
Index
はじめに
データソリューション事業部の宮澤です。
今回はLLM(大規模言語モデル)に関する”Textbooks Are All You Need”という論文について紹介します。本論文は、LLMの学習や訓練に使うデータの品質を高めることによるモデルの精度向上についての研究報告です。
スケーリング則に従った単純なデータの増量ではなく、「データの品質向上」というアプローチが興味深く、この研究が私自身が今後取り組んでいくファインチューニングなどの訓練データの作成に役立つと考え、本研究の調査を行いました。
文献情報
タイトル:Textbooks Are All You Need
執筆者:Suriya Gunasekar et.al
出版年月:2023年6月
https://arxiv.org/abs/2306.11644
文献レビュー
概要
本論文では「phi-1」というPythonコードの生成に特化した言語モデルを作成しています。phi-1は他のコード生成用の言語モデルよりも小さな1.3Bのパラメータを持つ、Transformerをベースとした言語モデルです。 本研究では、phi-1が、HumanEval1で50.6%, MBPP2で55.5%と、他のコード生成用の言語モデルと比較して高い精度を出したことが述べられています。
このことは、phi-1が他のコード生成用のモデルと比べて小さなモデルであるにも関わらず、その学習データや訓練データを教科書品質なものにすることで、コード生成のタスクにおいて高い精度を出すことが可能であったことを示しています。
本研究の目的
はじめに述べた通り、本研究では「データの品質」という観点から言語モデルの性能を向上させることを目的としています。
この背景には、言語モデルにおいて明らかになっている「スケーリング則」があります。 「スケーリング則」とは、言語モデルを学習する際に「使用する計算量」「学習するデータのサイズ」「モデルに利用するパラメータ数」という3つの要素と、検証データのクロスエントロピー損失との間に「べき乗則」が成り立つというものです。
このことは「計算量・データサイズ・パラメータ数を大きくすればするほど、モデルの性能が向上する」ということを意味しています。
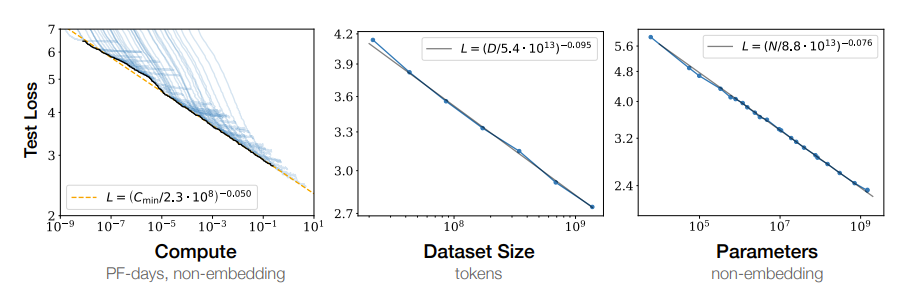
本論文ではこの「スケーリング則」を引き合いに出し、本研究においては定量的なモデルの増大とは異なった「データの質」という定性的な観点から、言語モデルの性能向上を探索していくと述べられています。
本研究の前提
本研究における前提として、以下の点を説明します。
- phi-1モデルの機能
- モデルの種類
- モデルの評価方法
1. phi-1モデルの機能
本研究で開発されたphi-1の機能は、Pythonのコード生成に特化したものです。 自然言語で与えられたプロンプトに対して、適切なPythonコードを生成することを目的として作られています。
2. モデルの種類
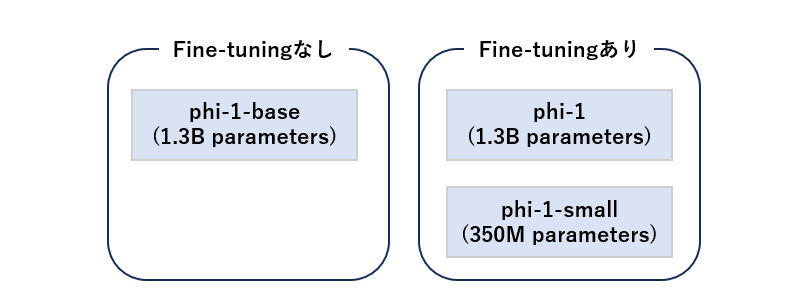
ここではphi-1を含めて3つのモデルを作り、検証を行ったと述べられています。
- phi-1:約1.3Bのパラメータを持つモデル。
- phi-1-base:ファインチューニングを行う前のphi-1モデル。
- phi-1-small:約350Mのパラメータを持つphi-1より更に小規模なモデル。
モデルアーキテクチャについてはここでは割愛しますが、本論文7ページに記載があります。
3. モデルの評価方法
モデルの精度評価にはHumanEvalとMBPPを使用しています。 これらについて簡単に説明しておきます。
HunamEval
これはOpenAIによって開発された評価指標です。 指示されたタスクに対して生成されたコードの実行結果から、機能的な正確さを評価します。 例えば以下のようなタスクがあります。(task_id = “HumanEval/16”)
def count_distinct_characters(string: str) -> int:
"""
Given a string, find out how many distinct characters (regardless of case) does it consist of
>>> count_distinct_characters('xyzXYZ')
3
>>> count_distinct_characters('Jerry')
4
"""これは、文字列の中からユニークである文字数をカウントして数値型で返すことを指示したプロンプトです。(プロンプトの中で関数名とデータ型が指定されています。) このようなタスクに対して、予め用意された正解の出力値と生成した関数の戻り値が一致しているかどうかで精度を評価します。
MBPP
こちらも同じようにコード生成の正確さを評価する指標であり、基礎レベルのPythonコード生成をタスクとしています。 こちらも例を挙げておくと、以下のようなタスクがあります。(task_id = 602)
"Write a python function to find the first repeated character in a given string."HumaEvalと同じように、予め用意された正解の値と生成した関数の戻り値が一致しているかどうかで精度を評価します。
本研究の結果
ここからは、本研究によって明らかになったことを2つ説明します。
- データを教科書品質なものにすることで小さなモデルでも高い精度を出すことができる
- ファインチューニングによって性能が大きく上がる
1. データを教科書品質なものにすることで小さなモデルでも高い精度を出すことができる
まずは結果から見ていきます。 本論文のTable 1では、phi-1と他モデルとの精度比較がされています。
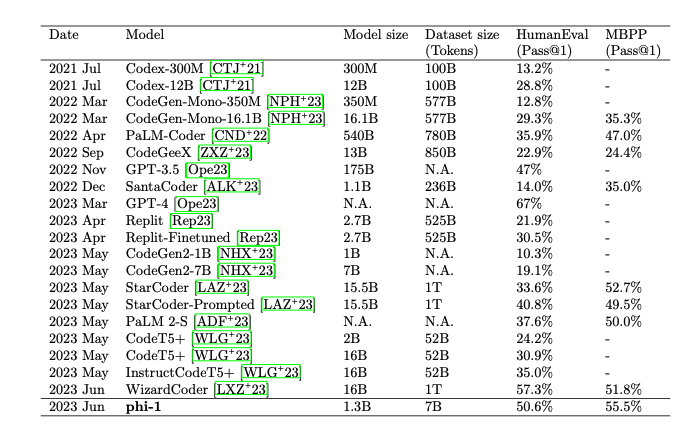
この表からは、phi-1とStarCoder3ではモデルサイズがそれぞれ1.3B、15.5Bであり、HumanEvalはそれぞれ50.6%、33.6%であることが読み取れます。 つまり、phi-1よりもパラメータ数が10倍以上大きなモデルですが、HumanEvalにおいてはphi-1のほうが大きく上回る結果となっています。 また、HumanEvalにおいてphi-1-baseでは29%、phi-1-smallでは45%の精度であったと述べられています。
これまでHuman Evalsで30%近い性能を達成した最小のモデルが「Replit-Finetuned」であり、これがphi-1-baseの約100倍のトークンで学習させていることから、単純なデータ量やモデルの大きさだけでなく、データ品質がモデルの精度改善にとって重要な要素であるということが明らかになりました。
2. ファインチューニングによって性能が大きく上がる
ファインチューニングを行っていないphi-1-baseとファインチューニングを行ったphi-1では、HumanEvalで約15ポイントの差があることから、ファインチューニングによって精度が大きく向上したことがわかります。
また本論文では、ファインチューニングを行った結果、事前学習までのモデルと比較して訓練データに含まれないようなタスクの実行に、大幅な改善が見られたと述べられています。 この理由としては、ファインチューニングが事前学習で得られた知識を適切に抽出して統合することに役立った可能性があることが挙げられています。
特に、各タスクの生成結果をみると、ファインチューニング後のモデルでは、訓練データに含まれていないような外部ライブラリをうまく使いこなしてタスクに対応するようになったことがわかりました。以下にモデルごとの生成結果の比較を引用して紹介します。
事例1
このタスクでは、ある数値の範囲からランダムで数値を取得し、そこで取得した数値をその次にランダムに取得する数値の範囲の下限に使うということを、数回繰り返すような論理手順が指示されています。

ファインチューニングをしていないphi-1-baseでは論理的な構造が作ることができていない一方で、ファインチューニングをしたphi-1-smallとphi-1については(不完全なコードではありますが)大枠の問題の構造を解釈してコードが生成できていることがわかります。
事例2
また、こちらのタスクではPygameというライブラリを活用し、ランダムにボールが動くような実装をするよう指示が与えられています。

これらの生成結果を比較すると、phi-1では指示された構造を論理的に記述できている一方で、phi-1-baseやphi-1-smallでは指示に対して論理構造を反映できていなかったり、適切な関数を呼び出せていないことがわかります。
これらの結果から、同じパラメータ数を持つphi-1とphi-1-baseでもコードの生成結果に明らかな違いがあり、ファインチューニング後のphi-1のほうが、適切な論理構造を持ったコードを生成する能力が大きく優れていることがわかりました。
一方でどちらもファインチューニングをしているphi-1とphi-1-baseを比較しても、phi-1のほうが精度が高いことから、パラメータ数やデータ量によって性能差が現れるスケーリング則が顕在であるということも読み取れます。
研究の手法
ここまで述べてきたように、phi-1は他のモデルよりも小さいにもかかわらず高い精度を出すことができました。 それを実現するには学習および訓練データの作成においていくつかの工夫が行われており、また、構築したモデルを正確に評価するための工夫も行っています。
ここからは、本研究において特徴的な工夫である、以下の2点について説明します。
- 教科書品質の学習データ・訓練データを作成するための手法
- モデルの性能をより正確に評価するために採用した手法
1. 教科書品質の学習データ・訓練データを作成するための手法
教科書品質なデータとは何か
データの作成手法の前に、まずは本研究の最重要部分である「データの品質」について確認しておきます。本論文で定義されている”textbook-quality”なデータは以下の通り述べられています。
“textbook”: it should be clear, self-contained, instructive, and balanced.
つまり、本研究における「教科書品質なデータ」とは「明確で自己完結しており、教育的でバランスの取れたデータ」であることを意味します。
学習データの作成
上記を踏まえて、ここからは学習データの作成手法について説明していきます。 学習データには2つのデータセットを使っています。
学習データ 1:教科書品質のPythonコード
学習データにはThe StackとStackOverflowにあるPythonコードを使用しています。 しかし、これらのデータの品質はさまざまであり、上述した「教科書品質」に適していないデータも多く見られています。
具体的にどのようなものが教科書品質であり、そうでないのかを見ていきます。 下記の通り、左が品質の高いデータであり、右が品質の低いデータです。

これを見ると、左のコードの方が明確でわかりやすく、一方で右のコードはひたすら属性を定義しており、意味が理解できないコードになっていることがわかります。
このような違いが教科書品質であるかどうかという判断軸になります。
本研究ではこのような品質のレベル分けを、GPT-4を使って以下のようなプロンプトを与えることで評価させています。
”determine its educational value for a student whose goal is to learn basic coding concepts”
学習に使うデータは、このGPT-4の出力結果である値が高いものを選定しています。 結果として、合計約35Bトークンのデータから約6Bトークンのデータを選出しました。
学習データ 2:GPT3.5から生成した自然言語とPythonコードの合成データ
もう一つ学習に使用しているデータが、自然言語とPythonデータを組み合わせたデータ(合成データ)です。これはGPT-3.5から生成しています。
合成データとは以下のように、はじめに自然言語による指示文があり、その下に指示に対応したPythonコードが記述されているといった形式のデータのことです。

教科書品質のデータとは何かを振り返ると、「明確で自己完結しており、教育的でバランスの取れたデータ」という定義でした。 ここで、「バランスが取れた」という点に着目します。この点を本論文の表現を使って言い換えると、「偏りがなく多様性を持っている」という意味となります。
このように学習データに多様性を持たせる理由は、多様な問題や表現方法を学習させることで、特定のパターンに過学習させないようにして汎用的でロバスト性の高いモデルを作ることができるためです。
本論文では、GPT-3.5に多様性を持った合成データを生成させるにあたって、”How Small Can Language Models Be and Still Speak Coherent English?”という論文に着想を得たと述べられています。 この研究では、特定の語彙からランダムに選ばれた複数の単語をプロンプトに含め、それらが生成された適切に結合され、一貫性を持ったテキストとして出力する方法が言及されています。
この考え方を生かして、GPT-3.5からデータセットを生成する際に、トピックに制約を与えてデータを生成させることで、意図的に広く多様性を持たせたデータセットを作成したと述べられています。
訓練データの作成
訓練データにはGPT-3.5から生成したPythonの問題と回答を組み合わせた約180Mトークンのデータセットを使用しています。
形式としては以下のように、引数と戻り値が定義された関数名と指示が書かれた自然言語があり、その後に内部処理のコードが書かれています。ファインチューニングの際は関数名と指示文が入力であり、その関数を補完するようなコードが出力となります。
この出力部分の生成コードと正解コードの誤差(クロスエントロピー損失)が小さくなるようにパラメータをチューニングします。

以上が、本研究で行われている学習データ・訓練データを作成するための手法です。
2. モデルの性能をより正確に評価するために採用した手法
ここからは、本研究において特徴的であったもう一つの工夫である「モデルをより正確に評価するためにのアプローチ」について説明します。
モデルの正確な評価のためには以下の2つの方法を使っています。
- 新たな評価用タスクの作成とコードの論理評価
- 訓練データの刈り込み
1. 新たな評価用タスクの作成とコードの論理評価
前提として本論文では、HumanEvalやMBPPの評価方法について大きく2つの懸念を挙げています。
訓練データが評価用の問題と類似している可能性があること
上述したようにphi-1やphi-1-smallはファインチューニングによって性能を向上させましたが、そこには訓練データと評価用のデータが類似していることが影響している可能性があります。
コードの論理的な評価ができていないこと
HumaEvalやMBPPといったコード生成の評価は、関数を実行したときの結果が一致するか否かという点で評価を行っています。そのため、「論理的に大きく間違っているが、出力結果が偶然合っている」というものや、「論理的にほとんど正しいが、僅かな誤差で出力結果が誤っている」というものを正しく評価できないことを問題視しています。
これらの懸念に対して本研究では、実世界では求められないようなコード生成の問題を新たに50タスク作成し、そのデータを評価用として使用することとしました。 また、評価についてはGPT-4を使用して、生成されたコードに対して論理的な正しさを0から10までの段階評価を出力するようにプロンプトを与えることで評価を行いました。 その結果は以下の通りでした。
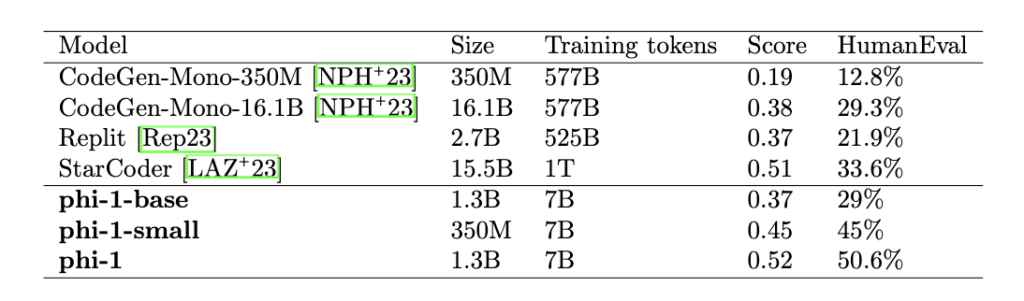
結果としては表のScoreの通りで、新たに作成したタスクに対しても、phi-1はStarCoderを僅かに上回る結果となりました。このことから、phi-1の性能の高さに妥当性があることが確認されました。
以上が評価方法の懸念に対して行った、新たな問題作成とGPT-4による評価についての説明です。
訓練データの刈り込み
モデルを正確に評価し、phi-1の性能の妥当性を確信に近づけるためにはもう一つ試みが行われています。それが「訓練データの刈り込み」です。 具体的には、訓練データに使うデータセットから、あらかじめHumanEvalの問題と類似したものを除くという方法です。 データの類似判定の方としては以下の2つの手法を使っています。
Embedding distance
これは埋め込みベクトルによって算出される距離のことです。 ここでは、CodeGen-Mono 350M model4というモデルから出力した埋め込みベクトルを使って二つのデータセットの類似度をベクトル空間におけるユークリッド距離で算出しています。
Syntax-based distances
これはコードを抽象構文木に構造化することによって算出される距離のことです。 抽象構文木5に構造化したコードの文字列に対して、編集や置き換えがどのくらい必要かによって構造的な距離を算出しています。
これら二つの類似度指標にそれぞれ閾値を設定することで、コード(ここでは訓練データセットとHumanEvalのデータセット)が「類似」か「非類似」かを判定しています。
結果として、HumanEvalに類似していると判定された約40%のデータセットを除いて再トレーニングした場合でも、phi-1はStarCoderより高い精度を出すことができました。

このようにモデルの精度を正確に評価するために「新たな評価用タスクの作成とコードの論理評価」や「訓練データの刈り込み」といった手法を試みた結果、phi-1の性能の高さは、訓練データが評価データに対する類似していたことよるものではないということが明らかにされました。
課題点
ここまでphi-1の性能の高さについて説明してきましたが、一方で本論文ではphi-1の課題点についても言及されています。
複雑なタスクへの対応に限界がある
phi-1はStarCoderのようなモデルと比較すると、Flaskなどを使った複雑なアプリケーション開発といったタスクには対応できないと述べられています。これはモデルが小さいことが起因していると考えられています。
長いプロンプトへの対応が苦手である
プロンプトの長さが長くなることで、プロンプトの一部を無視してコード生成が行われることがあると述べられています。これはphi-1の訓練データが主に短いプロンプトで構成されたデータで行われていることが理由だと考えられています。
曖昧な自然言語の処理が苦手である
プロンプトに曖昧な言葉が存在する場合に、それをうまく解釈することができないことがあると述べられています。ここでは例として”stay unchaged”という、やや曖昧な自然言語に対して適切にコードに落としこめていないことが挙げられていました。 これは学習するデータを選定する段階で、教科書品質である特定のデータを選定しているためだと考えられています。
以上のように、HumanEvalやMBPPといった評価指標では高い数値となりましたが、より実用的で複雑な問題については対応ができず、課題が残っていることも述べられています。
まとめ
本論文では、phi-1という言語モデルの開発を通して、データ数やパラメータ数を増大するのではなく、学習や訓練のデータを教科書品質に選定するというアプローチによって、Pythonのコード生成タスクにおいては、小さなモデルでも非常に高い精度を出すことが明らかにされました。
また、本論文ではこの結果を、データの品質向上によってスケーリング則の形状が変化し、少ないデータでも性能が大きく向上するようになったのではないかと、スケーリング則がより強力になったという捉え方もしています。
一方で、このような高品質なデータセットを作成することは容易ではなく、本研究でデータ生成に使用したGPT-3.5にも多くの誤りが見られたと述べられています。それでも高精度が出ていたことから、より優れた方法で高品質なデータを作成することができれば、自然言語処理とその関連分野をさらに大きく発展させていくだろうと述べられています。
結論の章では、データ品質について多様性と冗長性を評価するための優れた手法がまだないという懸念が挙げられています。言語モデルの生成結果が別の言語モデルの学習に使われるという構造を考えると、モデルの学習に使われたデータの偏りや多様性を、評価したり説明できるようにすることが早急に求められると述べられ、本論文が締めくくられました。
考察
データの品質を高めることで小規模でも性能の高いモデルを作ることができるという点は、非常に興味深いアプローチであり、こうした知見は私自身が実験するファインチューニングなどの言語モデルのカスタマイズの部分で役に立つと考えられました。 一方で、限定された少量データセットにすることで、他のモデルよりも汎用性が低いことも明らかになっているため、実世界にある曖昧で複雑なタスクに対する適用するにはまだ課題があると考えられました。
私は、本研究で特に重要な点は「高品質なデータをどのように定義して作成するか」であるだと考えます。特定の目的に沿ったモデルを作ったり訓練をする場合に、どのようなデータセットがあるべきなのかを設計し、それをどのように生成していくかという点で、本研究は多くの示唆を提供しています。
また、本研究における「教科書品質のデータ」の定義の中で、特に興味深いと感じたのは「バランスの取れたもの」つまり「偏りがなく多様性を持っている」という点です。これは機械学習的な視点で考えると、予測タスクにおける汎化性能を高めるという目的があるため妥当なアプローチです。
生成AI(特にLLM)においても同じように、「偏りのある生成をする」ということは問題視されますが、将来的に私たちの生活に当たり前のように生成AIが関わってくる可能性を考えると、生成AIにおけるこのような「偏りのある生成」は、想像以上に大きな問題であると考えられます。
生成AI(特にLLM)においては、単に「予測精度を上げる」という観点だけでなく、倫理的な観点も踏まえて「偏りがなく多様性を持っている」という点が重要であることを、本論文を通して再認識することができました。
1https://github.com/openai/human-eval, https://huggingface.co/datasets/openai_humaneval
本文へ戻る
2Program Synthesis with Large Language Models, https://huggingface.co/datasets/mbpp
本文へ戻る
3https://huggingface.co/blog/starcoder
本文へ戻る
4https://huggingface.co/Salesforce/codegen-350M-mono
本文へ戻る
5https://en.wikipedia.org/wiki/Abstract_syntax_tree
本文へ戻る
参考
- Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.
- Ronen Eldan, Yuanzhi Li. 2023. TinyStories: How Small Can Language Models Be and Still Speak Coherent English?