お気軽にお問い合わせください
MMM(マーケティング・ミックス・モデリング)とは?

MMM(マーケティング・ミックス・モデリング)は、マーケティング施策の影響度合いを定量的に分析するための時系列分析の手法です。MMMを用いて分析することで、KPIに応じた広告予算の最適化や効率的な予算配分を実現することができます。
本記事では、MMM(マーケティング・ミックス・モデリング)について、概要を分かりやすく解説いたします。
目次
MMM(マーケティング・ミックス・モデリング)とは?
MMMは時系列のマーケティングデータを扱う分析手法です。その特徴は、活用に応じて柔軟にモデル式を変更することができる点と、近年規制が強化されているcookieなどの個人情報などに依存しない点にあります。メリットもある一方で、ドメイン知識や数学的な背景を理解する必要がありますので、データサイエンティストなどの専門家の力を活用することも重要です。
お気軽にご相談ください!
当サイトの運営会社であるデータアナリティクスラボ株式会社は、データサイエンティストのプロフェッショナルサービスを提供しています。MMMの構築や活用の実績もございますのでお気軽にご相談ください。
MMMが近年注目されている理由は、主に3つあります。
- cookie規制の強化に伴い、個人を識別する形での行動データ活用ができなくなりつつある
- マスメディア広告に加えインターネット広告など広告媒体が多様化し、そのデータを利活用できるようになった
- 競合他社の状況や天候、経済状況などの外部要因を活用できる
分析によってわかること
MMMを用いることで、①マーケティング効果の測定(過去)、②広告予算などの予算最適化(現在)、③予算配分のシミュレーション(未来)などをおこなうことができます。
①マーケティング効果の測定
MMMを用いることで、マーケティング効果の測定をおこなうことができます。これまでおこなった広告施策を数式化したり、貢献量を算出することで、施策への影響度合いを測ることができます。
②広告予算の最適化
MMMを用いることで、広告予算の最適化をおこなうことができます。
限られた予算の中で、複数モデルの最適化結果を比較して予算増減の参考材料としたり、シミュレーションと合わせることで広告効果を最大化する予算配分を算出することができます。
③シミュレーション
広告実績のデータからMMMによる数式化をし、その式に将来(次月や次の四半期など)の広告予算など説明変数に用いたデータを代入することで広告の効果を算出したり、予算配分を変化させることでKPIを達成することができるのかなどを算出することができます。
広告効果を最大化することに限らず、広告施策の妥当性や出稿金額ごとのパターンでの比較などをおこなうことも可能になります。
必要なデータ
MMMに必要なデータは、時系列データです。時系列データとは、「日次」「週次」「月次」などのデータであり、一定の時間間隔で集計されたデータのことを指します。このような時系列データにおいて、以下のような変数が必要になります。
まずはじめに、目的変数です。MMMにおける目的変数として使用されることが多いものは、「売上」や「販売数」「来店予約数」など、マーケティング効果を測るためのKPIデータです。この数値は、それぞれのマーケティング目標(KPI)に応じて変更することができます。
次に、説明変数です。MMMにおける説明変数は「メディアごとのインプレッション数」や「メディアごとの広告費」など自社のマーケティング活動から取得できるデータです。
それに加え、季節性のあるイベントのデータや市況、競合他社のデータなど自社のデータに限らない様々な外部データを含めた、目的変数に影響を与える可能性のあるデータを使用することができます。
長期の時系列データや多種多様な説明変数を利用することができれば、高い精度のモデルを構築できる可能性は高まります。
一方で、「継続的にデータを集めることができるか」「分析に耐えうるデータか」「十分なデータ量が確保できるか」など、現実的な制約にも注意する必要があります。
お気軽にご相談ください!
