を行うことができます。

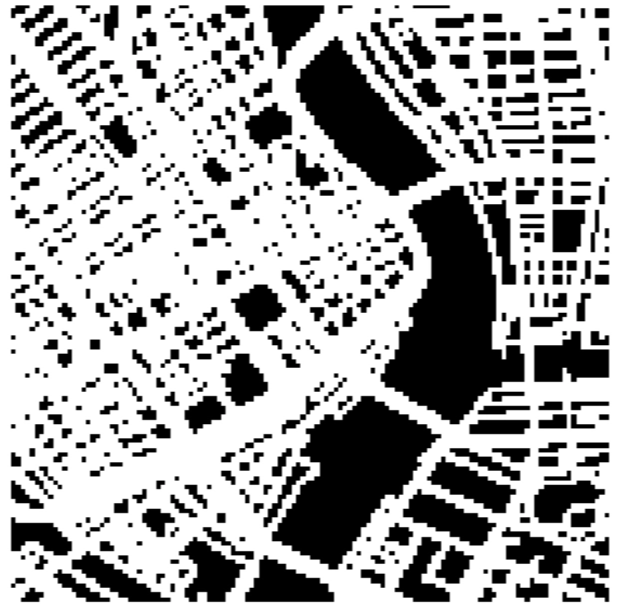
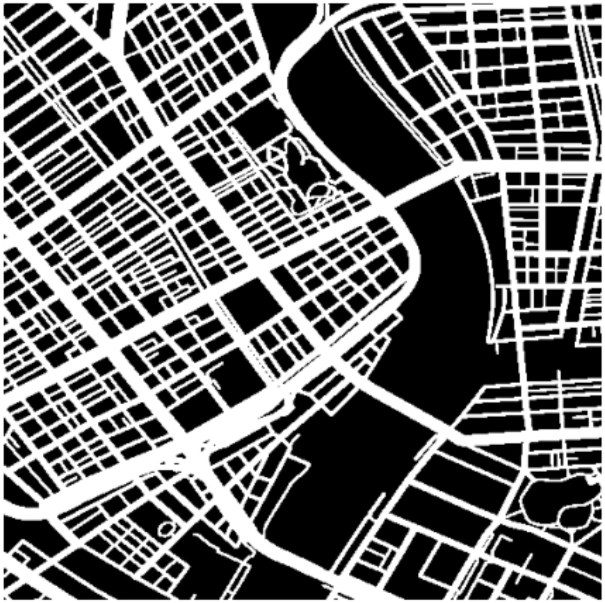
ではどうすれば、手元にある10m解像度の衛星画像から2.5m解像度の道路ラベル予測を作り出せるのでしょうか。これには、以下の2つの手法が提案できます。
手法1:
モデルの末尾(出力側)に畳み込み層とアップサンプリング層を追加で2段階配置し、10m解像度の特徴マップから2.5m解像度の予測を出力する。
手法2:
補間処理を利用して、入力画像を2.5m解像度にしたうえで、2.5m解像度の道路ラベル予測を出力する。
今回のモデルに使用するU-Netのアーキテクチャは後で詳述しますが、それぞれの手法の違いは、U-Netにおけるエンコーダとデコーダの畳み込みの回数が一致していて、強みであるスキップ接続を利用できているか、と言う点にあります。この違いが精度にどのような影響を与えるのかは「6.1. 検証③」で詳述します。
5. 実験設計
5.1. 想定課題
道路データがない地域において、衛星画像のみから未知の道路網の抽出を行う。つまり作成するモデルには、訓練データと地域が変わっても道路網の予測ができるような汎化性能が求められる。
5.2. データセットの詳細
今回使用したデータは、大きく分けて以下の2つです。
- Sentinel-2衛星から取得した衛星画像(出典:Contains modified Copernicus Sentinel data 2023)
- 道路中心線データ(出典:Conservation GIS-consortium Japan)
道路中心線データは「最適化ベクトルタイル試験公開」(https://github.com/gsi-cyberjapan/optimal_bvmap)のデータをもとに、コンサベーションGISコンソーシアム(http://cgisj.jp)が編集・調整したデータを表示・使用しています。
道路中心線データは2023/10/1時点のものです。これに対応して、衛星画像も同時期のものを使用しています。具体的には、Sentinel-2衛星が衛星画像を取得した日付を、2023/10/1を基準にした前後7日間に固定し、その中で雲量が最も少ない画像を選定しました。これは、今回用いたような光学衛星画像では、雲が地表面を覆うことで道路などの地物を十分に観測できなくなるためです。
データセットの分割は、想定課題に合わせて以下のように設定しました。
データセット:
- 訓練データ:大阪と山形の衛星画像と道路マスクのセット
- 検証データ:大阪と山形の衛星画像と道路マスクのセット、学習の管理に使用
- テストデータ:東京の衛星画像と道路マスクのセット
大阪・山形地域の過学習は考えられるが、現状どの程度の予測が可能かを確かめる。
5.3. タイル生成とデータ不均衡
学習に使用する画像サイズは 128×128 ピクセルとしました。10m 解像度なので、実際の縮尺では 1280m 四方に相当します。ただ、訓練画像を作成する際に道路が全くない画像(道路ラベルが極端に少なく、不均衡なデータ)が出てきます。ここでは学習の効率化のため、道路と判定されたピクセルが5%以上ある画像を対象とします。
5.4. モデルのアーキテクチャ
今回は3パターンのモデルを構築して、道路網抽出の精度を確認していきます。それぞれのモデルは、U-Netをベースとしたアプローチとなっています。U-Netは、今回のようなセマンティックセグメンテーションタスクでよく用いられるネットワーク構成(アーキテクチャ)の一つです。
U-Netの具体的な仕組みを理解するために、まずは多くのネットワーク構成で採用されている「エンコーダ」と「デコーダ」という2つの役割を整理します。これらは、情報を別の形へ変換する際の基本的な型として機能しています。
