
はじめに
データソリューション事業部の宮澤と力岡です。
今回は、Googleから発表された注目の大規模言語モデル「Gemini」 について紹介します。Geminiは、OpenAIのGPTモデルに匹敵、あるいはそれを上回る性能を持つと言われており、これまでOpenAIがリードしてきた生成AI分野にGoogleが新たに参入することで、イノベーションと競争が一層活発になっていきそうです。本記事では、Geminiの概要や使用感、そしてその性能がどのように評価されているのかを、簡潔に解説していきます。
Geminiの概要
Geminiとは、Googleが2023年12月6日に発表したマルチモーダルな生成AIモデルです。このモデルの特長は、テキスト、画像、音声、動画などの複数のデータタイプを同時に理解し、それらを組み合わせて処理する能力にあります。このマルチモーダル性により、従来の生成AIモデルが苦手としていた様々なデータタイプを含む複雑なタスクにも、情報をシームレスにやり取りして効果的に処理できるようになりました。
Googleが公開した技術レポート「Gemini: A Family of Highly Capable Multimodal Models」を基に、Geminiの情報を以下にまとめます。
モデルの種類
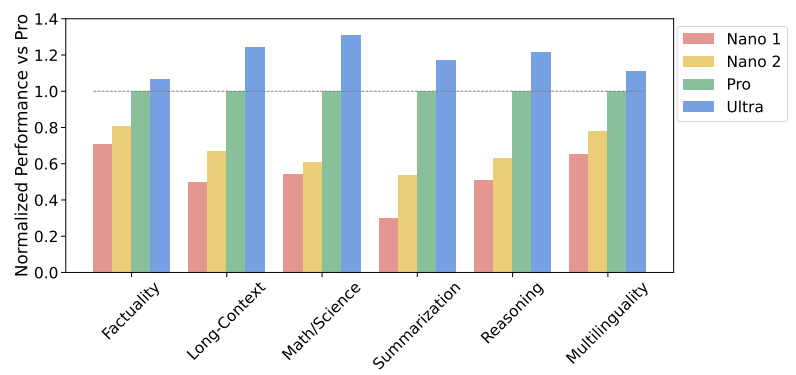
Geminiには以下の3種類のモデルが存在し、Gemini Ultra > Gemini Pro > Gemini Nano の順で性能が高いモデルとなっています。2023年12月の現時点で、一般に利用可能なのは Gemini Pro のみで、特定のスマートフォンを保有するユーザーは Gemini Nano も利用することができます。

モデルのアーキテクチャ
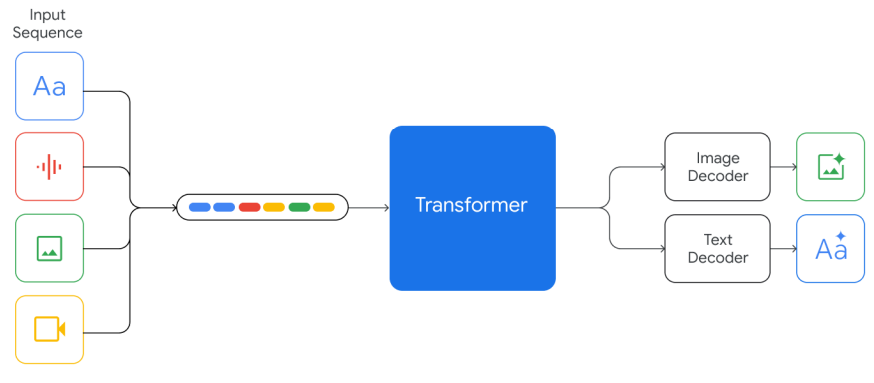
Gemimiは、OpenAIのGPTと同様に、Transformerアーキテクチャを基に訓練されています。また、教師ありファインチューニング(SFT)と人間のフィードバックによる強化学習(RLHF)も行われており、回答の精度と安定性を向上させています。
特筆すべきは、Geminiはマルチモーダルを前提として設計されており、テキスト/画像/音声/動画の全てのデータを単一のTransformerで扱っているという点にあります。
モデルの性能
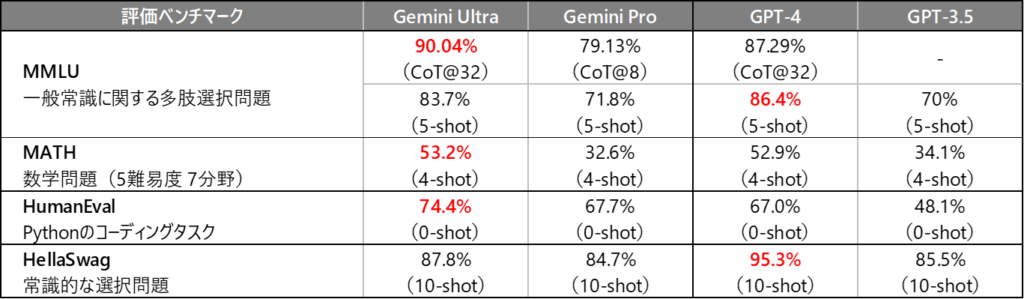
Geminiは、AIの精度を測定する32項目の業界ベンチマークのうち、30項目で最高記録を更新したと発表されています。代表的なものとして、一般的な常識や問題解決能力を測るMMLUベンチマークで90%のスコアを達成し、人間の専門家集団の平均スコア89.8%を超えた初めてのモデルとして話題となりました。
現時点で最も高性能とされるGPTモデルと、主要なベンチマークを対象にした比較表を下記に示します。Geminiは全体的に優れた成績を収めていますが、注目すべき点として、MMLUベンチマークにおいてはCoT(Chain of Thought)を用いたプロンプトを適用した場合にのみ、Geminiが高い性能を発揮しています。一方で、5-shotプロンプトを使用した際には、GPT-4がGeminiよりも高精度で機能していることが確認されています。CoTを使用しない状況も考慮すると、GeminiがGPT-4を完全に上回っているとはまだ言い切れない状況です。

CoT(Chain of Thought)とは、問題解決の一連の手順をプロンプトに組み込むテクニックです。解答に至るまでの中間ステップをプロンプトに明示的に含めることにより、AIがより複雑な推論タスクを効率的に処理する能力が向上します。さらに、few-shot promptingと組み合わせることで、難易度の高い推論が必要なタスクにおいて、より優れた結果を得ることが可能です。本記事の後半部分にはこのテクニックを用いた具体的な例を掲載していますので、参考にしてください。
技術レポートでは「CoT@32」のような表記が見られます。この「@k」という表記は、k個の回答候補を生成し、その中から最も適切な結果を選択する手法を指すようです。
論文:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Geminiの環境構築手順