当サイトの運営会社であるデータアナリティクスラボ株式会社は、データサイエンティストのプロフェッショナルサービスを提供しています。MMMの構築や活用の実績もございますのでお気軽にご相談ください。
MMMのビジネスシーン活用
あるメーカーを例に、受注生産現場における、受注数をKPIとした際の、最適広告予算を求める場合を例に解説いたします。以下紹介する例は、Google社提供のLightweight_MMM1を使用したものになります。
データの収集
まず週次の受注数として以下のようなデータがあったとします。
| 年月日 | 受注数 |
| 2018/1/7 | 234,530 |
| … | … |
| 2021/6/6 | 215,770 |
| 2021/6/13 | 219,790 |
| 2021/6/20 | 260,830 |
| … | … |
次に、上記のデータに関連するマーケティングデータを収集します。
| 年月日 | デジタル広告費 | テレビ広告費 | 新聞広告費 | … |
| … | … | … | … | … |
| 2021/6/6 | 219,814 | 0 | 569,262 | … |
| 2021/6/13 | 185,906 | 0 | 640,968 | … |
| 2021/6/20 | 195,216 | 844,663 | 0 | … |
| … | … | … | … | … |
広告費の他にインプレッション数なども含まれている
(※架空データのため、実際の規模感とは異なります。)
上記以外にも、ホームページへのアクセス状況であるPV数やセッション数を使用してみたり、競合他社のデータが手に入るのであればそれを活用することもできます。重要なことは、自社の活動で作られるデータと同じ粒度で取得できるかどうかであったり、分析に耐えうるデータであるかどうかなど、無理のないデータである必要があります。
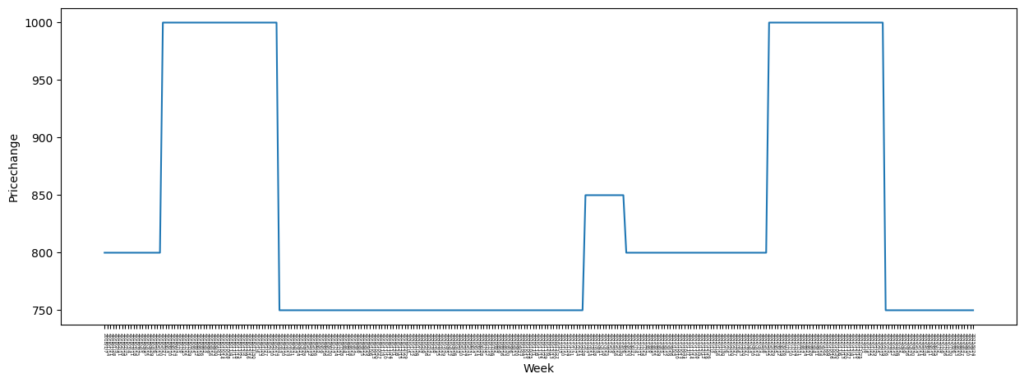
今回の例では、外部要因として、競合他社の小売価格をデータとして利用することとします。
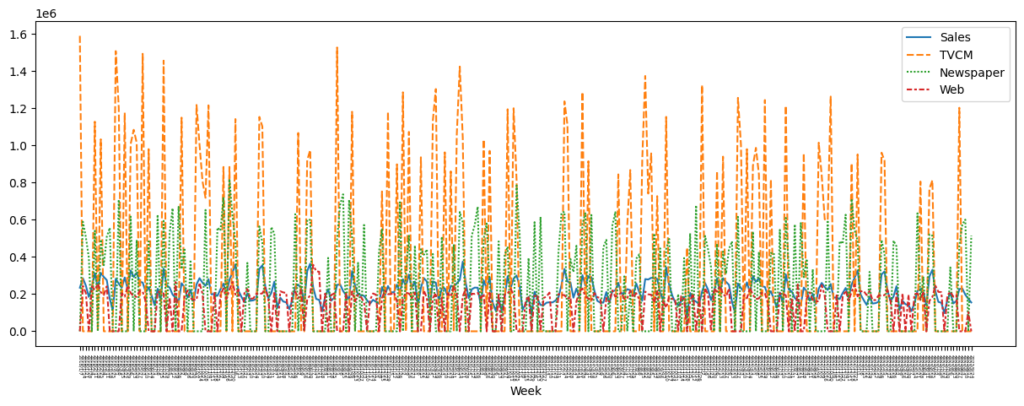
これらの収集したデータを可視化すると、以下のようなグラフになります。
データの前処理
続いて、収集・確認したデータの前処理工程に入ります。主な前処理としては、欠損値の補完や外れ値の取扱い、正規化や多重共線性への対応などが挙げられます。
