
はじめに
データソリューション事業部の宮澤です。
近年、LLMに関する技術は目覚ましく発展しており、最近では日本語に特化したLLMの開発や公開も増えてきました。 2023年8月10日にはStability AI Japanから、日本語に特化したLLMであるJapanese StableLM Alphaが公開されました。このモデルはこの時点で公開されていた同規模の日本語モデルよりも高い性能であると報告されており注目を集めています。 Japanese StableLM Alphaでは、モデルに使われている技術の一部が公開されており、日本語と英語を効率的かつ効果的に処理するためにトークナイザーにNovelAIのnovelai-tokenizer-v1(以下 NovelAI Tokenizerとする)を使用していると報告されています。
また、2023年8月29日にはELYZAからLlama 2をベースとして日本語向けに追加学習を行なったELYZA-japanese-Llama-2-7bが公開されました。同モデルでは、追加の事前学習においてトークナイザーの改良を行ったことが報告されています。
このことから、LLMの日本語処理の性能を高めるための工夫の一つとして「トークナイザーションの最適化」が挙げられると仮説を立てました。本記事では、トークナイザーションの基礎理論から始め、上に挙げた2つの日本語LLMにおけるトークナイザーの工夫を紐解くことで、日本語処理においてトークナイザーを最適化することの重要性を明らかにしました。
日本語LLMについて
本記事では、日本語を処理することを目的として日本語のテキストデータを使って学習、もしくはカスタマイズしたLLMを「日本語LLM」と定義します。
日本語LLMとしてはJapanese StableLM AlphaとELYZA-Japanese-Llama-2-7bの2つのモデルを取り上げます。以下のモデル概要については公式のリリースページ1およびHuggingFaceの各モデルページ2を参照しています。
Japanese StableLM Alpha
Japanese StableLM Alphaは、Stability AI Japanが公開した日本語に特化したLLMです。 公開されたモデルは以下の2つです。
- Japanese StableLM Base Alpha 7B
- Japanese StableLM Instruct Alpha 7B
Japanese StableLM Base Alpha 7B
日本語タスクに対するパフォーマンスを最大化するように学習されたモデルであり、Apache License 2.0で公開されている、商用利用も可能なモデルです。
Japanese StableLM Instruct Alpha 7B
Baseモデルに指示応答のファインチューニングを行ったモデルであり、研究目的での利用に限定されています。
モデルの概要
Japanese StableLM AlphaはTransformerをベースとしたモデルです。 モデルの構築にはGPT-NeoX3という、DeepSpeed4を使った大規模言語モデルの訓練用ライブラリが使用されています。パラメータ数は約7B(70億)と、サイバーエージェントが公開しているOpenCALMの最大モデルと同程度の大きさです。
学習データ
約750B(7,500億)トークンで事前学習されており、学習データには以下のようなデータセットが利用されています。5
| データセット | 詳細 |
|---|---|
| Japanese/English Wikipedia | 日本語と英語のWikipediaのデータ。 |
| Japanese mc4 | Googleのmc4(Webコーパス)をallenaiが前処理した日本語部分のデータセット。 |
| Japanese CC-100 | Meta Research製のCC-Netを使ってWebクロールデータから抽出した日本語のデータセット。 |
| Japanese OSCAR | mc4、CC-100と同様にCommon Crawlから収集した日本語データセット。 |
| RedPajama | Common Crawl、Github、ArXivなど7つのソースから構成されたデータセット。 |
ELYZA-Japanese-Llama-2-7b
ELYZA-Japanese-Llama-2-7bは、ELYZAが公開した日本語に特化したLLMです。
公開されたのは以下のモデルです。
- ELYZA-japanese-Llama-2-7b
- ELYZA-japanese-Llama-2-7b-fast
- ELYZA-japanese-Llama-2-7b-instruct
- ELYZA-japanese-Llama-2-7b-fast-instruct
instruct:instruction tuningによって追加学習されたモデル。
fast:日本語の語彙の追加によって処理を高速化したモデル。
モデルの概要
ELYZA-japanese-Llama-2-7bはLlama2をベースとして日本語処理の性能を向上させるために追加学習したモデルです。英語で学習済みのLLMの言語能力を引き継ぐことで、少ない日本語データでも日本語処理に優れたモデルを作ることができるのではないかという仮説のもとモデルが改良されています。日本語向けに追加学習を行うにあたっては、トークナイザーの改良も行われています。 パラメータ数は約7B(70億)と、Japanese StableLM AlphaやOpenCALMの最大モデルと同程度の大きさです。
学習データ
Japanese StableLM Alphaと同様にOSCARやWikipediaなどに含まれる日本語データを、ベースのLlama2に追加で約180億トークン学習させています。
モデル評価
これらのモデルの性能の評価は、EleutherAIのlm-evaluation-harness6にStability AI Japanが中心となり日本語のタスクを追加した評価指標で測定されています。文章分類、文ペア分類、質問応答、文章要約などの合計8タスクで評価が行われています。
| model | average | jcommonsenseqa | jnli | marc_ja | jsquad | jaqket_v2 | xlsum_ja | xwinograd_ja | mgsm |
|---|---|---|---|---|---|---|---|---|---|
| stabilityai-japanese-stablelm-instruct-alpha-7b | 54.71 | 82.22 | 52.05 | 82.88 | 63.26 | 74.83 | 7.79 | 72.68 | 2 |
| ELYZA-japanese-Llama-2-7b | 53.47 | 75.6 | 50.66 | 87.57 | 71.43 | 58.85 | 4.16 | 71.85 | 7.6 |
| ELYZA-japanese-Llama-2-7b-instruct | 53.11 | 65.15 | 57.27 | 91.51 | 67.38 | 58.51 | 5.02 | 70.07 | 10 |
| stabilityai-japanese-stablelm-base-alpha-7b | 51.06 | 33.42 | 43.34 | 96.73 | 70.62 | 78.09 | 10.65 | 72.78 | 2.8 |
| rinna-bilingual-gpt-neox-4b-instruction-sft | 47.75 | 49.51 | 47.08 | 95.28 | 55.99 | 61.17 | 5.51 | 64.65 | 2.8 |
| llama2-7b | 42.96 | 52.64 | 28.23 | 86.05 | 58.4 | 38.83 | 9.32 | 64.65 | 5.6 |
| llama2-7b-chat | 41.31 | 55.59 | 29.54 | 90.41 | 59.34 | 17.96 | 2.34 | 66.11 | 9.2 |
| cyberagent-open-calm-7b | 38.8 | 24.22 | 37.63 | 74.12 | 45.79 | 60.74 | 2.04 | 65.07 | 0.8 |
どちらのモデルも、その他のモデルより日本語処理の平均的な性能評価が高いことがわかります。
本記事で取り上げるポイント
本記事ではこれらの日本語LLMをもとに、日本語処理のためのトークナイゼーションの最適化について掘り下げていきます。
Japanese StableLM Alphaにおいては、日本語と英語を効率的かつ効果的に処理するために使用されているNovelAI Tokenizerの特徴を明らかにし、ELYZA-japanese-Llama-2-7bにおいてはfastモデルに適用されているトークナイザーの改良点を明らかにしていきます。
トークナイゼーションとは
それぞれの日本語LLMを見ていく前に、トークナイゼーションの理論について説明します。
トークナイゼーションとは、簡潔に言えば「与えられたテキストをトークン単位で分割すること」です。トークナイザーとはトークナイゼーションを行うモデルのことを意味します。
自然言語処理においては、テキストの中で一つの意味を表す文字の並びのことを「トークン」と呼びます。テキストをベクトルで埋め込み表現する際には、この「トークン」を単位にして処理が行われます。
例えば、”I am a Data Scientist.”というテキストに対しては、以下のようなトークナイゼーションが考えられます。
- I | am | a | Data Scientist | .