エンコーダ:
データを段階的に凝縮し、ノイズを削ぎ落としながら、データが持つ特徴を抜き出す工程。
デコーダ:
抜き出された特徴をもとに、元のサイズへ戻しながら、結果へと組み立て直す工程。
この「特徴を抽出してから、別の形へ作り直す」という流れは、翻訳(ある言語を意味に変換し、別の言語で構成し直す)や音声認識(音を特徴に変換し、文字として組み立て直す)など、幅広いタスクの基盤となっている共通の仕組みです。
しかし、この過程では、特徴を抽出する際に細かなニュアンスや精密な構造が失われやすいという課題があります。これを解決するために、深層学習で広く使われている汎用的な手法が「スキップ接続」です。スキップ接続は、ある層の情報を途中の層を飛び越えて後段の層へ直接渡す仕組みです。U-Netは、このスキップ接続を非常に効果的に取り入れた構造になっており、下図のように「U字型」に表現されるため、それが名前の由来になっています。
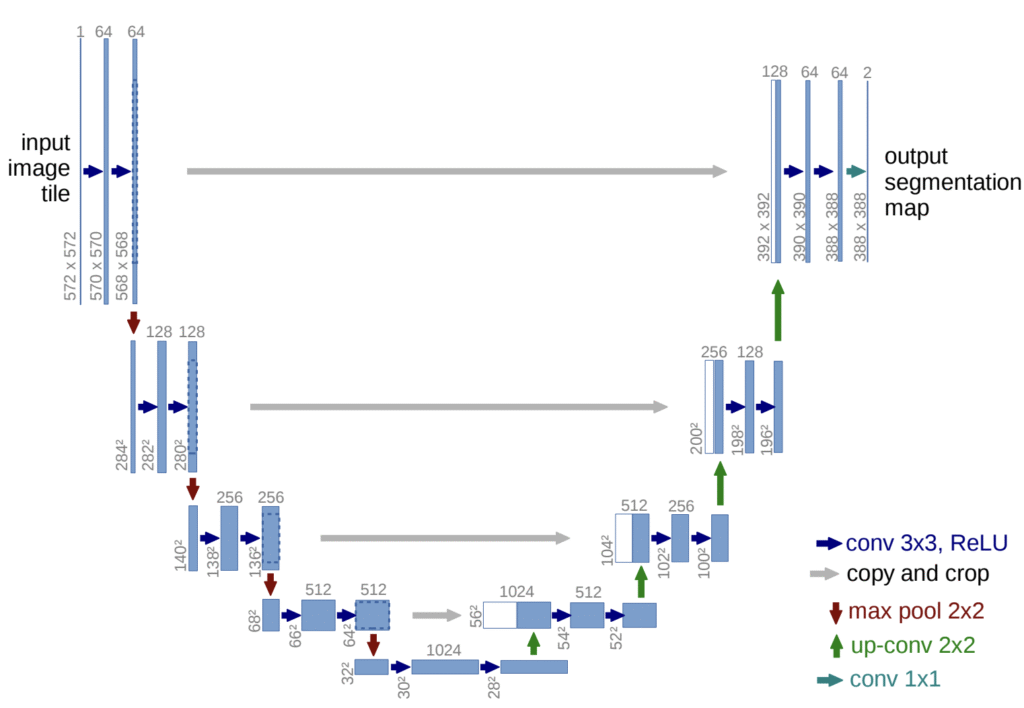
図の中央にある灰色の矢印が示す通り、U-Netでは、エンコーダ側の特徴マップを対応するデコーダ側へ直接渡して結合する方式を用いています。これにより、圧縮の過程で失われやすい位置情報や細かな形状情報を復元しやすくなります。
このU-Netを使用して、今回比較検証するモデルは大きく分けて3つです。
モデル1:
10m解像度の入力画像から、10m解像度の道路ラベルを出力するモデル
モデル2:
10m解像度の入力画像から、2.5m解像度の道路ラベルを出力するモデル
– 出力の際には、転置畳み込みを2回行い、解像度を2.5mに引き上げる
– U-Netのスキップ接続が利用できない
モデル3:
10m解像度の入力画像を補間することで2.5m解像度の入力画像を作成し、2.5m解像度の道路ラベルを出力するモデル
– 出力の際の転置畳み込みは行わない
– U-Netのスキップ接続が利用できる
5.5. 学習・推論条件
その他の実験条件は以下のとおりです。
- 最適化手法
- Adam
- 評価指標
- IoU
- F-Score
- 学習率
- \(1.0×10^{-4}\)
- 環境・使用マシン
- Google Colab
- L4 GPU
6. 技術検証と実験結果
6.1. 技術課題へのアプローチごとの検証
検証①:道路中心線データを拡張し作成したラベルについて
道路中心線データを利用して作成した道路ラベルについて記述していきます。元の道路中心線のデータ(図10)とそこから作成した道路ラベル(図12, 図13)を確認していきましょう。今回は例として、10m解像度の場合で説明をしていきます。
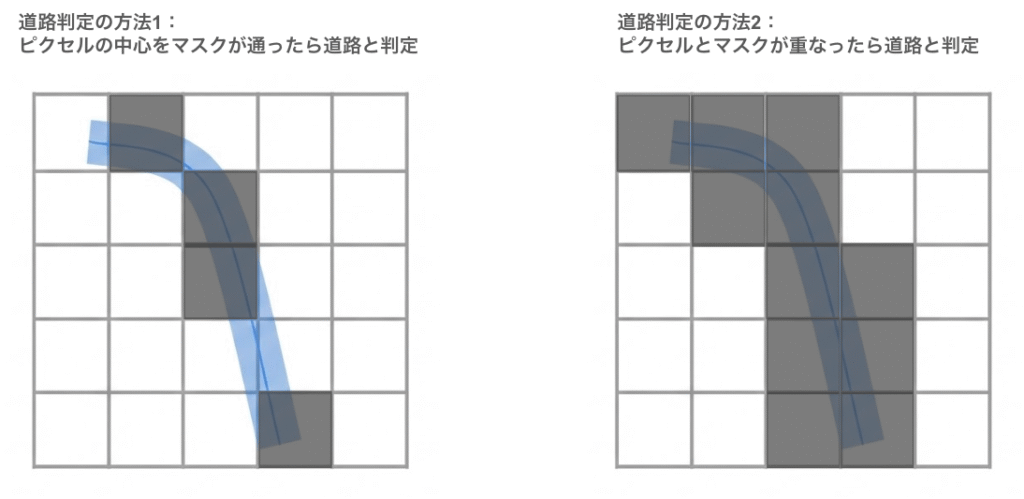

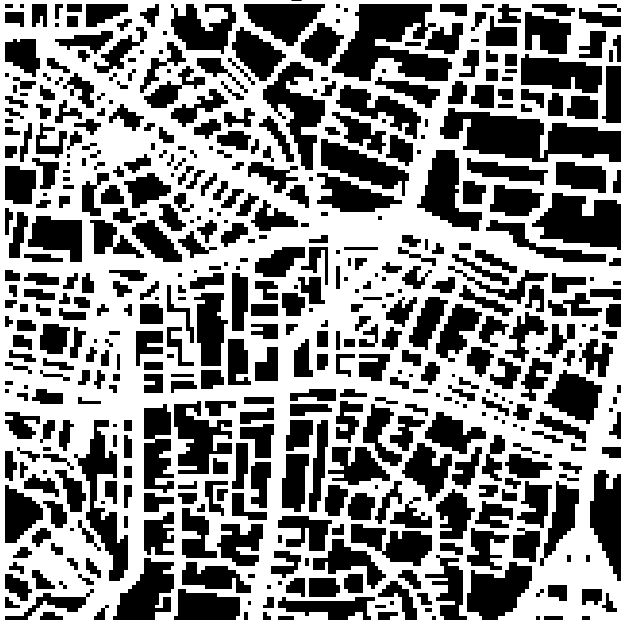
左が、10m解像度における道路判定の方法1(マスクがピクセルの中心を通った場合のみ、道路ラベルと判定を行う)で作成した正解ラベルです。大きい道路に関しては鮮明にマスクが見えますが、そのほかの小さい道路については明らかに取りこぼしが多く、道路の連結性をうまく表現できていないことがわかります。
右が、10m解像度における道路判定の方法2(マスクがピクセルに少しでも重なれば、道路ラベルと判定を行う)で作成した正解ラベルです。道路の連結性、という観点から見るとこちらのラベルの方が取りこぼしなくラベルを作成できています。
ただ、道路が密集している地帯に関しては、塗りつぶすような形になってしまい、作成方法②の図の、左下・右下のように道路の網目のような形状が認識できなくなってしまう場合があります。これは10m解像度の単位で道路ラベルを作成した際には避けて通れない問題です。
検証②:細い道路向けの損失関数・評価指標
今回の道路網抽出タスクにおいては、損失関数として単一の指標を用いるのではなく、Dice LossとBCE (Binary Cross Entropy) の2つを組み合わせた加重平均を採用します。
$$ L_{total} = \alpha L_{Dice} + (1 – \alpha) L_{BCE} $$
なぜこの手法が有効なのか、それぞれの損失関数の特性と道路ラベルの予測確率のヒートマップの比較をしながら記述していきます。
Dice Lossの数式による解釈
Dice Lossは数式では以下のように定義されます。
$$ L_{Dice} = 1 – \frac{2 \sum_{i=1}^{N} p_i g_i + \epsilon}{\sum_{i=1}^{N} p_i + \sum_{i=1}^{N} g_i + \epsilon} $$
\(N\):全画素数
\(p_i\):予測確率
\(g_i\):正解ラベル
\(\epsilon\):ゼロ除算を防ぐための平滑化項
この数式からも分かるように、Dice Lossは個々のピクセルを独立して評価するのではなく、画像全体の領域としての重なり具合を評価する点に特徴があります。この特性により検出能力には長けていますが、一方で細かい構造に対しては過検出(塗りつぶし)が発生しやすい傾向があります。
その理由は、数式の分子と分母の関係性にあります。分子は予測確率と正解ラベルの積(共通部分)を2倍したものですが、分母はそれぞれの総和となっています。
例えば、道路が網目状になっているケースを考えます。あるピクセルを正しく「道路」と予測できた場合、その寄与は分子において2倍の重みを持ちます。一方で、誤って背景を「道路」と予測してしまった場合(過検出)、それは分母のみを増加させ、分子には影響しません。つまり、「正解を見逃すこと(False Negative)」によるLossへのペナルティは、「余計に塗ってしまうこと(False Positive)」によるペナルティよりも、数式上およそ2倍重くなることが分かります。
そのため、モデルの学習過程においては、細部の網目構造を厳密に再現しようとして途切れてしまうリスクを冒すよりも、「大まかな形を捉えて周辺ごと塗りつぶす(Recallを優先する)」ような予測をした方が、結果としてLossが下がりやすく、学習効率が良いという判断(局所最適解)に収束しやすくなります。
BCE (Binary Cross Entropy) の数式による解釈
BCEは数式では以下のように定義されます。
$$ L_{BCE} = – \frac{1}{N} \sum_{i=1}^{N} \left[ g_i \log(p_i) + (1 – g_i) \log(1 – p_i) \right] $$
\(N\):全画素数
\(p_i\):予測確率
\(g_i\):正解ラベル
数式を見て分かるように、BCEはDice Lossとは対照的に、ピクセル一つ一つを独立した事象として評価しています。最終的な評価は、個々のピクセルの誤差の単純な総和(平均)となります。
BCEは境界を鮮明に判別することに長けていますが、構造的な連続性を無視して、細切れになったようなピクセルの判定を起こしてしまう場合があります。これは式の対数関数の項(\(\log\))と、和(\(\sum\))の性質を見ると分かります。
式は2つの項の足し合わせになっていて、各項は以下のように動きます。
- 正解が道路の場合 (\(g_i=1\)):前半の項 \(- \log(p_i)\) が作動