欠損値については、「確率的回帰代入」や「多重代入法」などの手法で補完することが一般的には多いです。欠損値が発生する理由によっては、「0」や「平均値」「前年同時期の数値」などで代入することもあります。
次に外れ値について。外れ値が発生している要因が特定できる場合は、フラグなどを立てて対処することが一般的です。具体的には、競合他社の販促イベントのフラグだったり、テレビ番組で特集が組まれたりするなどのイベントが考えられます。
その他には、データの正規化をおこなったり、多重共線性が疑われる場合は変数選択による変数削減をおこなったりすることもあります。
モデルの構築
続いてモデルの構築をおこないます。
モデル構築のために訓練データとテストデータに分割します。MMMは時系列データを扱いますので、時系列順にデータを分割します。今回は2018年〜2023年秋頃までの約5年間分の週次データを扱いますので約1年分のデータをテストデータとして分割することとします。
次に、モデルの構造を決定します。今回は複数のモデル(Adstockモデル, Hill_Adstockモデル, Carryoverモデル※いずれもGoogle社提供のLightweightMMMを参照)を構築して、評価指標や貢献量の数値、可視化の結果に加え、モデルが算出する予算配分の結果などを総合的に勘案して採用モデルを決定することとします。
Carryoverモデル・Adstockモデル・Hill_Adstockモデルの特徴は以下の通りです。
| モデル種類 | 特徴 |
| Adstockモデル | 広告の減衰効果を考慮したモデル |
| Hill_Adstockモデル | 飽和効果を柔軟に表現することができるHill関数を組み込んだモデル |
| Carryoverモデル | マーケティング施策の効果が遅れて出てくることを考慮したモデル |
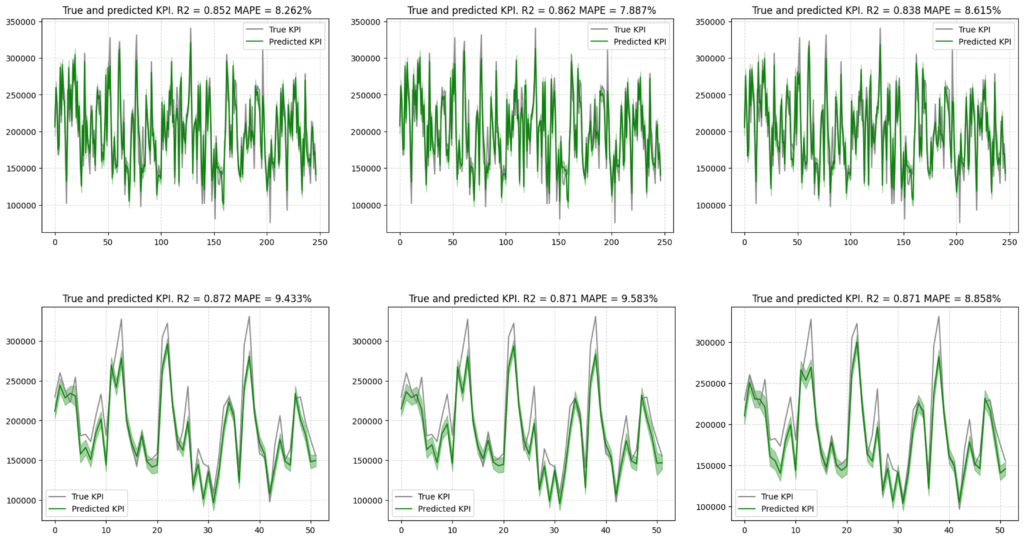
上記のとおりモデルを構築し、学習データとテストデータそれぞれの実績値とモデルの推定値をプロットした結果の可視化は以下の通りです。
モデルの評価
上記の結果の画像は、左からAdstockモデル、Hill_Adstockモデル、Carryoverモデルとなっています。決定係数やMAPE(平均絶対パーセント誤差)の評価指標からは3モデルとも甲乙つけ難い結果を示しています。いずれのモデルも、学習データに対する評価指標とテストデータに対する評価指標で大きな乖離はないと考えられるため、過学習しているとは考えにくい、”使えそうな”モデルが推定できていると考えられそうです。
次に、推定されているモデルのパラメータが収束しているかを確認します。推定されたモデルの当てはまりが良くても、パラメータが発散していては、モデルの再現性が疑われてしまうため、この点の確認も必要となります。本事例では、以下のような結果になりました。一部抜粋して表示します。
| mean | std | median | 5.0% | 95.0% | n_eff | r_hat | |
| … | |||||||
| coef_extra_features[0] | -0.07 | 0.06 | -0.07 | -0.17 | 0.02 | 543.00 | 1.00 |
| coef_media[0] | 0.64 | 0.04 | 0.64 | 0.58 | 0.70 | 542.65 | 1.00 |
| coef_media[1] | 0.26 | 0.02 | 0.26 | 0.23 | 0.30 | 604.72 | 1.00 |
| coef_media[2] | 0.24 | 0.02 | 0.24 | 0.21 | 0.27 | 646.78 | 1.00 |
| … |
| mean | std | median | 5.0% | 95.0% | n_eff | r_hat | |
| … | |||||||
| coef_extra_features[0] | -0.09 | 0.05 | -0.09 | -0.17 | 0.00 | 556.54 | 1.00 |
| coef_media[0] | 0.96 | 0.31 | 0.87 | 0.59 | 1.39 | 246.39 | 1.00 |
| coef_media[1] | 0.63 | 0.27 | 0.56 | 0.29 | 1.03 | 216.71 | 1.00 |
| coef_media[2] | 0.31 | 0.10 | 0.28 | 0.19 | 0.45 | 200.94 | 1.00 |
| … |
| mean | std | median | 5.0% | 95.0% | n_eff | r_hat | |
| … | |||||||
| coef_extra_features[0] | -0.04 | 0.06 | -0.03 | -0.13 | 0.06 | 641.35 | 1.00 |
| coef_media[0] | 0.55 | 0.03 | 0.55 | 0.49 | 0.60 | 621.75 | 1.00 |
| coef_media[1] | 0.25 | 0.02 | 0.25 | 0.22 | 0.28 | 714.09 | 1.00 |
| coef_media[2] | 0.22 | 0.02 | 0.22 | 0.19 | 0.25 | 722.81 | 1.00 |
| … |
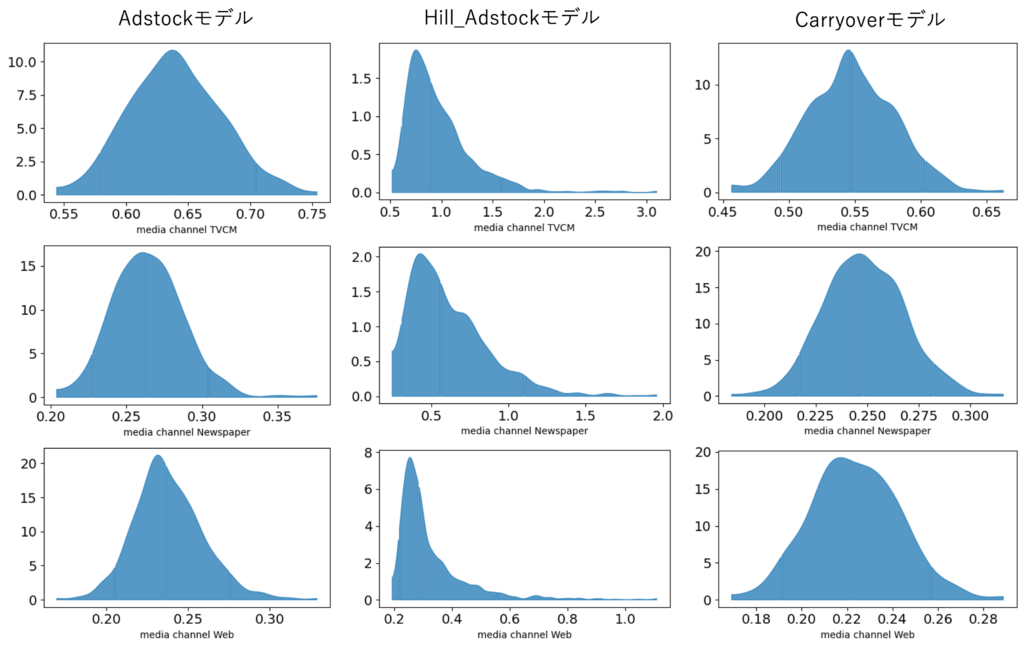
いずれのモデルでも、パラメータの収束度合いを表す「Gelman-Rubin統計量」の「r_hat(表中最も右の列)」が1.00付近という結果となりました。これはパラメータが収束していることを表しています。
続いて、各モデルのパラメータの事後分布をプロットすると以下のようになります。こちらからも収束を確認することができます。
ここまででモデルの妥当性を確認することができました。次に貢献量や飽和曲線などを確認します。
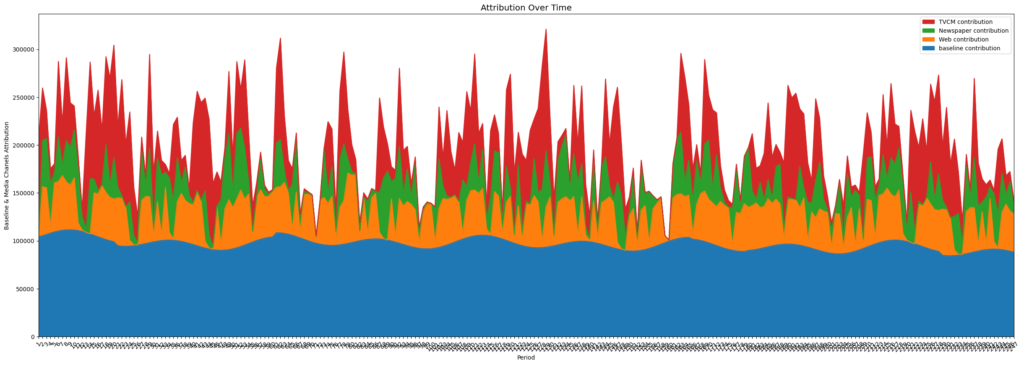
まずはじめに目的変数(KPI)に対する時系列貢献量をプロットします。
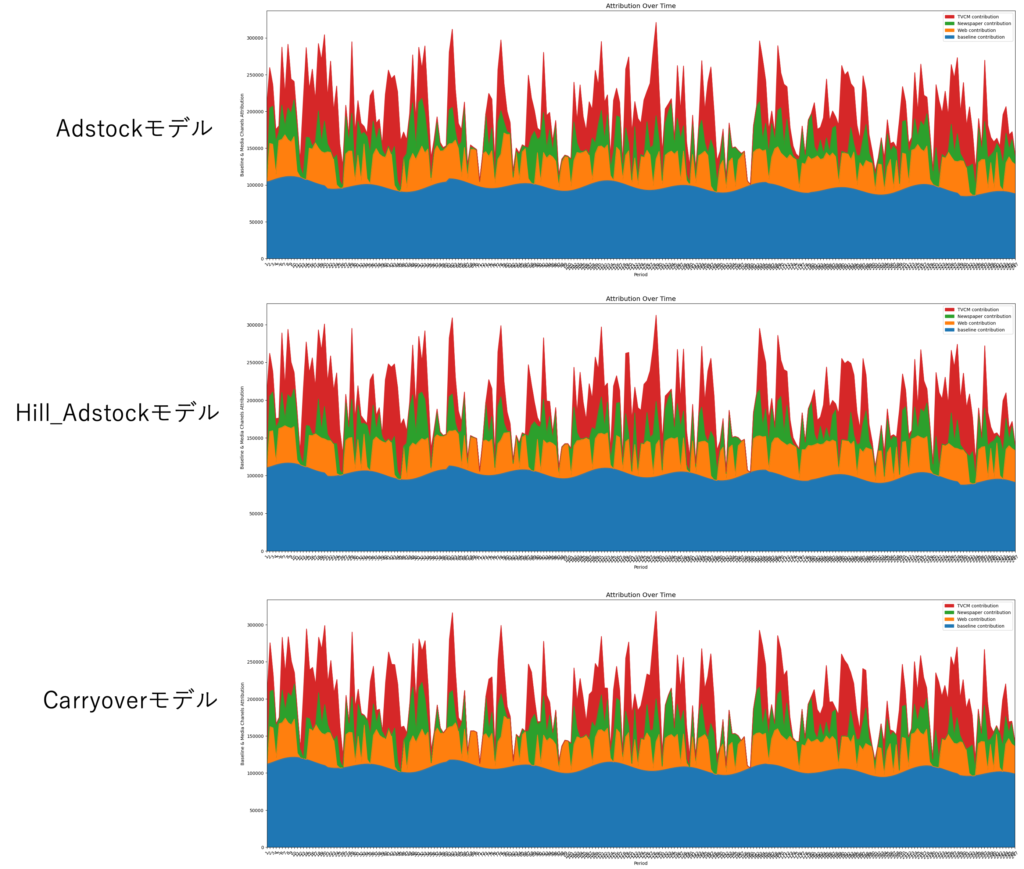
いずれのモデルも概ね同じ割合で貢献しているように見受けられます。続いて、上記の時系列グラフを全体の割合として表現すると以下のようになります。
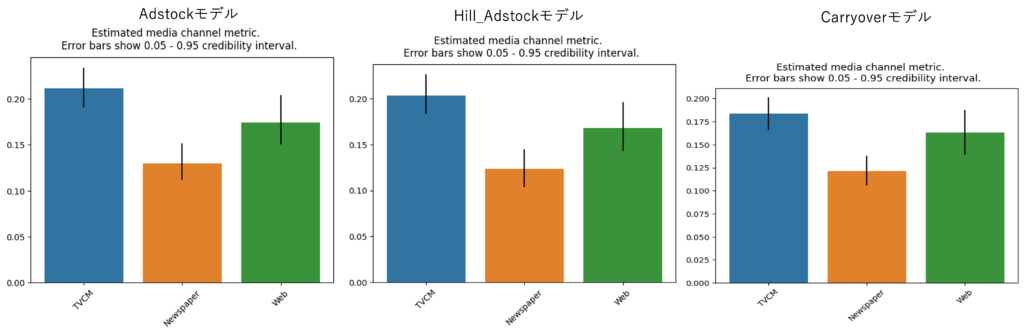
メディアそれぞれの貢献量の大きさの順番は、各モデルで共通しています。一方で、各割合はわずかに異なっている結果になっています。TVCMの貢献量について、Adstockモデルでは0.20を超えており、Hill_Adstockmモデルでは0.20程度、Carryoverモデルでは0.175程度となっています。また、新聞広告の貢献量では、各モデル共通して0.125付近となっています。Web広告でも新聞広告と同じように、貢献量の割合は各モデル共通して0.17程度となっています。
次に各モデルの応答曲線を確認します。応答曲線とは、投資額を横軸、KPIへの影響度合いを縦軸とした曲線で、一般的に投資額が大きくなると縦軸の値が一定の数値に収束(≒頭打ち)になるという特徴があります。
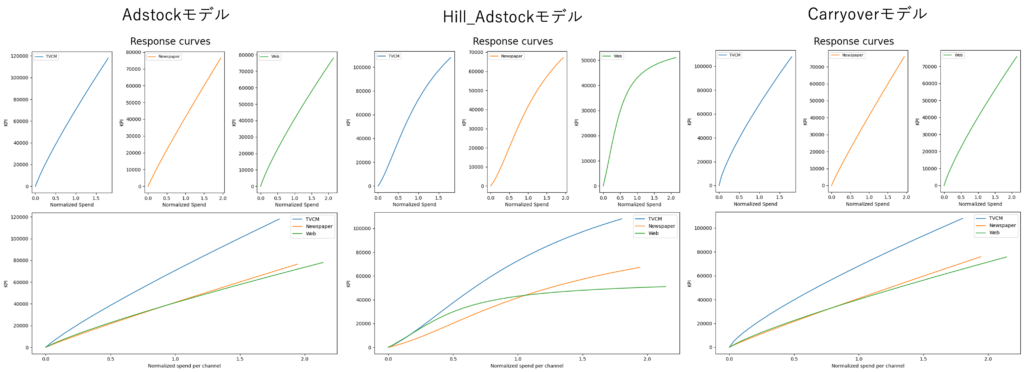
上図中央のHill_Adstockモデルでは、Web広告が飽和している曲線を描いています。同様に新聞広告もやや飽和気味の結果となっています。一方で、AdstockモデルとCarryoverモデルでは、両方のモデルとも似た曲線を描いており、まだ飽和を迎えているとは言いきれない結果であることがわかります。