- I | am | a | Data | Scientist | .
- I | am | a | Data | Scien | tist | .
- I | am | a | Data | Sci | en | tist | .
このように、トークナイゼーションのパターンはいくつも考えられますが、適切な大きさでトークン化を行うことが言語モデルの精度向上につながります。
トークナイゼーションの前提
具体的な手法を見ていく前に、理解しておくべき前提を説明しておきます。
トークナイゼーションの段階について
大まかに、トークナイゼーションは以下の二つの段階に分けて考えられます。
- トークナイザーの学習:テキストを分割するために使用する語彙またはルールを作成する。
- トークナイザーによる推論:作成された語彙またはルールをもとに、与えられたテキストをトークン化する。
要するに、学習データをもとにトークナイザーというモデルを構築し、そのモデルを使って実際にトークン化を行うということです。これを念頭に置いて、トークナイゼーションを深掘りしていきます。
語彙の大きさについて
大規模言語モデルの処理ではあらかじめ作成された語彙やルールに従ってトークナイゼーションを行うため、語彙に含まれていない文字列は未知語となり、モデルの中で適切に扱うことができません。 そのため、トークナイゼーションでは多くの単語に対応できるように、ある程度の語彙のサイズが必要となってきます。
ただし、この語彙のサイズはモデルの精度と大きく関わっており、大きすぎても小さすぎてもよくないという点に注意が必要です。
語彙サイズが大きすぎる場合
これは一般的には出現しないような単語も語彙に含めるような場合です。 この場合、極めて低頻度の出現単語についても出力確率を計算する必要があるため、計算コストやメモリ容量に負荷がかかる上、言語モデルの性能にも悪影響を及ぼします。
語彙サイズが小さすぎる場合
これは一般的によく使う単語のみ語彙に含めるような場合です。 この場合、語彙に含まれずに対応できない未知語が増え、モデルの性能が低くなります。
ここで、単語ではなく文字単位で処理してしまう(例えば”science”を[ “s”, “c”, “i”, “e”, “n”, “c”, “e” ] と分割する)という方法もありますが、この方法では扱う単位が細かすぎて言語モデルでの学習が難しくなるという問題があります。
サブワード分割
語彙の大きさに関する課題を解決するために現在標準となっている処理の方法が、単語分割と文字分割の中間となる「サブワード」という単位での分割です。
これは例えば”scientist”を[ ”scien”, “tist” ]と分割するように、単語の中でもさらに細かい単位に分割する方法です。このようなサブワードによる分割は、言語モデルで処理をするのに最適な粒度での語彙を獲得します。
例えば「大規模言語モデル」という単語が直接的に語彙に含まれていなくても、「大」「規模」「言語」「モデル」というサブワードがあれば、サブワードの組み合わせで「大規模言語モデル」という単語を形成できます。このことから、サブワードでの分割は言語モデルが未知語への対応をする際に効果的に機能すると言えます。
サブワード分割を行い語彙を作成する手法にはいくつかあり、同じ文字列が与えられたとしても、アルゴリズムによってトークナイゼーションの結果は異なります。
トークナイゼーションの基本的な手法
ここからはトークナイゼーションの具体的な手法について説明し、それぞれの手法がどのようにサブワード分割を行うのかを説明します。
BPE(Byte-Pair Encoding)
これは「バイト対符号化」と呼ばれる手法です。 文字単位での分割をした状態から、隣接する文字同士を結合していくことによって行われる、データ圧縮の手法の一つです。
BPEでは、テキストをすべて1文字単位に分割してから、隣り合う文字の頻度が高いものを結合する過程を通してテキストの結合ルールを作ります。実際に与えられたテキストに対してはこの結合ルールをもとにトークン化を行います。
例えば、”scientist analyst strategist stylist”というテキストを2回結合する場合、以下のようになります。
初期状態
初めは文字ごとに分割されています。
s c i e n t i s t
a n a l y s t
s t r a t e g i s t
s t y l i s t
1回目の結合
ここで最も高頻度で隣接する文字が結合されます。 ここでは”s”, “t”という隣接が計4回で最も多いため、これを結合します。
s c i e n t i st
a n a l y st
s t r a t e g i st
s t y l i st
2回目の結合
同様に高頻度で隣接する文字が結合されます。 ここでは”i”, “st”という隣接が3回と多いため、これを結合します。
s c i e n t ist
a n a l y st
s t r a t e g ist
s t y l ist
これをあらかじめ指定した回数だけ結合していきます。(実際には語彙サイズを文字単位で分割したときの文字数 + 結合回数をハイパーパラメータとして設定します。)
この結果、”i” “s” “t”の文字並びは”ist”という一つのサブワードにするという結合ルールが作られます。3つの文字を一つのサブワードで表現できるようになったことから、データが圧縮されているイメージが掴めるかと思います。
このように学習データから隣接頻度をもとに作った結合ルールを用いて、例えば”scientist”を[ ”sci”, “en”, “tist” ]と分割するように、文字単位よりは大きく単語単位よりは小さなサブワードとして分割する手法がBPEです。
WordPiece
次にWordPieceという手法についてです。これはBERTで採用されたサブワード分割の手法です。7
手法はBPEと似ていますが、サブワードを結合する際の基準として単純な隣接頻度ではなく、結合前のサブワードの出現頻度を加味したスコアを使っています。
\[score = \frac{サブワードの組み合わせ頻度}{(一つ目のサブワードの出現頻度 \times 二つ目のサブワードの出現頻度)}\]
これによって、出現頻度の高いサブワードで構成される組み合わせよりも、頻度が低いサブワードで構成されるレアな組み合わせの結合が優先されます。
また、WordPieceはトークナイザーの推論(与えられたテキストに対するトークン化)の方法においても、BPEとは異なった方法が使われています。以下でトークン化の具体的な流れを説明します。
例として、トークナイザーの学習によって得られた語彙が[ “s”, “c”, “##i”, “##e”, “t”, “sci”, “##en”, “##tist” ]であるとします。(WordPieceは単語区切りが前提となっており、単語の先頭文字であることを表現するために、先頭ではない文字に対しては「#」を付与しています。)
トークン化の流れ
- 与えられた文字列を単語で区切ります。
例)ここでは”scientist”という文字列が与えられたとします。 - 単語が語彙に含まれるか探します。語彙にあればそこで分割します。
例)語彙は[ “s”, “c”, “##i”, “##e”, “t”, “sci”, “##en”, “##tist” ]であるため”scientist”は含まれていません。 - 語彙になければ先頭文字が一致するサブワードで最長のものを探します。
例)”s”から始まる最も長いサブワードを探すと、”sci”が語彙に含まれる中で最も長いサブワードであるとわかります。 - 3で見つけたサブワードの終了位置で文字列を分割します。