- 正解が背景の場合 (\(g_i=0\)):後半の項 \(- \log(1 – p_i)\) が作動
Dice Lossでは「見逃し(FN)」のペナルティが「余計な塗り(FP)」より2倍重かったのに対し、BCEでは数式上、この2つのペナルティは対等です。つまり、BCEは「道路の見逃し」と「背景を間違って道路と判定すること」を同等に評価します。道路ラベルが背景にはみ出すことをDice Lossほど許容しません。Dice Lossが、全体として繋がっていれば少しくらい塗りつぶしても良い(Recall重視)」という学習をするのに対しBCEは、隣が道路かどうかに関わらず背景を塗ることにペナルティを課す、(Precision重視)という態度をとります。
その結果、網目の隙間のような際どいピクセルに対してBCEは、リスクを冒して繋げるよりも安全に切断して、背景として処理することを選びがちになります。画素単位で正確さを追求するので線は細く綺麗ですが、所々で途切れてしまう予測になりやすいのは、この「独立性」と「ペナルティの対等性」によるものです。
予測確率のヒートマップの比較
学習結果の違いを道路ラベル予測の確率のヒートマップで比較してみましょう。


この二つを比較すると、Dice Lossは極端な確率値(赤)のヒートマップになっており、BCEは決定的な確率値(緑〜黄緑)を出していないヒートマップになっています。
Dice Lossに関しては、「塗り残す(見逃す)」ことへの罰則は重いですが、余分に塗ってしまうことへの罰則は非常に軽い設計になっています。そのため一度道路と予測し始めると、その周辺も含めて、積極的に道路として予測する方向へ学習が進みます。一方、BCEは「余分に塗る(はみ出す)」ことに対しても厳しく罰則を与えます。ある程度道路だと予測できていても、少しでも背景にはみ出すリスクがある場合、BCEは道路らしい領域であっても過信せず、強くブレーキをかけます。そのため、Dice Lossのように極端な値(1.0)までは振り切れず、控えめなヒートマップになるようになっています。
最後に、加重平均をとった場合の予測確率のヒートマップが以下です。

それぞれの損失関数のみで学習した場合と比べて、道路の連結性や網目状の構造を理解するように学習できていそうです。
それぞれの場合のテストデータに対して、評価指標であるIoUとF-Scoreは以下の通りです。IoUは予測と正解の重なりの大きさを評価する指標であり、F-Scoreは正しく検出できた領域の多さと、余計に検出しすぎていないかのバランスを評価する指標です。数値で見た場合、DiceLossとBCEの加重平均を損失関数とした場合のモデルがより良い結果となっています。
| 手法 | IoU | F-Score |
|---|---|---|
| DiceLoss only | 0.4918 | 0.6059 |
| BCE only | 0.5233 | 0.6347 |
| DiceLoss & BCE | 0.5292 | 0.6397 |
検証③:転置畳み込みとバイキュービック補間による道路ラベル画像の超解像
本検証では、10m解像度の衛星画像から2.5m解像度の道路ラベルを出力する方法として、転置畳み込みを用いる方法と、バイキュービック補間(Bicubic補間)を用いる方法を比較します。
まず、転置畳み込みについて簡単に説明します。転置畳み込みは、縮小された特徴マップをより大きな画像サイズへ拡大するための処理です。通常の畳み込みが、画像を圧縮しながら特徴を抽出していくのに対し、転置畳み込みはその逆方向に働き、粗い特徴表現から高解像度の出力画像を生成します。U-Netでは、デコーダ部分で出力を元の画像サイズへ戻す際によく用いられる処理の一つです。今回はこれを2回行えば、10m解像度が2.5m解像度になるという想定です。ただし、入力時点で失われた細かな位置情報や境界情報を、出力段階だけで完全に復元することは容易ではありません。特に、道路のような細い構造物を対象とする場合には、予測結果がやや太くなったり、周辺まで塗り広がったりすることがあります。