これらのことより、構築している3つのモデルでは、局所的な違いはあれど、概ね同じような結果を示すモデルであると考えることができそうです。この仮の結論を確認するために、それぞれのモデルでシミュレーションをします。
予算配分とシミュレーション
構築したモデルから、最適な予算配分とその際のKPIシミュレーションを可視化します。
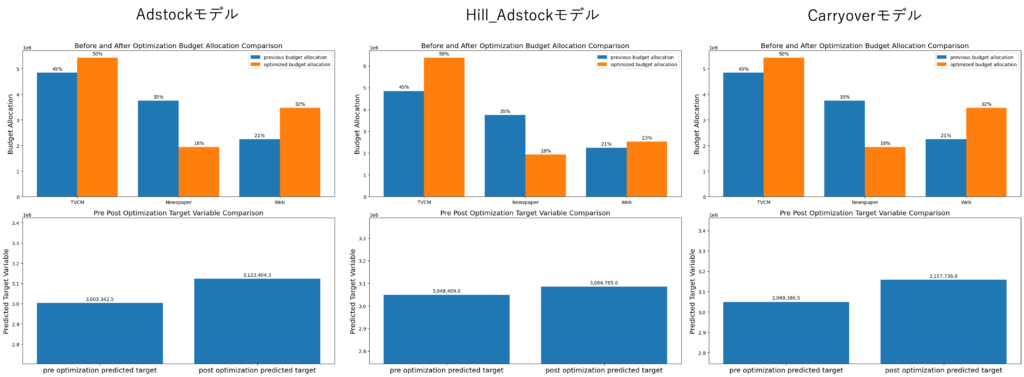
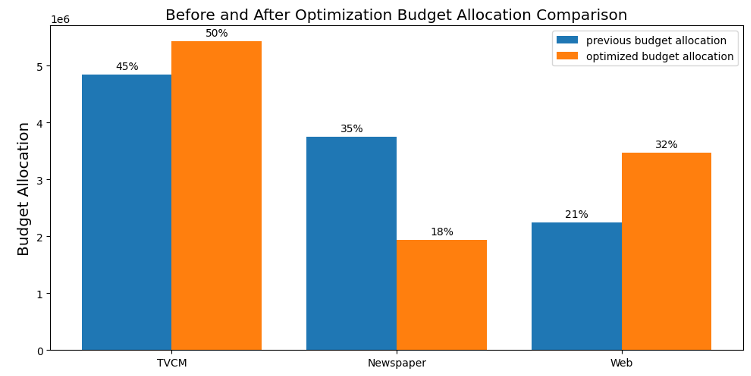
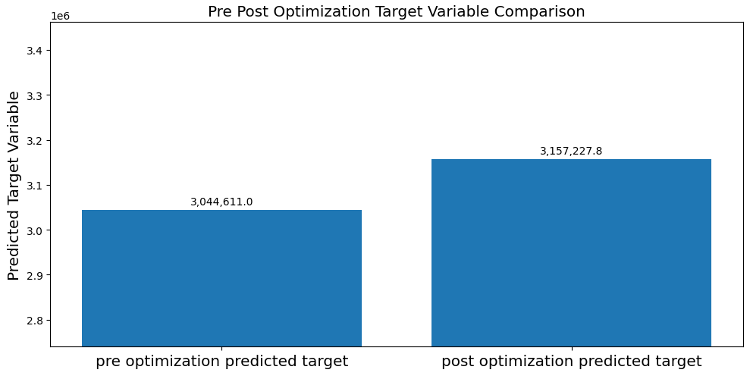
上3つのグラフについて、青い棒グラフは最適化前の予算配分で、オレンジの棒グラフは最適化後の予算配分となります。下3つのグラフは、予算の最適化を測った後、KPIとしている数値が最適化によってどのように変化するかを表しています。
上記のグラフより、差はありますがいずれのモデルも予算内の配分として「TVCMは予算増」「新聞広告は予算減」「Web広告は予算増」がより最適な予算配分であるという結果になりました。シミュレーションの具体的な数値をまとめると以下のようになります。
| モデル種類 | テレビ 実績 | テレビ 最適化後 | 新聞 実績 | 新聞 最適化後 | Web 実績 | Web 最適化後 | 実績 Simulation | 最適化後 Simulation |
| Adstock | 45% | 50% | 35% | 18% | 21% | 32% | 3,003,342 | 3,123,404 |
| Hill_Adstock | 45% | 59% | 35% | 18% | 21% | 23% | 3,048,409 | 3,084,785 |
| Carryover | 45% | 50% | 35% | 18% | 21% | 32% | 3,049,386 | 3,157,736 |
上記の表より、新聞の最適な配分は共通して「18%に減少させる」という計算結果になりました。複数のモデルで同じ結果を示すことは大きな示唆に繋がりそうです。
実際の活用現場では、現時点の新聞広告予算を突然半分にすることは難しいことも多いでしょう。この結果を一つの目安として、広告費を徐々に減らす中で、別のメディアへ振り替えて同様に貢献量を算出したり、新たにSNS広告に出稿することを検討したりするなどの手段が取ることが考えられます。
また、上記のシミュレーション結果から、現在のKPIが達成できているのかについても確認することができます。上記の表において、KPI目標が「3,100,000」であった場合、Adstockモデル、Carryoverモデルでは予算配分を変えることで達成することができますが、Hill_Adstockモデルでは達成できないことになります。このような観点からも採用モデルや妥当性を判断することもできます。