例)”sci”で分割するため、”scientist” → [ “sci”, “##entist”]となります。 - 分割した後ろの文字列から2番以降の分割を繰り返します。
例)”##entist”からも同様にサブワードで分割すると、最終的に[ “sci”, “##en”, “tist” ]と分割されます。
以上が、WordPieceによるトークナイゼーションです。
日本語におけるトークナイゼーション
基本的な手法を押さえたところで、ここからは日本語におけるトークナイゼーションを考えていきます。
ここまで紹介したBPEやWordPieceは、単語以上の大きさには結合されないように、あらかじめ単語単位で分割されていることが前提となっています。
しかし、日本語におけるトークナイザーションでは、日本語は空白で単語が区切られていない(分かち書きされていない)ため、単語の分割位置が分からないという問題が発生します。
これを解決する方法として2つの方法があります。
- 形態素解析を使う方法
- Sentencepieceを使う方法
1. 形態素解析を使う方法
これは、空白で区切られていない日本語の単語を分割するために、Mecabなど形態素解析器でテキストを事前に分割してから、BPEやWordPieceなどのバイト対符号化を使う方法です。
東北大学のbert-base-japanese-v38ではこの方法が使われており、Mecabによる形態素解析を行ってから、WordPieceによるサブワード分割を行っています。
実際に日本語のテキストを処理すると以下のような結果となります。
# トークナイザーの指定
bert_japanese_tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-v3")
# トークナイズ
input_text = '大規模言語モデルは社会をどのように変えるのだろうか。'
output_token = bert_japanese_tokenizer(input_text)
# トークンIDをサブワードに変換
tokens = bert_japanese_tokenizer.convert_ids_to_tokens(output_token['input_ids'])
print(tokens)# 出力結果
['[CLS]', '大', '規模', '言語', 'モデル', 'は', '社会', 'を', 'どの', 'よう', 'に', '変える', 'の', 'だろう', 'か', '。', '[SEP]']このように日本語のテキストに対して、単語よりは小さく文字よりは大きい適度なサブワードとして分割できていることがわかります。
2. SentencePieceを使う方法
形態素解析によって単語を事前分割する方法は日本語においては有効ですが、日本語に対する形態素解析器は他の言語には活用できないため、この方法は言語依存性があると言えます。それぞれの言語によって異なる性質を持っているため、複数の言語を扱う言語モデルの場合には言語依存性は避けたい問題です。
こうした問題を解決する手法がSentencePieceです。 SentencePieceはGoogleによって公開されているオープンソースのトークナイザーです。9 この手法は、テキストを事前に単語で区切るのではなく、分割方法そのものを生の文章から直接学習するというアイデアで作られています。
SentencePieceの処理
”Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates”(Kudo, 2018b)によると、SentencePieceには以下のような処理があります。
- Unicode Normalization
- Trainer
- Encoder
- Decoder
一つずつ説明していきます。
Unicode Normalization
これはSentencePieceの前処理のようなものであり、テキストをUnicodeに変換する作業です。
テキストをそのまま処理するのではなく、国際的な標準規格であるUnicodeに沿って標準化して処理することで、言語依存性を低くする効果があります。
SentencePieceのデフォルトではUnicode NFKCが使われています。
Unicode NFKCとはUnicodeの種類の一つであり、「互換等価」で文字を分解し「再合成」する正規化処理です。10
互換等価とは
「互換等価」とは、ある特定の文字に対して異なるスタイルや全半角の違いに関係なく等価であるとすることです。以下のコードで実際に確認します。
# 正準等価(NFC, NFD)と互換等価(NFKC, NFKD)の違い
import unicodedata
char_hankaku = "1"
char_zenkaku = "1"
print("対象文字:", "「1(半角)」", "「1(全角)」\n")
forms = ["NFC", "NFD", "NFKC", "NFKD"]
types = ["正準等価", "正準等価", "互換等価", "互換等価"]
# Unicode正規化(変換方法はutf-8を使用)
for form, type in zip(forms, types):
encoded_hankaku = unicodedata.normalize(form, char_hankaku).encode("utf-8")
encoded_zenkaku = unicodedata.normalize(form, char_zenkaku).encode("utf-8")
print(f"【{form}({type})】文字コード 半角:", encoded_hankaku, "全角", encoded_zenkaku)# 出力
対象文字: 「1(半角)」 「1(全角)」
【NFC(正準等価)】 半角: b'1' 全角 b'\xef\xbc\x91'
【NFD(正準等価)】 半角: b'1' 全角 b'\xef\xbc\x91'
【NFKC(互換等価)】 半角: b'1' 全角 b'1'
【NFKD(互換等価)】 半角: b'1' 全角 b'1'Unicodeの4つの種別で比較してみると、互換等価性のあるUnicode NFKCとNFKDは全角と半角の数字を同じものとして扱っていることがわかります。これには、テキストに視覚的な違いがあっても意味は同じものであるとして捉えられるというメリットがあります。
再合成とは
「再合成」とは基底文字と結合文字(濁点など)を結合して一つの合成文字として結合することです。こちらも同様に以下のコードで確認してみます。
# 再合成(NFC, NFKC)と非再合成(NFD, NFKD)の違い
char_ke = "け"
char_ge = "げ"
print("対象文字:", f"「{char_ge}」\n")
types = ["再合成あり", "再合成なし", "再合成あり", "再合成なし"]
# Encode
print("【原型】文字コード:", char_ke.encode("utf-8"), "\n")
# Unicode正規化(変換方法はutf-8を使用)
for form, type in zip(forms, types):
encoded = unicodedata.normalize(form, char_ge).encode("utf-8")
print(f"【{form}({type})】文字コード:", encoded)# 出力
対象文字: 「げ」
【原型】文字コード: b'\xe3\x81\x91'
【NFC(再合成あり)】 b'\xe3\x81\x92'
【NFD(再合成なし)】 b'\xe3\x81\x91\xe3\x82\x99'