一方、バイキュービック補間は、画像そのものを拡大するための補間手法です。周囲の複数の画素値をもとに、新しい画素値を計算します(図17)。今回の文脈では、10m解像度の入力画像をあらかじめ2.5m解像度相当に拡大してからモデルへ入力するために用いています。重要なのは、バイキュービック補間によって新しい観測情報が増えるわけではない、という点です。あくまで元の画素値をもとに、空間的に滑らかな画像を再構成しているに過ぎません。しかし、モデルにとっては高解像度の空間サイズで特徴を扱えるようになるため、道路のような細い構造を表現しやすくなる場合があります。
さて、今回の結果を比較すると、転置畳み込みを用いた手法では大まかな道路領域は捉えられているものの、道路が密集する領域ではやや塗りつぶし気味になっており、細い道路の分離や交差点付近の形状表現には課題が見られました。これに対して、バイキュービック補間を用いた手法では、道路の線形構造がより細く連続的に表現されており、道路網らしい形状が比較的保たれていました。確率ヒートマップを見ても、補間を用いた手法の方が道路に対応する領域が細く明瞭であり、非道路領域との境界も比較的はっきりしています。


この違いは、U-Netのスキップ接続をどのように活かせるかが関わっています。転置畳み込みを用いた手法では、10m解像度の特徴表現を出力段階で2.5m解像度へ拡大しているため、細かな位置情報を後段だけで補う必要があります。しかし、今回のように10m解像度の1ピクセル内に複数の道路情報が入りうる状況では、その混在した情報を出力側だけでうまく分離することは容易ではありません。一方、バイキュービック補間を用いた手法では、入力段階から2.5m相当の空間サイズで画像を扱うことができるため、U-Netのエンコーダ・デコーダ間のスキップ接続を通して、比較的細かな位置情報を保ったまま予測しやすくなります。補間画像は実際の高解像度観測画像ではありませんが、少なくともネットワーク内部では高解像度の空間配置を維持したまま処理できるため、道路の構造を表現するうえで有利に働いたと考えられます。
以上より、今回の条件では、出力側で転置畳み込みを用いて高解像度化する方法よりも、入力画像をバイキュービック補間によって拡大してから予測する方法の方が、道路網の細かな構造や連結性を表現しやすい結果となりました。ただし、補間後の画像は元の10m解像度画像をもとに生成されたものであり、実際に2.5m解像度で観測した画像と同等ではありません。そのため、この手法は「新しい詳細情報を復元している」というよりも、限られた観測情報を、モデルが扱いやすい表現へ変換していると捉えるのが適切です。
6.2. 全体精度の比較と考察
以上の技術課題に対してアプローチを行い、3種類のモデルを構築しました。評価指標として用いたIoUとF-Scoreの結果は以下のとおりです。
- モデル1(10m解像度入力から10m解像度出力)
- モデル2(10m解像度入力から2.5m解像度出力)
- モデル3(10m解像度画像を補間して2.5m相当にした入力から、2.5m解像度出力)
| モデル | IoU(Train) | IoU(Test) | F-Score(Train) | F-Score(Test) |
|---|---|---|---|---|
| モデル1 | 0.52 | 0.53 | 0.65 | 0.64 |
| モデル2 | 0.34 | 0.29 | 0.51 | 0.35 |
| モデル3 | 0.49 | 0.22 | 0.66 | 0.33 |
表の数値だけを見ると、モデル1が最も高いスコアを示しました。ただし、モデル1は10m解像度のマスクを用いて評価しているのに対し、モデル2およびモデル3は2.5m解像度のマスクを用いて評価しているため、これらを単純に比較することはできません。特に、テストデータである東京のような道路が密集した地域では、10m解像度のマスクでは1画素の中に道路とその周辺が同時に含まれやすく、細い道路の形状も粗く表現されます。そのため、細い道路の位置や幅の違いが評価結果に反映されにくく、相対的に高いスコアが得られやすいと考えられます。一方、2.5m解像度のマスクを用いる場合は、より細い道路まで正確に捉える必要があるため、評価の難易度は高くなります。したがって、モデル2およびモデル3のスコアがモデル1より低いことは、単純に性能が劣ることを意味するわけではありません。
以下に、同じ衛星画像に対する各モデルの道路マスク予測結果を示します。

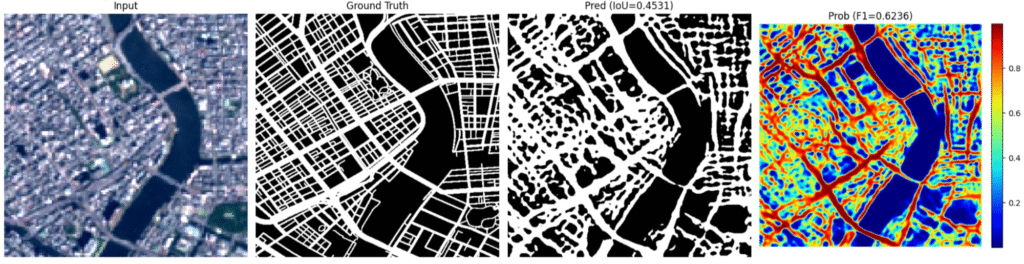
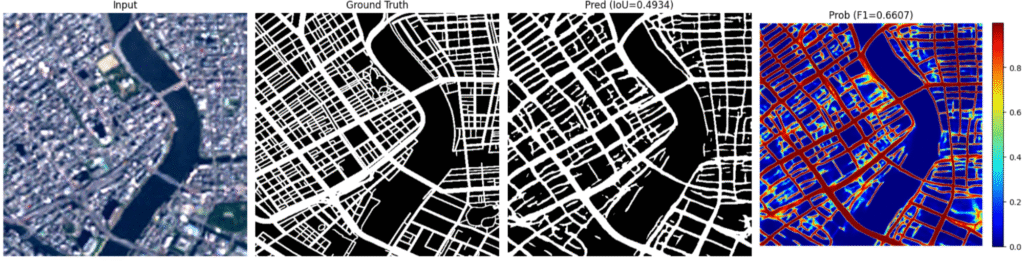
実際に図を見ると、モデル1と比べて、モデル2およびモデル3のほうが道路網の細かな構造をより表現できていると考えられます。特にモデル3では、幹線道路だけでなく細い道路の構造も比較的明瞭に表現されているように見えます。
しかし、TrainとTestのスコア差に着目すると、モデル2およびモデル3ではモデル1に比べて Test スコアの低下が大きく、汎化性能に課題があることが示唆されます。特にモデル3では、Trainでは比較的高いスコアを示す一方でTestで大きく低下しており、訓練データへの適合が強い、すなわち過学習傾向がある可能性があります。
また、このTestスコアの低下はドメインシフトが影響している可能性もあります。図23および図24に示すように、Trainデータとして用いた山形・大阪と、Testデータとして用いた東京との間では、道路ピクセル比率の分布に違いが見られます。
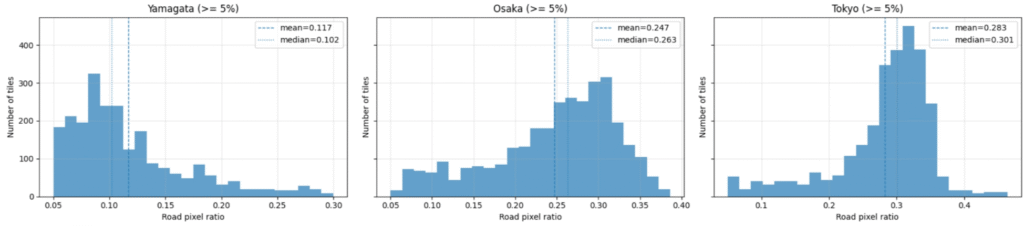
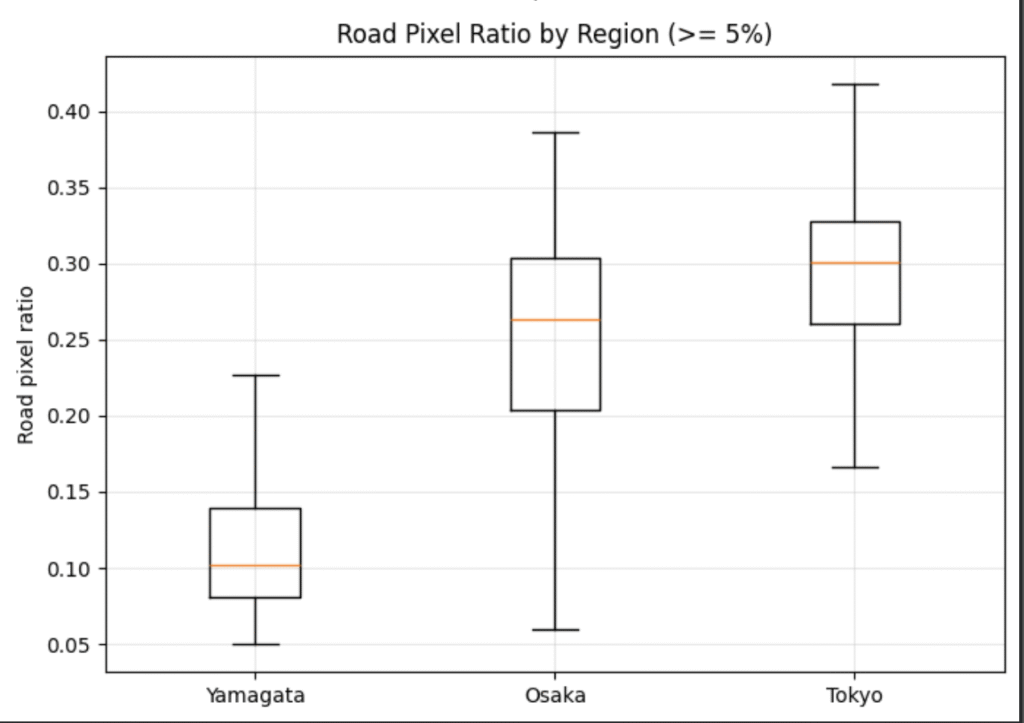
特に東京は、山形や大阪と比較して道路ピクセル比率の高いタイルが多く、道路密度の高い複雑な道路網を含むサンプルが多くあります。このことから、TrainとTestの間には地域差に起因するデータ分布のずれ、すなわちドメインシフトが存在している可能性があります。したがって、モデル2およびモデル3のTestスコア低下は、高解像度マスクを用いた抽出タスク自体の難しさに加え、モデルの過学習傾向と地域差に起因するドメインシフトの両方が影響した結果であると考えられます。
7. おわりに
7.1. 技術検証のまとめ
本記事では、10m解像度の衛星画像を用いた道路網抽出タスクを対象として、主に以下の3つの観点から技術的な検討を行いました。
- 教師ラベルの作成方法
- 損失関数の設計
- 解像度の扱い方
7.1.1. 教師ラベルの作成方法
まず、教師ラベルの作成については、道路中心線データをそのまま利用するのではなく、道路幅をどのように定義し、どのような基準でピクセルへ割り当てるかが、ラベル設計における重要な論点であることを整理しました。特に、10m解像度の画像では1ピクセル内に複数の道路情報や周辺地物が含まれる可能性があるため、「どこまでを道路とみなすか」という判断そのものがラベルの品質を左右します。このことから、教師ラベルは単なる正解データではなく、道路幅の定義や画素への割り当て基準といった分析上の前提を反映した設計対象であるといえます。したがって、道路網抽出の性能を評価する際には、モデル構造や学習方法だけでなく、教師ラベル生成の考え方まで含めて捉える必要があります。