ここからはGeminiの利用方法について説明します。 現在、Gemini ProはGoogleのAIチャットサービスである「Bard」の英語版には既に実装されており、利用が可能です。こちらはBardにログインすることで簡単に利用ができます。詳細はGeminiのリリースページをご覧ください。
本章ではGeminiをAPIを使って利用する方法について解説していきます。
Gemini APIの費用
具体的な利用方法の前に、Gemini APIの費用について説明します。
現在公開されているAPIはプレビュー版となっており、無料で利用できます。但し、1分間に60クエリの制限や、入出力のデータが学習に利用されることなどが条件となります。今後公開されるオプトアウト可能なAPIでは、文字数や画像数によって従量制の課金となります。
他モデルとの費用の比較
gpt-4-vision-preview
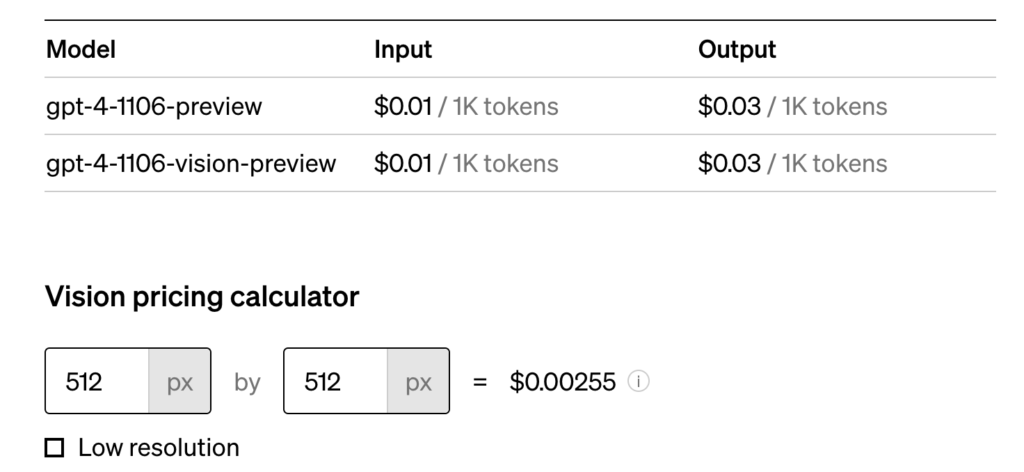
同じマルチモーダルモデルであるOpen AIのgpt-4-vision-previewと比較をします。 gpt-4-vision-previewのAPI利用料金は以下の通りで、テキストはトークン数に応じて、画像はピクセル数に応じて費用がかかります。
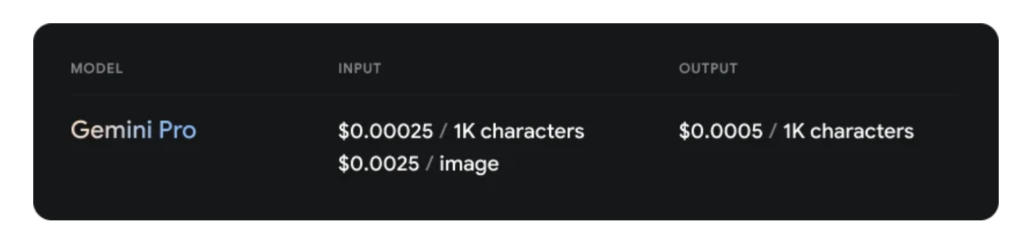
Gemini Pro
Gemini ProのAPI利用料金は以下の通りです。
テキストは文字数に応じて、画像は枚数に応じて費用がかかります。
費用の比較
例として以下のプロンプトを与えた想定で費用を計算してみます。
入力テキスト
Please explain what you see in this image.
画像
512px * 512pxの1枚の画像と想定します。
出力テキスト
This image features a reindeer resting in a natural setting. The reindeer has prominent, large antlers with multiple tines, which suggests it could be a male, as female reindeer tend to have smaller antlers. It is positioned in a landscape that appears to be a forest clearing or meadow, with various vegetation like shrubs and small trees, which may indicate a taiga or subarctic environment that is common for reindeer habitats.
gpt-4-vision-preview
入力トークン数:9
出力トークン数:95
画像:1枚(512px * 512px)
合計:$0.00549(約0.8円)
Gemini Pro
入力文字数:42
出力文字数:431
画像:1枚(512px * 512px)
合計:$0.002726(約0.4円)
上記の例においてはGemini Proの料金はgpt-4-vision-previewの約1 / 2程度であることがわかりました。より高性能なGemini Ultraの料金は明らかではありませんが、Gemini Proについてはかなり安価なモデルであると言えそうです。
Google Colabratoryでの環境構築
ここからは具体的なGemini APIの利用方法について解説していきます。 なお、本記事では「Google Colaboratoryでの利用方法」と「Vertex AIでの利用方法」の2つを紹介します
まずはGoogle Colabratoryでの利用方法です。 こちらのチュートリアルに従って環境構築の方法を説明していきます。
1. Google AI StudioでAPIキーを発行する。
まずGoogleが提供するGoogle AI Studioというブラウザベースの生成モデル利用プラットフォームでGeminiのAPIキーを発行します。(Workspaceアカウントを利用している場合は別途設定が必要な場合があります。)