結論
ここまでのMMMの結果を参考に本分析の目的である「最適予算配分」について、以下のような方向性でマーケティング施策をおこなっていくことが考えられます。
- 新聞広告は段階的に縮小させ、2年後までに現在の予算を半分程度(現在の全体構成比20%)まで縮小する
- 縮小させた新聞広告の予算を、TVCM・Web広告の予算に回す
- さらに、ここまで出稿していなかったSNS広告の掲載を開始し、その効果を検証する
MMMの注意点
ここまでMMMの活用例について解説いたしました。最後にMMMを使用する際の注意点について解説します。
データ量
時系列データは一般的にデータ量を増やしにくいという欠点があります。1年間の時系列データでは、週次単位で約50程度、日次単位で約360程度のデータです。
また、実務で使用できる精度を出しつつMMMを構築するためには、説明変数の数を増やしていくことが有効な手段のひとつです。しかし、一般的に説明変数を増やすことでMMMを構築するために必要なデータ量は増える傾向にあります。
つまり、MMMにおいては、限られたデータ量に応じた説明変数選択などをする必要がある、ということになります。データ量には限りがある一方で、精度を上げるためには説明変数を増やす必要があり、そのためには十分なデータ量を確保する必要があるのです。
これらのことより、「分析に耐えうるデータ量が確保できるか」という観点が重要になります。
モデル構造
MMMのモデル構造は、用途や広告出稿の状況などによって柔軟に変更することができます。裏を返せば、モデル構造を決めるためには、数理的な背景を理解する必要があります。
具体的には、モデルのベースとなる数式を「加法モデル」で表現するか「乗法モデル」で表現するかなど採用するモデルの種類であったり、「応答曲線変換」と「アドストック変換」のどちらを先に変換するかなどの順序的な要素があります。
ただし、MMMパッケージの種類によっては、これらの柔軟性が確保できない場合もありますのでご注意ください。
今回、活用例で紹介しているGoogle社提供のLightweight_MMMでは、紹介のとおり3つのモデルから選択する形となっております。
試行錯誤が前提
MMMを構築するためには、様々なモデル構造を試したり、説明変数の取捨選択をしたり、変数間の関係性などを深く検討する必要があります。これらは一筋縄ではいかないことがほとんどです。MMMは、データサイエンティストなどの専門家や豊富なドメイン知識を持った人材がディスカッションを重ね、多くの試行錯誤を繰り返し、落としどころを見つけていくことが前提の分析手法になります。
まとめ
本記事では「MMM(マーケティング・ミックス・モデリング)」について、ビジネス活用の具体例を踏まえた解説を紹介しました。まとめると以下のようになります。
- cookieに依存しないマーケティング分析ができる
- MMMを活用することで、①マーケティング効果の測定、②広告予算などの予算最適化、③予算配分のシミュレーションが推定できる
- MMMは自社内・外部両方の時系列データを活用して分析することができる
- モデルを構築するには、専門的な知識が必要となる
- 試行錯誤が前提の分析手法である
MMM分析の特性や注意点を踏まえた、一歩深い分析の役に立てれば幸いです。
お気軽にご相談ください!
当サイトの運営会社であるデータアナリティクスラボ株式会社は、データサイエンティストのプロフェッショナルサービスを提供しています。MMMの構築や活用の実績もございますのでお気軽にご相談ください。
研究記事も執筆しています
データアナリティクスラボ


Geminiの使い方と精度調査 | データアナリティクスラボ
IndexはじめにGeminiの概要モデルの種類モデルのアーキテクチャモデルの性能Geminiの環境構築手順Gemini APIの費用他モデルとの費用の比較Google Colabratoryでの環境構築V...
データアナリティクスラボ

LangChainを利用したハイブリッド検索の実装 | データアナリティクスラボ
Indexはじめにハイブリッド検索とはハイブリッド検索を使う理由実装実行環境1. 環境構築OpenAI APIの利用状況の確認方法2. データセットの読み込みと整形3. ベクトル検索の...
データアナリティクスラボ

日本語LLMにおけるトークナイザーの重要性 | データアナリティクスラボ
Indexはじめに日本語LLMについてJapanese StableLM AlphaELYZA-Japanese-Llama-2-7bモデル評価本記事で取り上げるポイントトークナイゼーションとはトークナイゼーションの...
データアナリティクスラボ

イジングマシンで解く最適化問題の定式化 | データアナリティクスラボ
Index1. はじめに2. イジングマシンとは3. イジングマシンのための定式化3.1. イジングモデルイジングモデルにおける定式化3.2. QUBO形式3.3. 定式化の違い数学的等価性人...