7.1.2. 損失関数の設計
次に、損失関数については、Dice Loss と BCE を組み合わせることで、道路の連続性をある程度保ちながら、過剰な塗りつぶしを抑えられることを確認しました。単純な画素単位の分類精度だけでは、道路のように細く連続した構造を十分に評価できないことがあります。そのため、損失関数の選定においては、対象物の性質を踏まえたうえで、モデルにどのような予測傾向を持たせたいのかを明確にすることが重要です。今回の結果からは、Dice Loss が持つ領域全体を捉える性質と、BCE が持つ画素単位での識別性が相補的に機能していることが示されました。一方で、道路網のような連結構造をより直接的に扱える損失関数については、今後も検討の余地があります。
7.1.3. 解像度の扱い方
また、解像度の扱いについては、10m解像度の入力画像から2.5m解像度の道路ラベルを予測する方法として、出力側で転置畳み込みによって高解像度化する手法と、入力画像をあらかじめ補間してから予測する手法を比較しました。その結果、今回の条件では、入力画像を補間したうえで U-Net のスキップ接続を活かす構成の方が、道路の細かな形状や連結性を表現しやすい可能性が示されました。一方で、Train と Test のスコア差に着目すると、この構成では汎化性能に課題が残ることも示唆されました。特に、補間によって見かけ上の解像度を高めたとしても、新たな観測情報が付加されるわけではありません。そのため、細かな道路構造を表現しやすくなる可能性がある一方で、高解像度出力タスク自体の難しさや地域間の分布差の影響を受け、未知地域では性能が低下する可能性がある点には注意が必要です。
以上の検証を通して、衛星画像を用いた道路網抽出では、モデルの選定や学習条件の調整だけでなく、ラベル設計や解像度設計を含むタスク定義そのものが、精度や結果の解釈に大きく関わることが分かりました。特に、衛星データのように観測解像度や取得条件に制約のあるデータを扱う場合には、「何を入力とし、何を正解とし、どの粒度で出力させるのか」という設計が、実験結果の妥当性を支える前提となります。したがって、本タスクは単なる画像セグメンテーションとして扱うのではなく、地理空間情報の特性を踏まえながら、データ設計と機械学習を統合的に検討する課題として位置付ける必要があります。
7.2. 今後試したいこと
今回の検証を通して、衛星画像からの道路網抽出では、入力データの制約、教師ラベルの作成方法、解像度の扱い方が相互に密接に関係していることが分かりました。今後の改善に向けては、主に以下の3点が重要であると考えられます。
- 入力情報の拡張
- 訓練データの地域的多様性の向上
- 道路構造を踏まえたモデル設計・評価設計の見直し
7.2.1. 入力情報の拡張
入力情報そのものの拡張は重要な論点です。今回は主にRGB画像を用いて検討を行いましたが、衛星データからは近赤外や短波長赤外など、可視光以外のスペクトル情報も取得できます。こうした情報を加えることで、植生と道路の識別や、陰影の影響を受けやすい場面での判別性能向上が期待されます。特に、道路と周辺環境の反射特性の違いをより多面的に捉えられるようになれば、RGBのみでは識別が難しい場面においても、より安定した予測につながる可能性があります。
7.2.2. 訓練データの地域的多様性の向上
汎化性能の観点では、訓練データの地域的な多様性を高めることも重要です。今回の設定では限られた地域の画像を用いて学習と検証を行いましたが、実際には道路の形状や密度、周辺の土地利用、建物の密集度などは地域によって大きく異なります。特に今回の結果では、訓練時には高いスコアを示したモデルでも、テスト地域では性能が大きく低下する例が見られました。そのため、モデルの外部汎化性能を高めるためには、単にデータ量を増やすだけではなく、異なる都市構造や地理的条件を持つ地域を意識的に取り入れたデータ設計が必要です。特に、都心部と郊外、平野部と山間部では道路の見え方や連結のされ方が異なるため、こうした違いを踏まえた学習・評価設計が今後の精度向上に直結すると考えられます。
7.2.3. 道路構造を踏まえたモデル設計・評価設計の見直し
モデル設計の観点では、道路という対象の構造的特徴をより直接的に反映できる手法の導入も検討対象になります。たとえば、今回採用した Dice Loss と BCE の加重平均は一定の有効性を示しましたが、道路網のような細線構造により適した損失関数や評価指標を導入することで、より実用的な連結性の保持が期待されます。また、今回の比較では、補間を用いた高解像度出力モデルが道路網の細かな構造を表現しやすい一方で、Train と Test のスコア差が大きく、汎化性能には課題が残りました。そのため、見かけ上の解像度向上による表現力と、未知地域に対する安定性との両立をどのように図るかは、今後の重要な検討課題です。加えて、関心領域の大きさやタイルの切り出し方についても、道路密度や都市構造に応じて最適な設定が異なる可能性があります。入力スケールを見直すことで、局所的な道路形状を重視する学習と、道路ネットワーク全体を捉える学習とのバランスも再検討できます。
本記事で扱った内容は、衛星画像を用いた道路網抽出に関する基礎的な検証ですが、その過程を通して、実運用や社会実装を見据える際の論点を具体化することができました。特に、精度向上を単にモデル改善の問題として捉えるのではなく、データ取得、ラベル生成、評価方法、適用対象地域の特性まで含めて包括的に設計する必要があることが明確になりました。今後は、これらの技術的課題を段階的に整理しながら、より高い汎化性能と実用性を備えた道路網抽出モデルの構築につなげていきたいと考えています。
8. 参考・引用文献
- Ayala, F., Henríquez, C., and Rebolledo, R., 2021. Towards Fine-Grained Road Maps Extraction Using Sentinel-2 Imagery. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, V-3-2021, 9–15.
- Ronneberger, O., Fischer, P., and Brox, T., 2015. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv preprint arXiv:1505.04597.
- 一般財団法人リモート・センシング技術センター(RESTEC),「Sentinel-2A / 2B / 2C / 2D」,衛星情報データベース,https://www.restec.or.jp/satellite/sentinel-2-a-2-b.html (閲覧日 2026年3月24日)
- コンサベーションGISコンソーシアムジャパン,「道路中心線2023・道路縁2023・道路構成線2023」,https://cgisj.jp/data_type_description.php?data_type=RoadDatasetOpt (閲覧日 2026年3月24日)
- OpenStreetMap contributors, “OpenStreetMap,” https://www.openstreetmap.org (閲覧日 2026年3月24日)