Google AI Studioにログインできたら、ここで自身の既存のGCPプロジェクトを選ぶか、新しくプロジェクトを作成してAPIキーを発行するかを選ぶことができます。GCPプロジェクトがない方は「Create API key in new project」を選択してください。

「Create API key」をクリックするとAPIキーが発行されます。このキーは外部に漏らさず、自身で適切に管理してください。
2. Google Colaboratoryでノートブックを作成する
こちらからノートブックを作成することができます。
Google Colaboratory上にAPIキーを登録してGeminiにアクセスしていきます。
3. google-generativeaiをインストールする
ノートブックが作成できたらgoogle-generativeaiという、Goolgeの生成AIモデルをPythonで利用するためのパッケージをインストールします。
# SDKのインストール
!pip install -q -U google-generativeai次にサンプルコードの実行に必要なライブラリをインポートします。
# ライブラリのインポート
import pathlib
import textwrap
import google.generativeai as genai
# Used to securely store your API key
from google.colab import userdata
from IPython.display import display
from IPython.display import Markdown
def to_markdown(text):
text = text.replace('•', ' *')
return Markdown(textwrap.indent(text, '> ', predicate=lambda _: True))ここで”from google.colab import userdata“は、Google Colaboratoryに登録したキーなどを呼び出すためのものです。これを使うと後に登録するGeimini APIのキーをPythonコードで呼び出すことができます。
4. Gemini APIキーを登録する
実際にGemini APIのキーを登録します。画面左の鍵のマークをクリックすると以下のように表示されます。
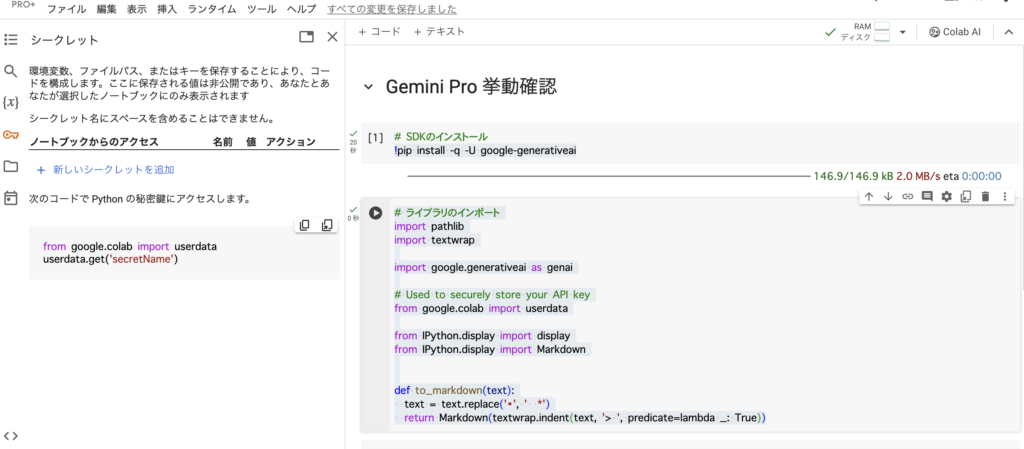
「新しいシークレットを追加」を選択して、「名前」を「GOOGLE_API_KEY」とし、「値」に手順1で発行したAPIキーを登録します。登録できたら「名前」の横にある「ノートブックからのアクセス」をオンしておきます。
登録ができたらコードに戻り、APIキーを変数に設定します。
# 登録したAPIキーを設定する
GOOGLE_API_KEY = userdata.get('GOOGLE_API_KEY')
genai.configure(api_key=GOOGLE_API_KEY)5. 利用できるモデルを確認してモデルを設定する
以下のコマンドで利用可能なモデルを確認できます。
# 利用できるモデルを確認する
for m in genai.list_models():
if 'generateContent' in m.supported_generation_methods:
print(m.name)以下のように2つのGeminiモデルが表示されます。
# 出力
models/gemini-pro
models/gemini-pro-vision以下のコマンドで、利用するモデルを設定します。ここではテキストベースの生成モデルであるgemini-proを設定します。
# 使うモデルを設定
model = genai.GenerativeModel('gemini-pro')6. プロンプトを与えてテキスト生成する
以下のコマンドでテキストを生成します。
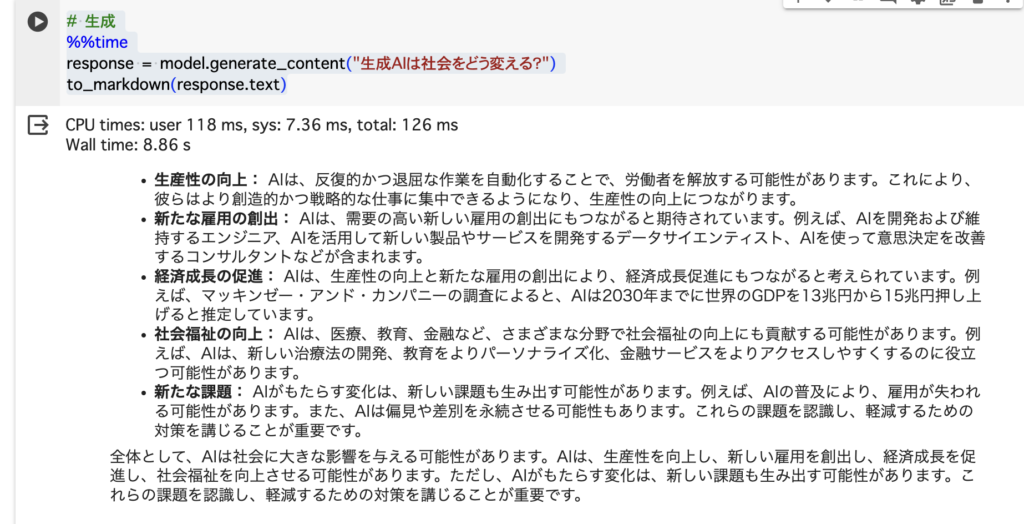
# 生成
%%time
response = model.generate_content("生成AIは社会をどう変える?")
to_markdown(response.text)以下のように出力されました。
以上がGoogle ColaboratoryでのGemini APIの利用手順です。マルチモーダルモデルであるgemini-pro-visionの使い方についてはチュートリアルの続きをご覧ください。
Vertex AIでの環境構築
次にVertex AIでの利用方法を紹介します。ここからはGCP(Google Cloud Platform)を使った方法になります。GCPにあるVertex AIというサービスを通してGeminiを使うことができます。
ここではGoogle Cloud Platformでプロジェクトが作成してあることを前提とします。手順は割愛しますが、特に難しいものではありません。「Google Cloud Console」と検索してGCPにログインし、「新規プロジェクト作成」を選択するだけで作成できます。詳細が不明な方はこちらのドキュメントを参考にしてください。
GCP上でプロジェクトが作成できたら2つの方法でGeminiを使うことができます。
- Vertex AI Studioを使う方法
- Vertex AI SDKを使う方法
1番についてはGCP上のメニューからVertex AIを選択し、「すべての推奨APIを有効化」してから「マルチモーダル」を選択すると以下の画面のように簡単に使うことができるため、本記事では詳細は割愛します。
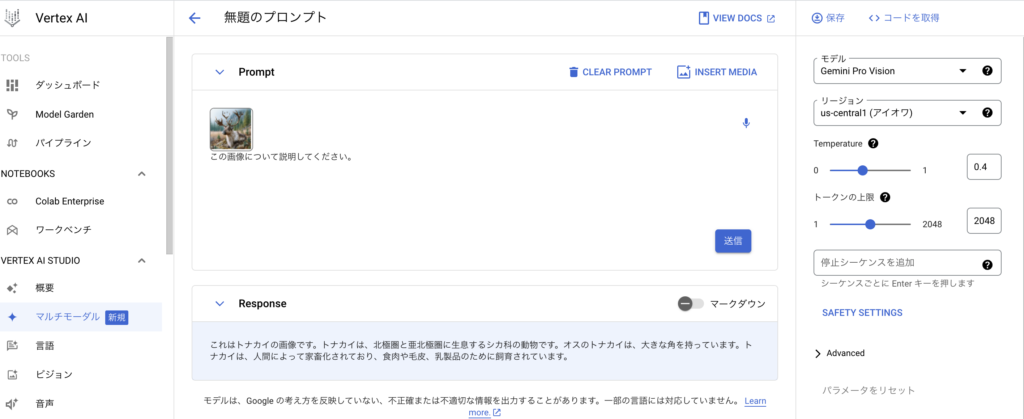
ここからは2番の「Vertex AI SDKを使う方法」について説明していきます。
Vertex AI SDKを使う方法
この方法では、ローカルからVertex AIにアクセスしてGeminiを利用します。こちらはGCP上でプロジェクトを作成し、Vertex AIのAPIが有効化されていること、またPythonが使える環境を用意されていることが前提となります。
ここからは大きく2つの方法があります。
- サービスアカウントを作成してサービスカウントキーでVertex AIに接続する方法。
- gcloud CLIで認証してVertex AIに接続する方法。
1番のサービスアカウントを使う方法ではキーの管理が必要となるため、本記事ではより簡単な2番の方法について解説します。
1. gcloud CLIをインストールする
gcloud CLI(Google Cloud CLI)とは、コマンドでGoogle Cloudのリソースの作成や管理を行うことができるツールです。これを使うことでローカルからVertex AIに接続することができます。詳細はこちらのドキュメントをご覧ください。
2. gcloud CLIの初期化
インストールができたらターミナル(コマンドプロンプト)で以下のコマンドを実行します。
gcloud initここでデフォルトのユーザーアカウントやプロジェクトを設定します。予め作っていたGCPプロジェクトを指定します。
3. 認証情報を使ってローカルからGCPのサービスにログインする
gcloudのインストールを行うと、認証情報がダウンロードされます。それを使うことでサービスアカウントの作成やそのキーを発行せずに、ローカルからPythonなどの言語を使ってGCPにアクセスすることができます。
以下のコマンドを実行します。
gcloud auth application-default loginブラウザ上のログイン画面に遷移するので、アカウントを選択して認証を進めます。(次に利用する際にエラーが出る場合は、この認証が切れていることがあります。再度認証を行ってからコードを実行するようにしてください。)
4. ライブラリをインストールする
認証が完了したら、PythonからVertex AIを利用するためのライブラリをインストールします。
pip install google-cloud-aiplatform5. サンプルコードを実行する
ここまでの手順で認証と必要なライブラリの準備が完了したため、Vertex AIのGeminiにアクセスすることができます。ここではGoogleから提供されているサンプルコードを実行してみます。
import http.client
import typing
import urllib.request
from vertexai.preview.generative_models import GenerativeModel, Image
# create helper function
def load_image_from_url(image_url: str) -> Image:
with urllib.request.urlopen(image_url) as response:
response = typing.cast(http.client.HTTPResponse, response)
image_bytes = response.read()
return Image.from_bytes(image_bytes)
# Load images from Cloud Storage URI
landmark1 = load_image_from_url("https://storage.googleapis.com/cloud-samples-data/vertex-ai/llm/prompts/landmark1.png")
landmark2 = load_image_from_url("https://storage.googleapis.com/cloud-samples-data/vertex-ai/llm/prompts/landmark2.png")
landmark3 = load_image_from_url("https://storage.googleapis.com/cloud-samples-data/vertex-ai/llm/prompts/landmark3.png")
# Pass multimodal prompt
model = GenerativeModel("gemini-pro-vision")
response = model.generate_content(
[landmark1, "city: Rome, Landmark: the Colosseum",
landmark2, "city: Beijing, Landmark: Forbidden City",
landmark3, ]
)
print(response)このコードではGoogle Cloud Strageに公開保存されている画像を読み込み、その画像とともにテキストでプロンプトを与えています。3番目の画像の説明が空欄になっているので、Geminiを使ってその部分の回答を生成するようなプロンプトであるということがわかります。
出力結果のテキスト部分を抜き出すと以下の通り回答されており、正常にAPIを実行できていることがわかりました。
text: " city: Rio de Janeiro, Landmark: Christ the Redeemer"以上がVertex AIを使ったGeminiの環境構築手順です。
モデル精度の比較検証
ここからはGeminiがどれほどの性能を持っているか、実際にいくつかのベンチマークなどを用いて検証していきます。
実力テスト
まずは、Geminiの実力がどの程度か確認するために、ChatGPT 4と比較しながらテストを行いました。最高性能のGemini Ultraは現在利用できないため、Vertex AI StudioからGemini Proを用いて、テキスト入力と画像入力の両方で簡単なテストを行っています。
テキスト入力
質問:相対性理論を、小学生にもわかるように200字以内で説明してください。
ChatGPT 4
相対性理論は、時間や空間が常に同じではないという考え方です。例えば、とても速く動くものは、動いていないときと比べて時間がゆっくり流れます。また、重いものの近くでは時間が遅くなります。この理論は、アインシュタインによって提案され、宇宙の不思議を理解するのに大切な役割を果たしています。
Gemini Pro
相対性理論とは、宇宙の速さについて研究したものです。宇宙の中で一番速いのは光の速さで、光は1秒間に地球を7周半も回ることができるくらい速いです。相対性理論では、どんなに速く動いても光の速さは変わらないことや、時間の流れ方は速く動くほど遅くなることなどについて説明しています。
どちらの回答も200字以内で内容についても問題ないですが、ChatGPTの説明の方がわかりやすく要点を捉えている印象です。
画像入力
質問:この画像について教えてください。

ChatGPT 4
画像には、人間の脳を模したデザインのキャラクターが描かれており、その後ろで3人の人物がリードにつながれ、ペットのように四つん這いで追いかけている様子が描かれています。このキャラクターは、透明な青色の体をしており、頭部は脳の形をしていて、回路のような模様があります。人物たちは首輪のようなものをしており、キャラクターに繋がれています。このイメージは、人間がAIやテクノロジーに支配されているかのようなメタファーか、またはAIが人間の知能をリードしている様子を表している可能性があります。ビジュアルはカートゥーン風で、ユーモラスなタッチが加えられているようです。
Gemini Pro
これは、脳のイラストが描かれたモニターのようなものを頭に乗せた人が、3人の人間をひもでつないで歩かせている様子を描いたイラストです。ひもでつながれた3人は、這いつくばってその人に従っています。このイラストは、人間の脳が人間の行動を支配している様子を表現したものと考えられます。
どちらも画像の内容を正しく認識できていますが、人間らしく理解し、かつ細部まで回答しているのはChatGPTの方でした。
ベンチマークによる精度確認
ここからはGeminiの技術レポートにもあったベンチマークを利用して、精度検証を行っていきます。今回は、生成AIモデル評価のベンチマークであるMMLUとMMMUについて、それぞれ検証を行いました。
MMLU
MMLUとは、Measuring Massive Multitask Language Understandingという論文で紹介された、事前学習で獲得した知識を評価するために設計されたベンチマークです。このベンチマークは、STEM(科学、技術、工学、数学)、人文科学、社会科学など、57の科目を網羅しており、難易度は初等レベルから高度な専門レベルまで幅広く設定されています。これにより、一般的な常識と問題解決能力の両方をテストすることが可能で、正答率の高さはそのモデルの精度の良さを示します。
今回は、Hugging Faceで利用可能なMMLU評価用データセットを利用して、評価を行っています。全科目の評価には時間がかかるため、初等数学、大学数学、機械学習、マネジメント、専門的な医学の5つの科目を選択し、それぞれの科目から20問ずつサンプリングし、合計100問で評価を実施しています。比較対象として、gpt-3.5-turboとgpt-4-turboでも同じテストを行い、その結果を比較しました。また、プロンプトにはCoTアプローチを採用し、段階的に考えながら解答を導き出しています。参考までに、初等数学の一例を以下に示します。
※ 本来は英語のプロンプトでテストしていますが、説明のために日本語訳しています。

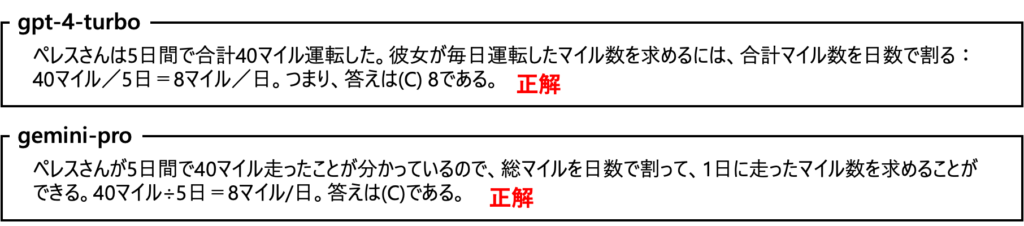
検証結果
下記にMMLUベンチマークの評価結果をまとめています。精度の面では、gpt-4-turboが他のモデルを大きく上回る結果となり、gpt-3.5-turboとgemini-proはほぼ同等の性能という結果になりました。回答速度に関しては、正確な測定は行っていませんが、体感ではgemini-proが最も応答速度が速い印象がありました。
gpt-3.5-turbo:65 / 100問(正解率:65%)
gpt-4-turbo:86 / 100問(正解率:86%)
gemini-pro-vision:61 / 100問(正解率:61%)
回答速度:gemini-pro > gpt-3.5-turbo > gpt-4-turbo
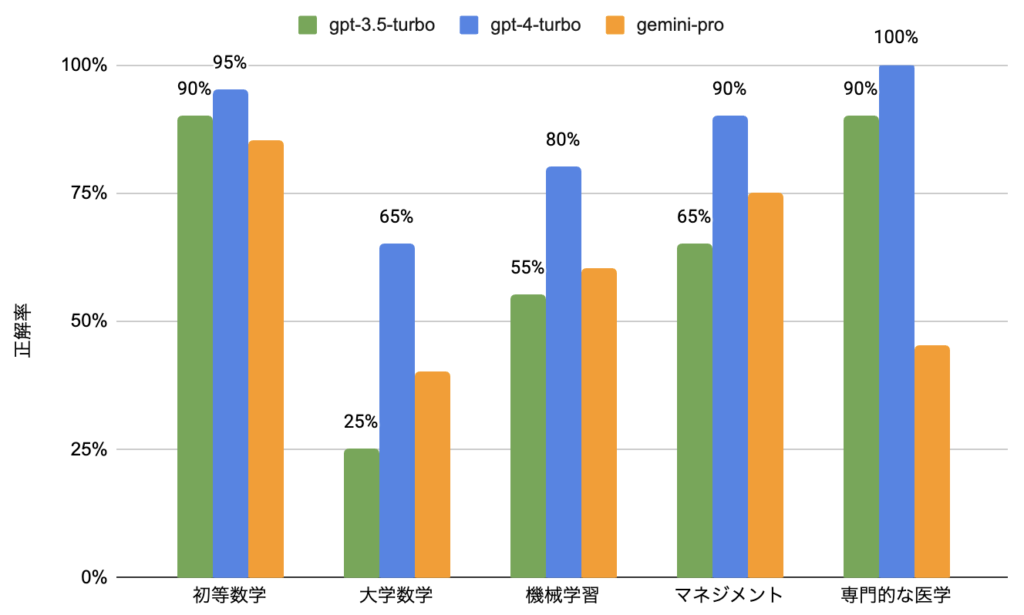
技術レポートにおけるMMLUの結果と同じ条件での測定は行えていませんが、得られた数値はほぼ同様の結果を示しました。レポート内ではGemini ProはGPT-3.5を上回る性能を持つと報告されていましたが、今回の検証では若干劣る結果となりました。
また、モデルごとに問題カテゴリとスコアを図示すると以下のようになります。
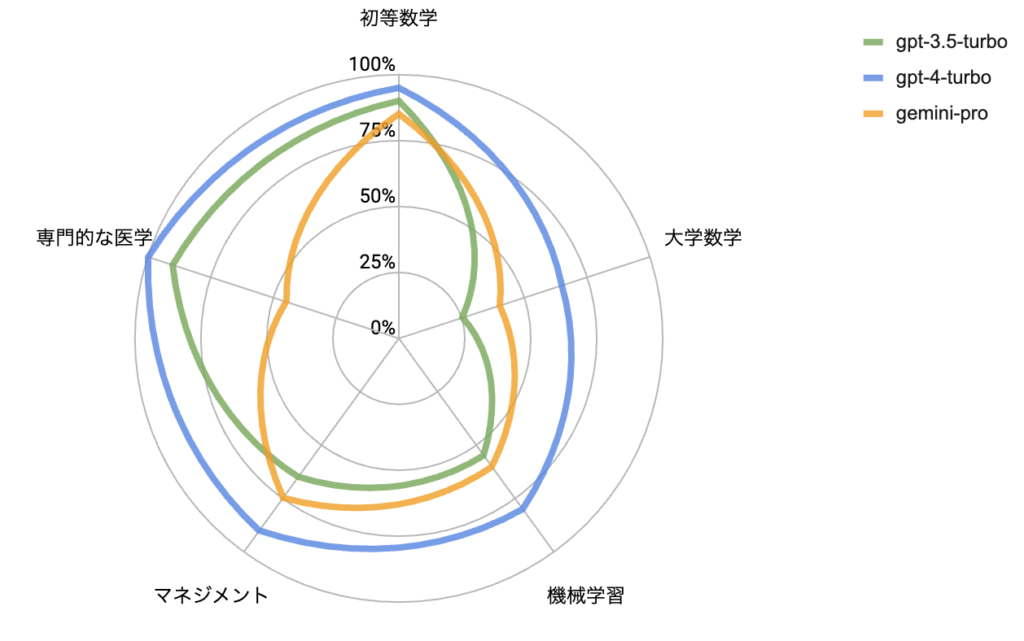
このデータを見ると、gemini-proは数学分野での正解率が高く、計算タスクに長けていることが分かります。しかし、gptと比べると、専門的な医学分野での正解率が著しく低く、知識ベースのタスクは苦手としている可能性があります。gptが医学分野は得意であると単純に解釈するならば、geminiは平均的にタスクをこなす能力があるといえそうです。
MMMU
MMMUとはMMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGIという論文で紹介された、マルチモーダルな生成AIの性能を評価するためのベンチマークおよびデータセットです。MMMUでは、30以上の専門分野において画像とテキスト(問題文)がセットになったタスクが提供されています。問題はEasy, Medium, Hardの3つのレベルに分けられており、多肢選択式と記述式の問題があります。
MMMUの特徴の一つとしては、「画像と問題の多様性」が挙げられます。これらの問題には表・図形・グラフ・写真など様々な画像形式を含んでおり、生成AIのマルチモーダル性能を広範に測るものとなっています。
実際の問題例としては以下のようなものがあります。

今回はHugging Faceで利用可能なMMMU評価用データセット(validation)を利用して評価を行っています。問題は5つのカテゴリ(会計・コンピュータサイエンス・地理学・数学・社会学)においてEasyを7問+Mediumを5問ずつサンプリングし、合計60問で評価を実施しています。また、問題は1枚の画像かつ多肢選択式に限定しています。
比較対象としてgpt-4-vision-previewで同じ検証を行い、その結果を比較しました。原論文によると指定のプロンプトは与えられていないため、ここでは両モデルで共通して以下のプロンプトを使用しています。
Please review the following explanation and image, then answer the question provided.
{問題文}
Here are the options for your response:
{回答選択肢}
{画像}
Please answer by selecting the best option from choices A to E. If you are unsure, please respond with “None”.
検証結果
検証結果は以下の通りで、トータルの評価としてはgpt-4-vision-previewの正解率が12ポイント高い結果となりました。
gpt-4-vision-preview:33 / 60問(正解率:55%)
gemini-pro-vision:26 / 60問(正解率:43%)
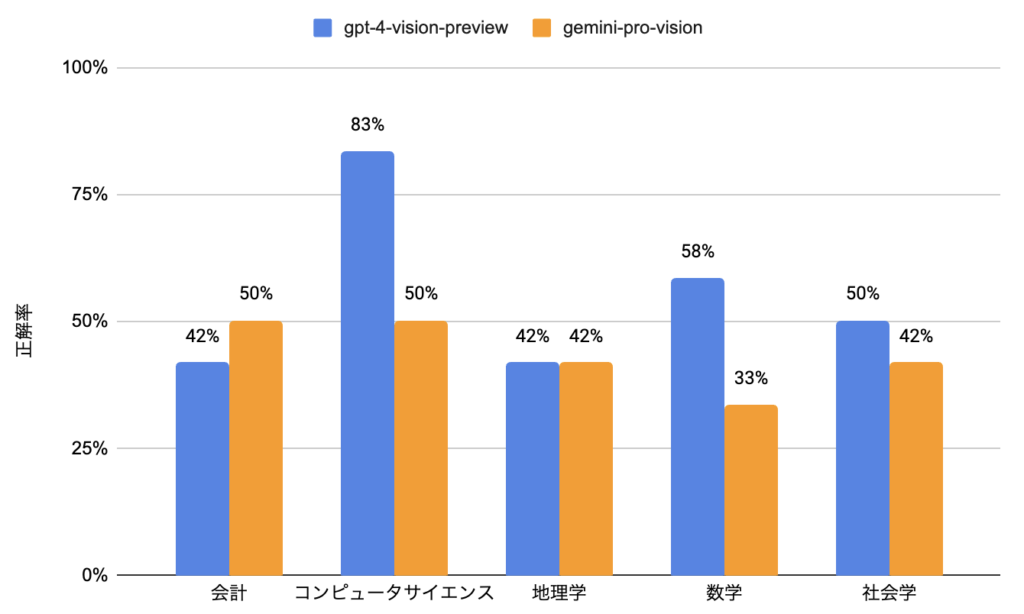
この結果は上で紹介した技術レポートのMMMUの結果(GPT-4V:56.8%、Gemini Pro:47.9%)と大きく変わらず、Gemini Proモデルと比較するとやはりGPT-4Vに軍配が上がることがわかりました。
また、モデルごとに問題カテゴリとスコアを図示すると以下のようになります。
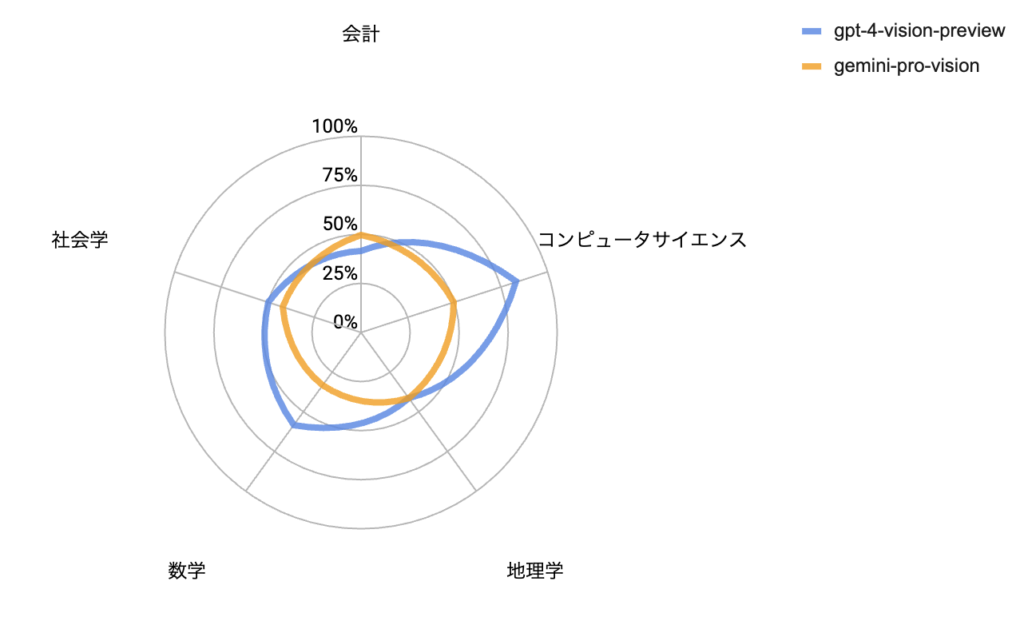
これを見るとgpt-4-vision-previewではコンピュータサイエンスや数学において特に高い正解率である一方で、gemini-pro-visionはどのカテゴリも同程度の正解率であることがわかります。
問題サンプル数が多くないため、ここで正確にモデルの得意分野を結論付けることはできませんが、gpt-4-vision-previewは全体的な性能に優れており、特に論理的な推論能力に特に強みを持ち、一方でgemini-pro-visionは特出した能力はないものの、多様な分野でバランスの取れた性能を持つ可能性がある考えられます。
このことから、画像とテキストを使ったマルチモーダル性能において、gemini-pro-visionはgpt-4-vision-previewよりも全体的な性能が劣りますが、一部のタスクではgpt-4-vision-previewと同程度の性能があると考えられます。また、ここでは共通のプロンプトを与えていたため、モデルによって最適なプロンプトを与えることができれば、性能評価の結果は変化する可能性があると考えられます。
GeminiとGPTの比較論文の紹介
最後に、GeminiとGPTを比較した論文がいくつか発表されているので、それらの概要と結論を簡潔に紹介します。
An In-depth Look at Gemini’s Language Abilities
発行日:2023年12月18日
概要:Gemini Proの言語能力をGPT-3.5およびGPT-4と比較した結果をまとめた論文。
検証結果:
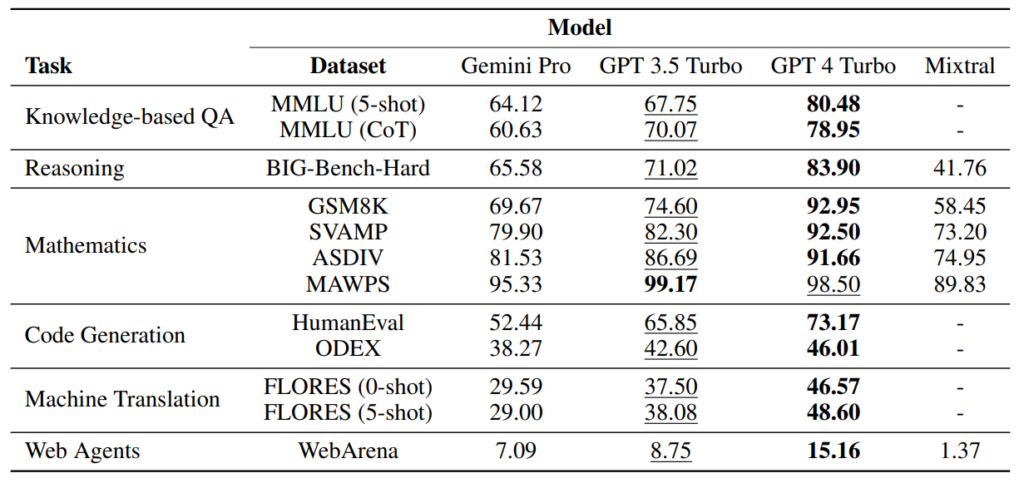
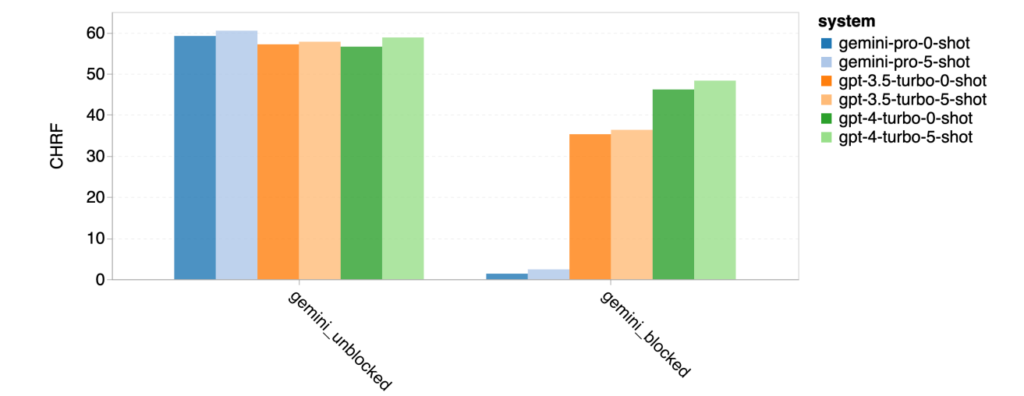
- Gemini Proは、GPT-3.5に多くのタスクでわずかに劣る性能を示した。(図17参照)
- 非英語テキストの生成や複雑な長文推論においては、Gemini Proが優れた性能を発揮した。
- 高難度のタスクにおいて、Gemini Proが回答を避ける傾向があることが観察された。これらを除外した場合、Gemini ProはGPT-4よりも高い性能を示した。(図18参照)
A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise
発行日:2023年12月19日
概要:Geminiの画像認識能力をGPT-4Vと比較した結果をまとめた論文。
検証結果:
- 多くのケースにおいて、GeminiはGPT-4Vと同等か、それ以上の正確さを示した。(図19参照)
- GPT-4Vが認知タスクでトップクラスの性能を示す一方で、Geminiは様々なタスクで同程度の性能を示した。
- 要素が多い画像に対する回答では、Geminiは簡潔な答えをGPT-4Vは詳細な答えを提供した。
- 両者の課題として文字、数字、幾何学形状などの認識能力に難がある。
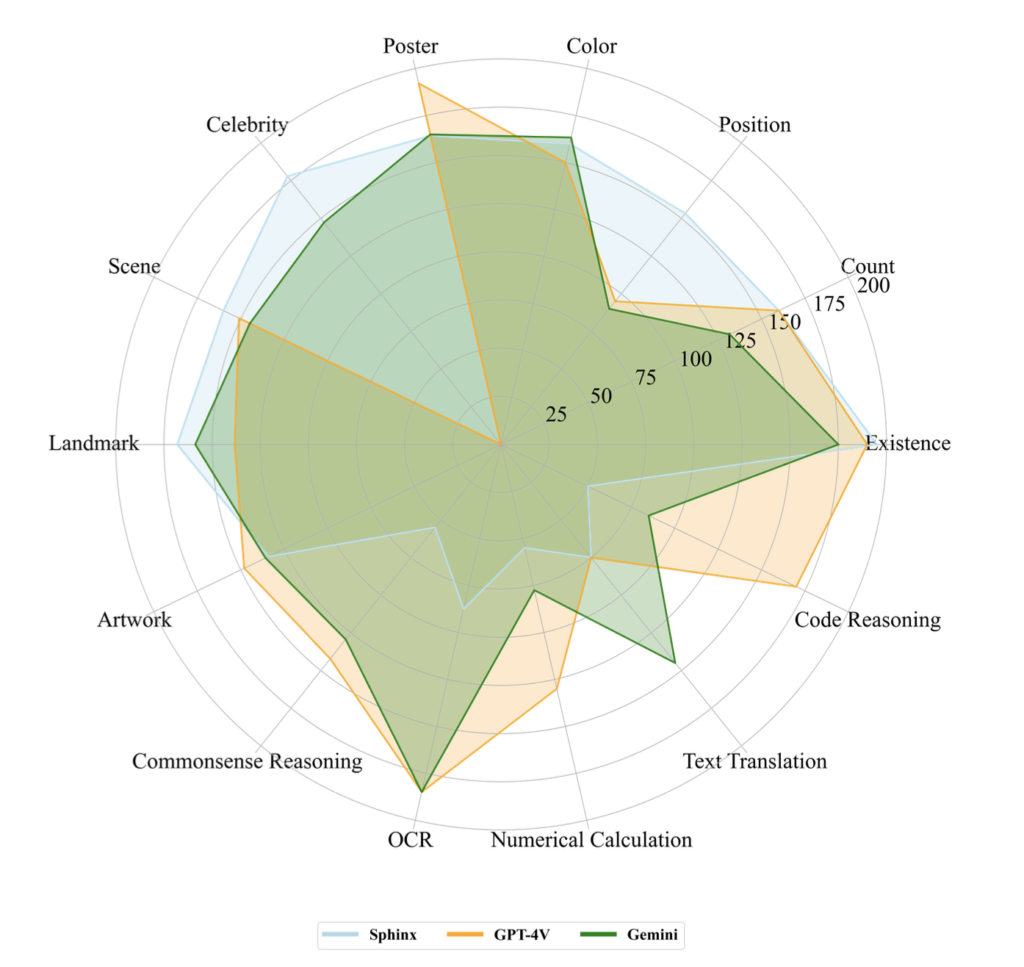
ここで、GPT-4Vは実在の人物の名前に反応しないため、有名人認識サブタスクでは0点となっています。これはある意味では個人情報に対する危険性の排除する機能が正確に備わっているという見方もできるため、単純に0点と捉えることはできないと考えられます。また、仮にこの指標を外した場合、総合点としてはGPT-4VがGeminiを上回る結果となります。
まとめ
本記事ではGeminiの概要、利用方法、およびその性能について調査してまとめました。
Gemimiのモデルアーキテクチャで特徴的な部分としては、マルチモーダルを前提として設計されており、テキスト/画像/音声/動画の全てのデータを単一のTransformerで扱っているという点があります。また、現在GeminiはAPIを使ってGoogle ColaboratoryやVertex AIで利用することができます。Gemini Proの性能としては、MMLUとMMMUという2つのベンチマークで評価を行ったところ、全体としてGPT-4よりはやや劣る結果となりました。
他の研究論文においては、テキストのみの推論ではGPT-4に劣る結果でしたが、一部のタスクや画像を含めた推論については、GPT-4と同等かそれを上回る結果となることが述べられています。このような結果から、総合点として性能の高低があっても、それぞれのモデルで強みや特性を持っているということが考えられました。
Googleに関していえば、先日リリースがあったように、生成AIチャットシステムである「Bard」の日本語版でもGoogle MapやGmailなどの既存のサービスと連携できるようになったことが発表されました。このようなことを踏まえると、新たな生成モデルであるGeminiは、総合的な推論能力の向上はもちろんですが、その一方で既存のサービスとの連携を最適化するようなモデルに進化していくことが予想されます。
したがって、私たちのようにAIを活用する立場においては、ベンチマークによる推論能力の定量的な評価を考慮しながらも、私生活や実務における目的に対して、個々の生成モデルの特性や強みがどう活用できるのかという点を明確にし、実際にモデルを使ってみた結果を踏まえて最適なものを選定していくのがよいと言えるでしょう。
参考
本記事の執筆にあたっては、以下の論文等を参考にさせて頂きました。
- Chaoyou Fu. et al. 2023. A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise
- Dan Hendrycks. et al. 2020. Measuring Massive Multitask Language Understanding
- Gemini Team Google. 2023. Gemini: A Family of Highly Capable Multimodal Models
- Hugging Face : MMLU評価用データセット
- Hugging Face:MMMU評価用データセット
- Jason Wei. et al. 2020. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- Syeda Nahida Akter. et al. 2023. An In-depth Look at Gemini’s Language Abilities
- Xiang Yue. et al. 2023. MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI