
Index
はじめに
はじめまして。データソリューション事業部の宮澤です。
このたび、弊社で行っている研究活動の一環として本記事を執筆いたしました。
最近のLLMを取り巻く動きとして、GPT-3.5やGPT-4のようなAPIを通じて利用できるクローズドなモデルだけではなく、一般に公開されて研究や商用に利用が可能なオープンソースのLLMの開発が活発に進められています。
2023年7月18日には MetaからGPT-3.5に匹敵する精度を出したと言われるオープンソースのモデルである「Llama21」が公開されました。
本記事ではその「Llama2」を実際に動かすまでのセットアップ手順と、実際にテキストを生成させた結果をご紹介します。
調査の概要
今回はLlama2のセットアップ手順に焦点を当てています。
セットアップを行ったのち、プロンプトを与えて回答を得るところまでを調査対象としました。
セットアップでは2つの方法を試行しました。
調査の目的
今回の調査の目的は、最新のオープンソースのLLMに実際に触れてみることで、その使用方法などの一次情報を得ることです。さらに、実際にテキスト生成まで行うことで、オープンソースのモデルを活用した新たな研究テーマについて考察します。
調査レポート
セットアップ手順
Llama2を使用する方法を調査したところ、セットアップする方法は大きく2つありました。
- ローカルにダウンロードして使う方法
- HuggingFace経由で使う方法
結論として、今回の検証した環境(M1 Mac : Apple silicon)では1番の方法は上手くいかなかったため、同じ環境ですぐに実装したい方は2番から始めることをお勧めします。
1. ローカルにダウンロードして使う方法
こちらは書いてある通り、モデルをローカル環境にダウンロードして使用する方法です。
上述の通り、今回はMacOS(Apple Silicon)で検証を行っています。
1. Metaへのモデル利用申請
モデルをダウンロードするにはまずMetaへの申請が必要であるため、こちらから申請を行います。
数分するとメールが届きます。
そこに書いてあるリンクをこの後のステップで使用します。(有効期限が24時間なので注意してください。)
2. リポジトリの取得
適当な作業用フォルダを作り、git cloneでリポジトリを取得します。
git clone https://github.com/facebookresearch/llama3. 必要なコマンドラインツールをインストール
Githubの以下の記載に従って、あらかじめ必要なコマンドラインツールを入れておきます。
(GithubのURLは本記事の末尾に記載しているのでご参照ください。)
Pre-requisites: make sure you have wget and md5sum installed. Then to run the script: ./download.sh.
ここではモデルのダウンロードスクリプトを動かす前に予めwgetとmd5sumが必要とのことでしたので、その通りに進めていきます。
brew install wget
brew install md5sumHomebrewをインストールしていない場合は、事前にインストールが必要になります。
4. ダウンロードスクリプトを実行
手順2番で取得してきたリポジトリ内にあるllamaフォルダに移動し、ダウンロードスクリプトを実行します。
cd llama
bash download.shすると以下のように申請時に返信されたメールにあるURLを打つように指示があるので、指示通りURLをコピペします。
Enter the URL from emailここでダウンロードしたいモデルを聞かれます。2
Enter the list of models to download without spaces (7B, 13B, 70B, 7B-chat, 13B-chat, 70B-chat), or press Enter for all : 70Bは容量が大きそうだったので、今回は7B, 13, 7B-chat, 13B-chatを選択しました。
1つのモデルにつき約20分程度でダウンロードができました。
特にエラーなく、以下のようにファイルがダウンロードできていればOKです。
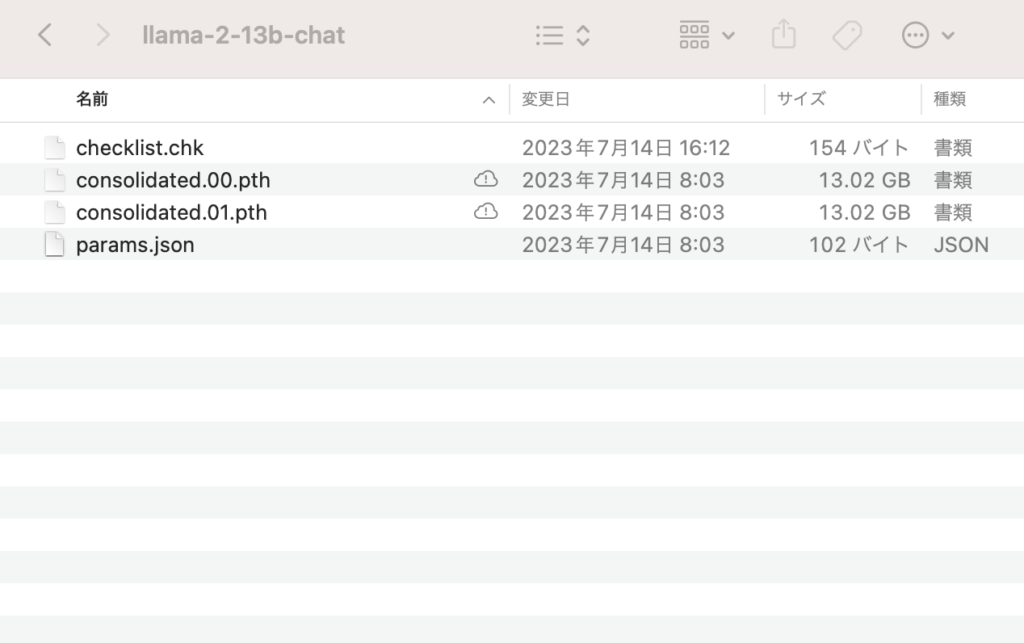
モデルのダウンロードはここまで完了です。
ここからは実際にモデルを動かしていきます。
5. conda環境の構築
GithubのREADME.mdを改めて確認すると、以下のように記載があったので、念の為conda環境を作っておくことにします。