【NFKC(再合成あり)】 b'\xe3\x81\x92'
【NFKD(再合成なし)】 b'\xe3\x81\x91\xe3\x82\x99'これを見ると、Unicode NFCとNKFCは「け」と濁点を一つの文字として再合成を行なっていることがわかります。
このようにUnicode NFKCはテキストデータの一貫性を保つような特性があります。原著論文では、この正規形が再現性が高く強力な標準化であることから、SentencePieceだけでなく自然言語処理において広く使われていると述べられています(Kudo, 2018b)。
Trainer
トークナイザーの学習の前処理がわかったところで、次はトークナイザーの学習プロセスを見ていきます。上述したように、SentencePieceでは事前に単語単位での分割といったことはせず、テキストから直接学習を行うことで、サブワード分割した語彙を作成します。
SentencePieceではBPEに加えてUnigramという手法をサポートしており、デフォルトではこのUnigramが使われています。
Unigramはサブワードの分割パターンが決定的ではなく確率的であると考える点でBPEと異なっています。これによって複数のサブワード分割のパターンを生成することができます。
Unigramについて理解を深めるために、全体の流れを見ていきます。
Unigramは、BPEのように結合によってサブワードを作っていく流れとは逆のアプローチで、まず初めに大きなサイズの語彙を用意しておき、そこから語彙を絞っていきます。
例えば”data scientist”というテキストを分割する場合、初期語彙としては以下のようにあらゆる分割のパターンを持った大きな語彙であるとします。(この初期語彙の作成にはEnhanced Suffix Array algorithmが使われており、このアルゴリズムを使って高頻度で出現するサブワードから初期語彙を構築します。)
初期語彙の例
[ “d”, “a”, “t”, “s”, “c”, “i”, “e”, “n”, “da”, “at”, “ta”, “sc”, “ci”, “ie”, “en”, “nt”, “ti”, “is”, “st”, “dat”, “ata”, … ]
次に学習テキストにおける各サブワードの出現確率を計算します。Unigramでは各サブワードの出現は独立であるとしているため、テキスト全体の出現確率は以下のように、各サブワードの出現確率の掛け算で表現されます。ここでxベクトルは、ある分割パターンにおけるサブワードのリストを表しています。
\[\begin{align*} P(\mathbf{x}) &= \prod_{i=1}^{M}p(x_i)\\ \mathbf{x} &= [x_1,…, x_M] \end{align*}\]
これを踏まえ、テキストに対して複数のサブワード分割パターンがある中で、確率を最も高くするものが最適であるとします。(実際には対数尤度をもとにした損失計算を行う形になります。)
\[\mathbf{x}^* = \underset{\mathbf{x} \in S(X)}{\mathrm{argmax}} P(\mathbf{x})\]
例えば、初期語彙が[ “d”, “a”, “t”, “da”, “ta” ]であり、テキスト内での出現確率が、以下の通りであるとします。
\[\begin{align*} p(d) = 0.2,\quad p(a)=0.2, \quad p(t) = 0.1,\quad p(da) = 0.05, \quad p(ta) = 0.02 \end{align*}\]
サブワードの与えられた確率を使って、”data”というテキストの分割パターンを2つ作ることを考えると、それぞれの分割パターン対する対数尤度は以下のように計算されます。
\[\begin{align*} L_i = \log{(P_i(\text{data}))} &= \log{(p(d))} + \log{(p(a))} + \log{(p(t))} + \log{(p(a))} \\ &= \log0.2 + \log0.2 + \log0.1 + \log0.2 \\ &= -7.1309 \ldots \\ L_j = \log{(P_j(\text{data}))} &= \log{(p(da))} + \log{(p(ta))} \\ &= \log{0.05} + \log{0.02} \\ &= -6.9078 \ldots \end{align*}\]
この場合、”data”というテキストは[ “da”, “ta” ]と分割する方が対数尤度が大きいため、こちらの分割方法がより適していると判断されます。
Unigramでは上記のような考え方を基にして、EMアルゴリズムを使って分割パターンに対する対数尤度を最大化するようにサブワードの生起確率を更新していきます。また、その過程で各サブワードに対して、それぞれのサブワードを語彙から削除した場合に発生する損失の大きさを計算します。その結果として損失が小さいサブワード(語彙から削除しても影響が小さいもの)を一定の割合で語彙から削っていきます。これを既定の語彙の大きさになるまで繰り返します。
このようなプロセスで、最終的には既定の大きさの語彙と、各サブワードに対する出現確率が算出されます。(例えば[ “da”: 0.04, “ta”: 0.03, “sci”: 0.08, … ]という結果になります。)
ここまでがSentencePieceベースでUnigramを使った場合のトークナイザーの学習プロセスです。
Encoder
ここからは、学習によって得た語彙と各サブワードに対する確率を使用して、与えられたテキストをエンコード(トークン化)する方法ついて見ていきます。 引き続きUnigramアルゴリズムを使っているという仮定で説明していきます。
Unigramを使う場合、エンコードの方法は2あります。
- 最も確率が高い形で決定的にトークン化する方法
- いくつかトークン化のパターンをサンプリングしてそこから一つのパターンを選択する方法
1の場合は毎回同じエンコーディング結果となり、2の場合は確率分布に対する操作を行うことでランダム性のあるエンコーディング結果となります。
簡単な例を見ていきます。
ここではSentencePieceを使って、青空文庫11から取得した夏目漱石の「こころ」を語彙サイズ3,000に指定して学習したUnigramのトークナイザーを作ります。
# ライブラリのインストール
!pip install sentencepiece
# テキストの読み込み
import sentencepiece as sp
os.chdir(directory)
input_file = "kokoro_utf-8.txt"
model_prefix = "model_kokoro" # モデル名
vocab_size = 3000 # 語彙サイズ
character_coverage = 0.9995 # 使用する文字のカバレッジ
model_type = 'unigram'
# モデルの学習
sp.SentencePieceTrainer.train(
f"--input={input_file} --model_prefix={model_prefix} --vocab_size={vocab_size} --character_coverage={character_coverage} --model_type={model_type}"
)1の方法(最も確率が高い形で決定的にトークン化する方法)で「私は私自身さえ信用していないのです。」というテキストをエンコードすると以下のように一つの分割パターンが出力されます。