In a conda env with PyTorch / CUDA available, clone the repo and run in the top-level directory:
ここで調べているなかで、M1チップを搭載したMacでPyTorchを使用するには、Minifogeを使って環境構築するのがよいということがわかったので、今回はMiniforgeを使ってconda環境を作りました。
理由としてApple Siliconでは正常に動作しないパッケージが多く、最も相性がいいのがMiniforgeとのことでした。
以下のコマンドで仮想環境の作成とアクティベート・非アクティベートができます。
仮想環境の作成時には、使用するpythonのバージョン指定もできます。
仮想環境の作成
conda create --name test_env python=3.9
アクティベート
conda activate test_env
非アクティベート
conda deactivate6. 必要なライブラリのインストール
次に、Githubのrequirements.txtを確認して、以下の必要なパッケージをインストールしました。
torch
fairscale
fire
sentencepiececonda installコマンドで見つからないパッケージもあるため、その場合はpip installで実行します。
ここではfairscaleが該当しました。
7. セットアップ
Githubに従って、リポジトリをクローンしたディレクトリに移動してからコマンドを実行します。
In a conda env with PyTorch / CUDA available, clone the repo and run in the top-level directory:
移動できたら以下コマンドを実行します。
pip install -e.このコマンドは現在のディレクトリにあるPythonパッケージを編集可能モードにするという意味です。
8. テストスクリプトの実行
ここまでの手順で必要な準備ができたので、実施にモデルを動かしていきます。
引き続きGithubに従って、以下のテストスクリプトを実行します。
torchrun --nproc_per_node 1 example_text_completion.py \\
--ckpt_dir llama-2-7b/ \\
--tokenizer_path tokenizer.model \\
--max_seq_len 128 --max_batch_size 4結果としては、以下のようなエラーが出てきました。
RuntimeError("Distributed package doesn't have NCCL " "built in")
RuntimeError: Distributed package doesn't have NCCL built in
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 7212) of binary:これはどうやらPytorchにおいて、GPU間での高速データ転送をするためのライブラリであるNCCL(NVIDIA Collective Communications Library)が存在しないということを意味しているようです。
念のため、GPUが使用できているかを確認するために、以下コマンドを実行したところ”True”と返ってきたため、GPU上では動かせているようでした。
python
>> import torch
>> torch.backends.mps.is_available()
Trueさらに原因を調べてみると、M1 チップに搭載されているGPUはNVIDIAのGPUではないため、M1 Mac上でNCCLを必要とする分散訓練コードを実行しようとすると、このエラーが発生するとのことでした。
GithubのIssueでも同じようなエラー報告がいくつかみられました。3
9. 対策
対策としてはC言語で実装するllama.cppを使用したり、GPUではなくCPU上で動かすという方法があるようですが、今回は実践せずに別の方法でモデルをセットアップすることとしました。
2. HuggingFace経由で使う方法
ローカルで動かすことを停止し、ここからはHuggingFaceのTransformersを使った実装を行うことにします。ここではGoogle Colaboratoryを使っています。
1. HuggingFaceアカウントの登録
手順1-1で行ったMetaへの利用申請に加え、モデルを利用するにはHuggingFaceのアカウント登録が必要とのことでした。方法は割愛しますがこちらから簡単に登録ができます。
注意点としては、Metaへの申請時と同じアドレスでアカウント登録を行う必要があります。
2. HuggingFaceでのトークン生成
こちらも方法は割愛しますが、今回はHuggingFaceに接続してモデルをダウンロードするのにアクセストークンが必要になるため、アカウントのSetting画面からアクセストークンを生成しておきます。
3. Google Colabの立ち上げ
今回はGoogle Colabを使っているため、新規ノートブックを準備しておきます。
こちらの使い方がわからない方は、公式ページをご参照ください。
なお、ランタイプはGPUを設定してください。
(T4でも動きますが、ProユーザーであればV100かA100を使うことをお勧めします。)
4. ライブラリのインストール
ここから、ノートブック上でモデルのセットアップを進めていきます。
まずは必要なライブラリをインストールしていきます。
!pip install transformers sentencepiece accelerate5. HuggingFaceへのログイン
次に、HuggingFaceへログインをします。
ここで先ほど生成したアクセストークンを使います。
!huggingface-cli loginログインが成功すると以下のような画面になります。
6. モデルのダウンロード
HuggingFaceのLlamaページをみると以下のようなモデルがあることがわかります。
ここでは、7B-chat-hfのモデルを指定しました。4
では、モデルをダウンロードしていきます。
ここではHuggingFaceのtransformersというライブラリを活用して進めていきます。
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)いくつか引数を設定していますが、ここではとりあえずモデルをダウンロードしてテキスト生成をする準備をしているという程度の認識で問題ありません。
ここまでできたらセットアップは完了です。
7. モデルを動かす
それでは、プロンプトを与えてテキストを生成させてみます。
まずは英語で”What is a good way to learn data science?”と聞いてみました。
(コード上の細かい設定の説明は割愛します。)
prompt = """USER: What is a good way to learn data science?
SYSTEM:"""
# 推論の実行
sequences = pipeline(
prompt,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
print(sequences[0]["generated_text"])回答結果は以下のとおりでした。
USER: What is a good way to learn data science?
SYSTEM: There are several ways to learn data science, including:
1. Online courses and tutorials: Websites such as Coursera, edX, and DataCamp offer a wide range of data science courses, from beginner to advanced levels.
2. Books and textbooks: There are many books and textbooks available that cover various aspects of data science, including R, Python, data visualization, and machine learning.
3. Practical projects: One of the best ways to learn data science is by working on practical projects. You can start by analyzing data sets from websites like Kaggle, UCI Machine Learning Repository, or data.world, and building projects that help you apply your knowledge of data science.
4. Join online communities: Joining online communities like Kaggle, GitHub, or Reddit can help you connect with other data scientists,内容としては適切であると読み取れます。
具体的には、「データサイエンスを学ぶのに良い方法は?」という質問に対して、「オンラインコースを使う・本や教科書を読む・実践経験を積む・コミュニティに入る」と、妥当な内容が返ってきています。(生成の最後を見てみると”…with other data scientists,”で終わっているので、おそらく上限に設定した200トークンあたりに差し掛かったため生成が停止したと考えられます)
以上がテキスト生成までの手順です。
テキスト生成結果の比較
セットアップを終えてテキスト生成ができることを確認したので、ここからは少し実験的に他のモデルとの生成結果の比較をしてみます。
今回は、Llama2-7B-chat-hf, Llama2-13B-chat-hf, gpt-3.5-turbo-0613 の3つで比較をしてみました。(本来であれば70Bモデルでの比較もしたかったのですが、Colab上でも処理が重く推論結果が出せなかったため、今回は上記のモデルで試すことにしました。)
QAタスクに対する精度比較
今回はクイズ形式で、以下のようにいくつかの問題を出してみました。
- データサイエンスに関する簡単なクイズ(クラスタリングによく使われる手法は?)
Please answer the following questions related to data science. In data science, which method is often used for clustering?
A. K-Means Clustering
B. Logistic Regression
C. Decision Trees
D. Support Vector Machines
正解:A. K-Means Clustering - 簡単な計算クイズ(消しゴムの値段はいくら?)
Please answer the following quiz question. The combined price of a ballpoint pen and an eraser is 110 yen. The ballpoint pen is 100 yen more expensive than the eraser. So, what is the price of the eraser?
正解:5 yen - 難しい計算クイズ(ドリンクは何本飲める?)
Please answer the following quiz question. You can exchange five empty juice cans for a new juice can. Currently, you have 200 new juice cans. So, how many juice cans can you drink in total?
正解:249
200本飲む→空き缶200本で40本ゲットして飲む→空き缶40本で8本ゲットして飲む→空き缶5本で1本ゲットして飲む(200 + 40 + 8 + 1 = 249本)
ここからは、日本語の問題も試していきます。
- 日本に関する基本的な知識を問うクイズ
以下の選択肢の中で、日本が発祥とされ、世界中で知られている食べ物は何でしょうか?
A. ピザ
B. パスタ
C. ハンバーガー
D. 寿司
正解:D. 寿司 - 日本に関する地理的な知識を問うクイズ
日本の地理について考えるとき、次のうちどの都道府県が最も南に位置しているでしょうか?
A. 沖縄県
B. 鹿児島県
C. 和歌山県
D. 福岡県
正解:A. 沖縄県
結果まとめ
| 問題 | Llama2-7B-chat-hf | Llama2-13B-chat-hf | gpt-3.5-turbo-0613 |
|---|---|---|---|
| 問題1 | A. K-Means Clustering (正解) |
A. K-Means Clustering (正解) |
A. K-Means Clustering (正解) |
| 問題2 | Answer : 10 yen (不正解) |
Answer : 15 yen (不正解) |
(途中式省略) Therefore, the price of the eraser is 5 yen. (正解) |
| 問題3 | Answer : 40 (不正解) |
Answer : 40. (不正解) |
You can drink a total of 205 juice cans in total. (不正解) |
| 問題4 | Please choose the answer you think is correct. <form name=”answer” …(以下省略) (不正解) |
答え: D. 寿司 (正解) |
答え: D. 寿司 (正解) |
| 問題5 | A. 沖縄県 Explanation: Of the four options, 沖縄県…(以下省略) (正解) |
答え: A. 沖縄県 (正解) |
答え: A. 沖縄県 (正解) |
生成結果の一部については、回答に関係ない文字列が長々と書かれていたため省略しました。
Llama2について見てみると、7Bと13Bのどちらのモデルでも、推論が必要な問題2と3は不正解となりました。問題3についてはgpt-3.5でも不正解となっているため難易度が高かったと思われます。(gpt-4では正解となりました。)
単純な選択問題については、英語の文章である問題1はどちらも正解、日本語の問題である4と5については13Bの方では正確に回答ができていました。
以上のように7Bと13Bの間でも能力向上が見られたため、テクニカルレポートにあるように、Llama2-70Bモデルがgpt-3.5に匹敵するという可能性は十分にあると感じられました。
今後、実行環境を整えることができたら70Bモデルでの生成も試してみたいと思います。
日本語タスクの能力について
ここで、Llama2の日本語の生成能力について確認するため、テクニカルレポートを確認したところ、以下のように日本語は学習データとして0.1%しか使われていないことがわかりました。
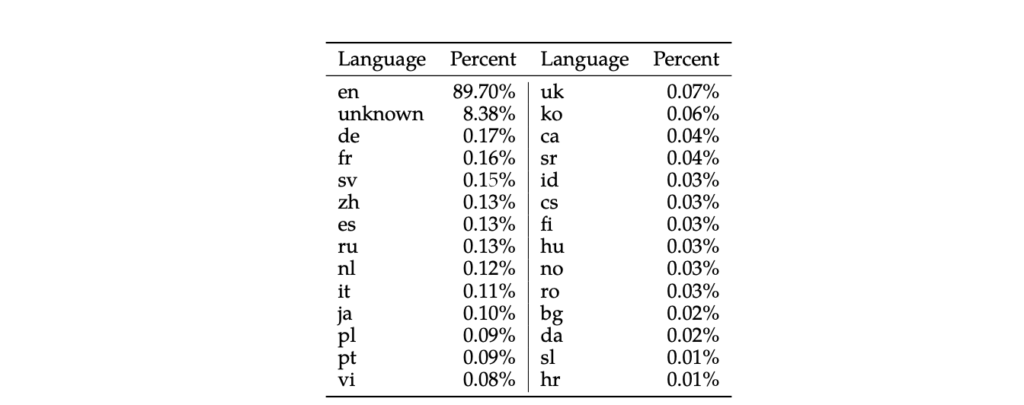
この学習割合にも関わらず、13Bモデルでは上記問題4と5に正解していたため、日本語のデータセットを使った適切なファインチューニングを行えば、日本語タスクに対する能力はまだまだ向上できると考えられました。
まとめ
今回はLlama2をローカル環境で実行することに挑戦してみました。
結果としてはM1 MacにおけるGPUの仕様上の問題でPyTorchの分散処理がうまくいきませんでしたが、HuggingFace経由では無事動かすことができました。
テキスト生成の精度としては、7Bや13BではGPT-3.5には劣ると感じたものの、簡単な選択問題には正確に回答することができました。
今後はこういった高性能なオープンソースLLMがさらに増えていき、実用にあたってはそれらのモデルにファインチューニングなどを行い、目的に沿ったカスタマイズをして使用することが増えてくるのではないかと予想しています。
今後の研究・検証ではLlama2の構築に使われた技術的な手法についても調査し、また日本語適用を目的としたファインチューニングなど、Llama2のようなオープンソースのモデルに対するカスタマイズについても検証してみたいと思います。
今後もオープンソースLLMの情報をキャッチアップしながら、引き続き研究を進めます。
1 MetaがMicrosoftと共同開発した大規模言語モデルです。2023年7月18日に公開されました。オープンソースのモデルであるため無料で利用ができ、一定の条件下では商用利用も可能となっています。パラメータ数は7B, 13B, 70B(1B = 10億)の3つのモデルを提供していています。 本文へ戻る
2 数値はパラメータ数を意味しています。”chat”とあるのはQAタスクに対応できるようにファインチューニングが行われているモデルのことです。 本文へ戻る
3RuntimeError: Distributed package doesn’t have NCCL built in #112
本文へ戻る
4 ローカルにダウンロードするときにはなかった”hf”というモデルがあることがわかります。HuggingFaceでのモデルの説明を見に行くと、”This is the repository for the 7B fine-tuned model, optimized for dialogue use cases and converted for the Hugging Face Transformers format.”とあります。つまり、Transformersライブラリを使って実装するために整えられたモデルということを意味しています。 本文へ戻る
参考
本記事の執筆にあたっては、以下のドキュメントや記事を参考にさせていただきました。
- Introducing Llama 2
- Github facebookresearch/llama
- マイクロソフトと Meta、Azure および Windows 上の Llama 2 で AI 分野のパートナーシップを拡大
- Llama 2: Open Foundation and Fine-Tuned Chat Models
- llama2のセットアップメモ (ダウンロードと推論)
- Llama 2 is here – get it on Hugging Face
- Google Colab で Llama 2 を試す
- HuggingFace での Llama 2 の使い方
- HuggingFace Transformers Model