# modelのロード
sp_processor = sp.SentencePieceProcessor()
sp_processor.load(f"{model_prefix}.model")
# テキスト
text = "私は私自身さえ信用していないのです。"
# encode
encode = sp_processor.encode_as_ids(text)
# decode
decode_sentence = []
for encode_subword in encode:
decode_subword = sp_processor.decode(encode_subword)
decode_sentence.append(decode_subword)
print("トークン化結果:", decode_sentence)# 出力
トークン化結果: ['私は', '私', '自身', 'さえ', '信用', 'して', 'い', 'ないのです', '。']一方で2の方法(いくつかトークン化のパターンをサンプリングしてそこから一つのパターンを選択する方法)でエンコードすると以下のようになります。ここでscoreは対数尤度を表しており12、5つのサンプルを出力したなかで最も対数尤度が高い分割パターンを出力することとしています。
# modelのロード
sp_processor = sp.SentencePieceProcessor()
sp_processor.load(f"{model_prefix}.model")
# テキスト
text = "私は私自身さえ信用していないのです。"
# encode sampling
encode_scores = sp_processor.sample_encode_and_score(text, num_samples=5, alpha=0.1, out_type=str, wor=False)
[print(encode_score) for encode_score in encode_scores]
print("\n")
# best score
best_sampled_encoding, best_score = sorted(encode_scores, key=lambda x: x[1], reverse=True)[0]
best_sampled_ids = [sp_processor.piece_to_id(piece) for piece in best_sampled_encoding]
print(f"Best Score: {best_score}")
# decode
decode_sentence = []
for encode_subword in best_sampled_ids:
decode_subword = sp_processor.decode(encode_subword)
decode_sentence.append(decode_subword)
print("トークン化結果:", decode_sentence)# 出力
(['▁', '私は', '私', '自', '身', 'さえ', '信用', 'し', 'ていない', 'のです', '。'], -5.717618465423584)
(['▁', '私', 'は', '私', '自身', 'さえ', '信用', 'して', 'い', 'ない', 'ので', 'す', '。'], -6.453094959259033)
(['▁私は', '私', '自身', 'さ', 'え', '信', '用', 'し', 'ていない', 'の', 'で', 'す', '。'], -6.51542329788208)
(['▁私は', '私', '自身', 'さ', 'え', '信用', 'して', 'い', 'な', 'い', 'の', 'で', 'す', '。'], -6.3586602210998535)
(['▁私', 'は', '私', '自身', 'さえ', '信用', 'して', 'い', 'な', 'い', 'のです', '。'], -5.6336212158203125)
Best Score: -5.6336212158203125
トークン化結果: ['私', 'は', '私', '自身', 'さえ', '信用', 'して', 'い', 'な', 'い', 'のです', '。']ここで、サンプリングの確率分布の散らばり度合いは、sample_encode_and_score関数のalphaという引数で設定しています。引数alphaは”inverse temperature for sampling”と定義されており、Unigramに関する論文では”A smaller α leads to sample xi from a more uniform distribution. A larger α tends to select the Viterbi segmentation.”と説明があります。(Kudo, 2018a)
つまり、alphaが小さいとあらゆる分割パターンが均一な分布で幅広くサンプリングされ、alphaが大きいと元の確率が高い分割パターンが決定的にサンプリングされやすくなるということです。(実際にalpha=10にした場合、全く同じ5つのサンプルが得られました。)
このようにUnigramでは、決定的ではなく確率的なエンコーディングをすることで、同じテキストに対して異なったトークン化結果を得ることもできます。 これはニューラルネットワークにおけるドロップアウトの考え方と似ており、ランダム性を付与することでノイズを加えて過学習を防ぎ、言語モデルのロバスト性を高める効果があります。
Decoder
最後にエンコードされた情報をテキストに変換するデコードについてです。 SentencePieceは言語依存性の問題を解決すると述べましたが、それはエンコーダとデコーダの可逆性にあると言えます。
可逆性という観点で重要なのが、英語などの言語における単語間の空白の処理です。 Unicode Normalizationの説明部分では割愛しましたが、SentencePieceでは前処理としてUnicode正規化処理に加えて、空白の文字列化を行います。例えば、”Hello World.”という文字列は”Hello_world.”に変換します
これによってエンコーダとデコーダの可逆性が成り立つ理由を見ていきます。
例えば以下のようにテキストをトークン化することを考えます。
”Hello World.” → [ Hello, Wor, ld, . ]
“こんにちは世界。” → [ こんにちは, 世界, 。 ]
これをデコードする場合、日本語では単純にトークンをつなげて、”こんにちは世界。”とすればエンコード前とデコード後の可逆性を保った変換ができます。
しかし英語の場合は”Hello”と”World”の間に空白を入れるべきところが、トークン化した結果にそのような情報は存在しないため、正しくスペースを入れてデコードすることができません。
そこで今度はスペースの文字列化を行った場合として、以下のようなトークン化を考えてみます。
“Hello World.” → ”Hello_World.” → [ Hello, _Wor, ld, . ]
“こんにちは世界。” → [ こんにちは, 世界, 。 ]
これをもとにしてデコードの際に以下のような操作を加えます。
detokenized = ''.join(pieces).replace('_', ' ')そうするとデコード結果は以下のようになります。
[ Hello, _Wor, ld, . ] → “Hello World.”
[ こんにちは, 世界, 。 ] → “こんにちは世界。”
このように空白をアンダースコアに変換して文字列として扱うことで、エンコード前のテキストの再現性を高めることが可能になります。このことは言語特有の性質に対する依存性を減らすことにつながり、多言語対応の言語モデルを作ることに役立ちます。
以上が、SentencePieceにおけるデコードの工夫です。
SentencePieceの効果
ここまで説明してきたSentencePieceを使うことで、実際に言語処理の精度は上がるのでしょうか。
Kudo(2018b)によると、日本語と英語間の翻訳タスクにおいて、異なるトークン化を行った場合のBLEUスコア13を比較した検証を行ったと述べられており、以下がその検証結果です。
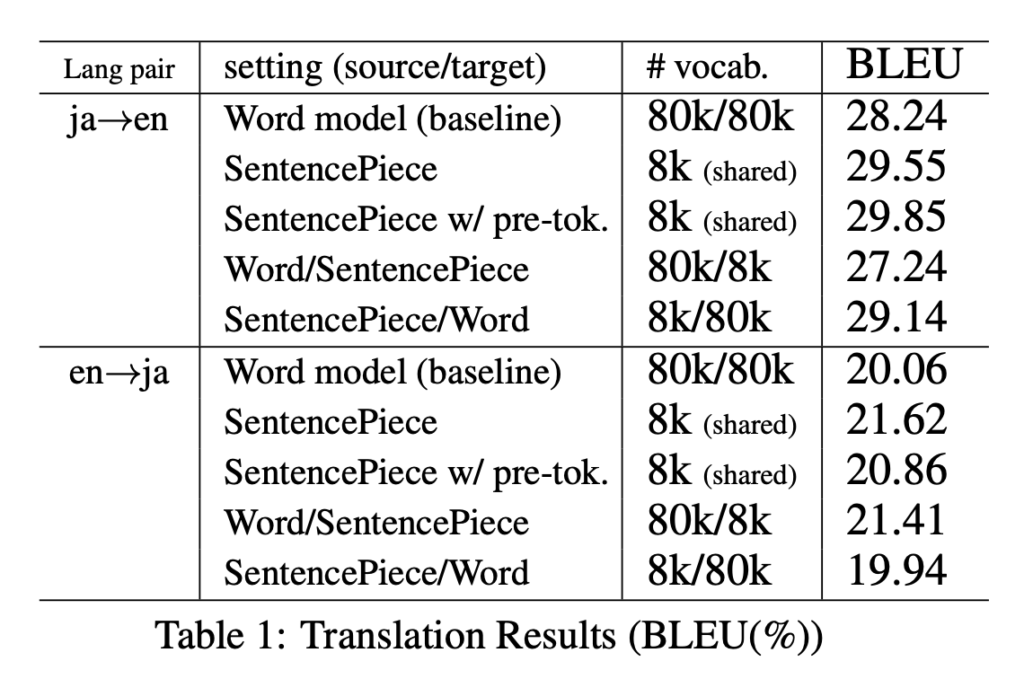
これを見ると、英語→日本語と日本語→英語のどちらの形でも、単語区切りのWord modelよりもSentencePieceでサブワード分割をしたときの方がBLEUスコアが高いことがわかります。 また、言語ごとに別の処理をした場合について見てみると、特に日本語に対してSentencePieceを適用した場合にBLEUスコアが高くなっていることがわかります。
このことから、日本語という単語区切りになっていない言語に対してSentencePieceを使ってトークナイゼーションを行うことは、機械翻訳等を行う言語モデルの精度を向上させることにつながるということがわかります。
日本語特化LLMにおけるトークナイザー
ここまでトークナイザーションにおける基礎理論を説明してきました。 この理論を踏まえて、ここからは日本語特化LLMにおけるトークナイザーでどのような工夫がされているのかを明らかにしていきます。
本記事で明らかにしたい点を振り返ると、以下の2つを挙げていました。
- Japanese StableLM Alphaに使用されているNovelAI Tokenizerの特徴
- ELYZA-japanese-Llama-2-7bのfastモデルに施されたトークナイザーの改良点
これらを一つずつ紐解いていきます。
1. NovelAI Tokenizerの特徴
ここでは、NovelAIのGithubでの説明文14をもとにその特徴を明らかにしていきます。
NovelAIが重視するポイント
本文書によると、トークナイザーを考えるにあたって重要な点として以下の点が挙げられています。
- 語彙のサイズ
- トークナイザーのタイプ
- 圧縮率
語彙のサイズとトークナイザーのタイプについては、言語モデルの精度に影響を与える重要な点であることを本記事でも述べてきました。ここでは、もう一つのポイントである「圧縮率」について、重要とされる理由を説明します。
ここまで述べてきたように、トークナイゼーションは与えられたテキストを適切な大きさに分割することにより、各サブワードが言語モデルで適切に処理されることを目指します。言語モデルでは一度に処理できるトークン数に上限があるため、元のテキストをどのくらい効率的に圧縮することができるかによって、処理できる情報量が変わってきます。そのため、より少ないトークンで多くのテキストを処理する効率(圧縮率)は、トークナイザーにおける重要な点であると言えます。
一方で単純に圧縮率を高めることだけを考えると、できるだけ大きな単位でトークン化することになってしまい未知語に対する処理などの汎用性が下がるため、圧縮率と汎化性能のバランスには注意する必要があります。
特徴
上記のポイントを踏まえて、NovelAI Tokenizerの特徴を見ていきます。
語彙サイズについて
まずは語彙サイズについてです。 NovelAI Tokenizerでは、初めは語彙サイズを32,000としていたとのことで、これは一般的に使用される日本語の単語数が約30,000〜40,000と言われていることから妥当な語彙サイズであると言えます。本記事で紹介したbert-base-japanese-v3のトークナイザーも語彙サイズは32,768です。
しかし、NovelAI Tokenizerでは、日本語に加えて英語の処理も行うために検討した結果、語彙サイズを65,535まで拡大して、絵文字などの記号情報も含めたと述べられています。この語彙サイズは16ビットのトークンIDがほぼ全て埋まる大きさです。(2^16 = 65,536)
語彙に占める言語の内訳としては、2文字以上のアルファベットで28,586トークン、1文字以上の日本語で18,123トークン、漢字(日本語と中国語を区別できない)が9,626トークン、そのほか絵文字などの特殊文字9,200トークンで構成されています。
トークナイザーのタイプについて
次に、トークナイザーのタイプについてです。 ベースに使っているのは本記事でも紹介しているSentencePieceです。メモリ効率に優れていることが選定の理由であると述べられています。
圧縮率について
最後に圧縮率についてです。 NovelAI Tokenizerは圧縮率をもとにアルゴリズムを選定しています。初めはUnigramの利点を重視するつもりでしたが、圧縮率という側面においてBPEの英語データセットにおける圧縮率が25%〜29%優れていることがわかり、BPEを選択したと述べられています。
圧縮率が高い理由
ここで、BPEがUnigramよりも圧縮率が高い理由を考察します。 上述するように、UnigramとBPEにおけるトークナイゼーションの方法はそれぞれ異なっており、これらの仕組みの違いが圧縮率の違いに起因していると考えられます。
Unigramについて振り返ると、この手法では各サブワードが学習テキストの中で独立して出現する確率に基づいてトークナイゼーションを行います。このことから、Unigramでは学習テキスト内で頻繁に出現する比較的短いサブワードで分割を行う傾向があると考えられます。例えば”data”という単語よりも”da”や”ta”といったサブワードが出現する頻度が高いと考えられます。これらのサブワードが初期語彙に含まれている場合、”data”は”da”, “ta”と分割される可能性が高くなります。
一方で、BPEについて振り返ると、この手法では学習テキスト内で隣接する頻度の高いサブワード同士を結合して新しいサブワードとする手法でした。このプロセスを繰り返すことで、単語の長さに近いサブワードが形成される傾向があると考えられます。
これらの特性を踏まえると、Unigramは短めのサブワードでトークン化される傾向があり、汎化性能は高いが圧縮率は低い可能性があると考察され、BPEは長めのサブワードでトークン化される傾向があり、特定のテキストに依存しやすいが圧縮率は高い傾向があると考察されます。
どちらがより優れているかは言語モデルの目的や実際に扱うテキストによって左右されるため、ここで一概には判断できませんが、NovelAI Tokenizerでは圧縮率を重視して大きく優れていたBPEを選択したと考えられます。
以上よりJapanese StableLM Alphaは、比較的大きな語彙を持ち、圧縮率の高いBPEを使用したNovelAI Tokenizerを使うことで、日本語と英語を効率的かつ効果的に処理することを可能にしていると考察されます。
2. ELYZA-japanese-Llama-2-7b-fastでの改良点
次に、ELYZA-japanese-Llama-2-7bのfastモデルにおける改良点を、ELYZAが公開している解説記事15をもとに明らかにしていきます。
トークナイザー改良の背景
本モデルのベースとなっているLlama2のトークナイザーにはLlama Tokenizerが使われており、このトークナイザーの語彙数は32,000です。しかしLlama2の事前学習に使っているデータのうち日本語は0.1%であるため、当然ですがこのトークナイザーの語彙は日本語には最適化されていません。 そのため、日本語を取り扱うコストは英語よりも高くなっていると述べられています。後述しますが、Llama Tokenizerでは日本語は1文字単位で分割されることが多いことがわかっています。
例えば「大規模言語モデル」という単語をトークン化する際に「大」「規」「模」「言」「語」「モ」「デ」「ル」と分割することなります。1文字で1トークンであったとしても、これを処理するために計8トークン使うことになります。これが「大規模」「言語」「モデル」でそれぞれ1トークンの計3トークンだとすると、1文字単位で分割されることは処理効率が悪いということがわかります。(このことはNovelAI Tokenizerで言及した「圧縮率が低い」ということと同義です。)
これを踏まえてELYZA-japanese-Llama-2-7bのfastモデルでは、日本語を効率的に処理できるようにトークナイザーを改良したうえで、ベースであるLlama2モデルに対して日本語テキストで追加の事前学習を行なっています。
トークナイザーの改良点
解説記事では以下のような手順でトークナイザー(およびLLM本体)の改良を行なったことが述べられています。
1. 日本語のテキストのみで学習したBPE Tokenizerを学習する
ベースとなっているLlama Tokenizerとは独立に、日本語のテキストのみでBPE Tokenizerを構築したと述べられています。本記事で説明してきたように、BPEは隣り合う頻度が高い文字同士を結合するルールを作る手法であるため、日本語テキストで学習することによって、頻出する日本語のサブワードを一つのトークンとして扱うことができるようになることが期待されます。これによって「Llama Tokenizer」と「日本語処理が得意なトークナイザー」の2つが用意されました。
2. Llama Tokenizerと1で学習したTokenizerの語彙を結合する
2つのトークナイザーはどちらもBPEアルゴリズムを使っているため、HuggingFaceのtokenizersライブラリを使ってそれぞれの語彙を組み合わせて、語彙数45,043のトークナイザーを作ったと述べられています。
3. モデルのEmbedding層や出力層を追加語彙へ対応させる
ここまでの過程でトークナイザーの改良自体は完了していますが、次のステップとして、新たなトークナイザーをLLM本体に適用させています。対応させる点はテキストをベクトル化するEmbeddingと呼ばれる部分と、内部で計算されたベクトルデータを最後にテキストとして出力させる出力層の部分です。
具体的な対応方法は、元のトークン対するベクトルの平均値を初期値として利用して学習を行うというものです。例えばLlama Tokenizerで1文字単位で区切られたトークンである「東」「京」「都」のそれぞれのベクトルの平均を算出し、その平均値を初期値として「東京都」のベクトルの値を計算するという方法です。
4. 180億トークンの日本語データを追加学習させる
上記の手順で獲得したトークナイザーと元のトークンに対するベクトル平均値を利用して、ベースモデルであるLlama2に日本語テキストの追加学習を行いました。
トークナイザー改良の結果
改良の結果、fastモデルにおいては以下のような性能向上が得られたと述べられています。
- 推論速度が約1.8倍に向上
- 学習の効率化(300億トークンに相当するテキストが160トークンで表現された。)
この理由は、トークナイザーに日本語の語彙を追加し、日本語を扱う上で必要なトークン数を削減したことで、テキストの圧縮率が向上したためであると考察できます。
このように、ELYZA-japanese-Llama-2-7bのfastモデルでは、日本語に最適化した語彙を持つトークナイザーを再構築し、それを利用して追加事前学習を行うことで、日本語に対する処理性能の向上を実現させました。
トークナイザーションの比較
最後に、実際にトークナイザーごとのトークン化結果の違いを確認します。
Llama2 Tokenizer
まずはELYZA-japanese-Llama-2-7bのベースであるLlama2に使用されているLlama Tokenizerです。Llama TokenizerはNovelAI Tokenizerと同じくSentencePieceをベースとしたBPEアルゴリズムを採用しています。
ここでは、弊社の技術記事についての説明文である「JOURNALについて」というテキストをトークン化します。
from transformers import LlamaTokenizer
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = LlamaTokenizer.from_pretrained(model)
text = "JOURNALについて データアナリティクスラボ株式会社では、ITやデータサイエンスに関する技術の研究活動を行っています。このブログでは、研究活動で得られた知見や検証結果についての情報を発信します。"
encode = tokenizer.encode(text)
decode_sentence = []
for encode_subword in encode:
decode_subword = tokenizer.decode(encode_subword)
decode_sentence.append(decode_subword)
print("トークン化結果:", decode_sentence)# 出力
トークン化結果: ['<s>', 'J', 'OUR', 'N', 'AL', 'に', 'つ', 'い', 'て', '', 'デ', 'ー', 'タ', 'ア', 'ナ', 'リ', 'テ', 'ィ', 'ク', 'ス', 'ラ', 'ボ', '株', '式', '会', '社', 'で', 'は', '、', 'IT', 'や', 'デ', 'ー', 'タ', 'サ', 'イ', 'エ', 'ン', 'ス', 'に', '関', 'す', 'る', '技', '術', 'の', '研', '究', '活', '動', 'を', '行', 'っ', 'て', 'い', 'ま', 'す', '。', 'こ', 'の', 'ブ', 'ロ', 'グ', 'で', 'は', '、', '研', '究', '活', '動', 'で', '得', 'ら', 'れ', 'た', '知', '見', 'や', '<0xE6>', '<0xA4>', '<0x9C>', '<0xE8>', '<0xA8>', '<0xBC>', '結', '果', 'に', 'つ', 'い', 'て', 'の', '情', '報', 'を', '発', '信', 'し', 'ま', 'す', '。']これを見ると、日本語のトークン化結果が文字単位となっており、また「検証」というテキストが[ ‘<0xE6>’, ‘<0xA4>’, ‘<0x9C>’, ‘<0xE8>’, ‘<0xA8>’, ‘<0xBC>’ ]とうまく認識できていないことがわかります。
このことからLlama Tokenizerの32,000の語彙サイズの中に含まれている日本語に関するサブワードは文字単位であり、かつ日本語のサブワードが少ないということが考えられます。また、これによって処理できない漢字(未知語)が多く発生することが考察されます。
NovelAI Tokenizer
次にNovelAI Tokenizerを使ったトークン化結果をみていきます。 あらかじめGithubからnovelai.modelをダウンロードしておき、それを読み込む形で実装します。
import sentencepiece as spm
s = spm.SentencePieceProcessor(model_file="novelai.model")
text = "JOURNALについて データアナリティクスラボ株式会社では、ITやデータサイエンスに関する技術の研究活動を行っています。このブログでは、研究活動で得られた知見や検証結果についての情報を発信します。"
print("トークン化結果:", s.encode(text, out_type=str))/# 出力
トークン化結果: ['J', 'OUR', 'N', 'AL', 'について', '▁', 'データ', 'アナ', 'リティ', 'クス', 'ラ', 'ボ', '株式会社', 'では', '、', 'IT', 'や', 'データ', 'サイ', 'エンス', 'に関する', '技術', 'の研究', '活動', 'を行', 'っています', '。', 'この', 'ブログ', 'では', '、', '研究', '活動', 'で', '得', 'られた', '知', '見', 'や', '検証', '結果', 'についての', '情報', 'を発', '信', 'します', '。']このトークナイザーでは、日本語が文字以上かつ単語以下の大きさでトークン化がされていることが確認できました。
ELYZA-japanese-Llama-2-7b-fast トークナイザー
最後に、ELYZA-japanese-Llama-2-7b-fastに使用されたトークナイザーについて見ていきます。
from transformers import AutoTokenizer
model = "elyza/ELYZA-japanese-Llama-2-7b-fast"
tokenizer = AutoTokenizer.from_pretrained(model)
text = "JOURNALについて データアナリティクスラボ株式会社では、ITやデータサイエンスに関する技術の研究活動を行っています。このブログでは、研究活動で得られた知見や検証結果についての情報を発信します。"
encode = tokenizer.encode(text)
decode_sentence = []
for encode_subword in encode:
decode_subword = tokenizer.decode(encode_subword)
decode_sentence.append(decode_subword)
print("トークン化結果:", decode_sentence)トークン化結果: ['<s>', 'J', 'OUR', 'N', 'AL', 'について', '', 'データ', 'ア', 'ナ', 'リティ', 'ク', 'ス', 'ラ', 'ボ', '株式会社', 'では', '、', 'IT', 'や', 'データ', 'サイ', 'エ', 'ンス', 'に関する', '技術', 'の', '研究', '活動', 'を行', 'っています', '。', 'この', 'ブログ', 'では', '、', '研究', '活動', 'で', '得', 'られた', '知', '見', 'や', '検', '証', '結果', 'についての', '情報を', '発', '信', 'します', '。']こちらも日本語が文字以上かつ単語以下の大きさでトークン化がされていることが確認できました。
なお、このトークナイザーでは52トークンに分割され、NovelAI Tokenizerでは47トークンに分割されています。大きくは変わりませんが、 NovelAI Tokenizerの方が語彙数が多いことから、文字よりも単語に近い単位でサブワード分割できるテキストが多い可能性があると考察されます。
まとめ
本記事では日本語LLMをトークナイザーの観点から深掘りし、日本語を適切にトークン化する手法を明らかにしてきました。
日本語おけるトークナイゼーションでは、日本語の単語区切りでないという性質に対応するために、あらかじめ単語区切りにする必要がなく、生のテキストから学習を行うことができるSentencePieceが有効であることが確認されました。 また、トークナイザーでは「圧縮率」という点が重要であり、頻出するサブワードが語彙に含まれていることで、効率的なトークン化が可能になるということがわかりました。 一方で、語彙は多ければ多いほどよいというわけではなく、それだけの計算コストが発生するため、「日本語を適切に処理する」というように、その言語モデルで達成したい目的に沿って最適な語彙を構築することが望ましいと考えられます。
また、本記事で取り上げた、日本語処理に対して高性能を持つJapanese StableLM AlphaとELYZA-japanese-Llama-2-7bに共通している点としては、どちらも日本語だけでなく英語の学習データも使っており、語彙にも日本語と英語の両方が多く含まれていることが挙げられます。このことから、複数言語を適切にトークン化して学習することによって、言語処理能力そのものが向上し、結果的に日本語処理の性能も相乗的に向上したのではないかと考えられました。
以上のように今回の調査と検証では、日本語LLMにおいて適切なトークナイザーを使用することは、LLMの学習効率や推論速度の向上に寄与しており、言語モデルの性能に影響を与える重要な機能であることを明らかにすることができました。
最後に、高精度な日本語LLMは本記事で紹介したもの以外にも開発が進んでおり、今後も新たなモデルが登場してくることが期待されます。これらのモデルを利用する際、トークナイザーの重要性を深く認識し、各モデルが自身の目的に適合するかを評価する基準の一つとして検討していきたいと思います。
1https://ja.stability.ai/blog/japanese-stablelm-alpha
https://note.com/elyza/n/na405acaca130
2https://huggingface.co/stabilityai/japanese-stablelm-base-alpha-7b
https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b
3https://github.com/EleutherAI/gpt-neox
4https://github.com/microsoft/DeepSpeed
5https://dumps.wikimedia.org/other/cirrussearch/
https://https://huggingface.co/datasets/mc4
https://https://huggingface.co/datasets/cc100
https://oscar-project.github.io/documentation/
https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T
6https://github.com/EleutherAI/lm-evaluation-harness
7https://github.com/google-research/bert
8https://huggingface.co/cl-tohoku/bert-base-japanese-v3
9https://github.com/google/sentencepiece
10https://ja.wikipedia.org/wiki/Unicodeの等価性
11https://www.aozora.gr.jp/
12https://github.com/google/sentencepiece/issues/884
13 機械翻訳における評価尺度の一つ。
14https://github.com/NovelAI/novelai-tokenizer
15https://zenn.dev/elyza/articles/2fd451c944649d
参考
本記事の執筆にあたっては、脚注に記載したものに加えて以下の論文やドキュメントを参考にさせていただきました。
- https://huggingface.co/learn/nlp-course/chapter6/5?fw=pt
- https://huggingface.co/learn/nlp-course/chapter6/6?fw=pt
- https://huggingface.co/learn/nlp-course/chapter6/7?fw=pt
- https://qiita.com/taku910/items/7e52f1e58d0ea6e7859c
- https://medium.com/axinc/bertjapanesetokenizer-日本語bert向けトークナイザ-7b54120aa245
- https://huggingface.co/NovelAI/nerdstash-tokenizer-v1
- Rico Sennrich, Barry Haddow, Alexandra Birch. 2015. Neural Machine Translation of Rare Words with Subword Units
- Taku Kudo. 2018a. Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates
- Taku Kudo, John Richardson. 2018b. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing