
Index
はじめに
データソリューション事業部の力岡です。
近年、大規模言語モデル(LLM)の企業での利用が拡大しており、特にRetrieval Augmented Generation (RAG)と呼ばれる手法を利用した特化型LLMシステムの構築が注目されています。RAGは、企業独自のデータや外部データを利用して情報を生成することができ、知識の取得と活用において優れた性能を発揮します。
今回は、RAGシステムの核心となる文書検索の手法の一つとして、ハイブリッド検索をPythonで実装してみたので、その内容を紹介したいと思います。ハイブリッド検索は、Microsoftが提供するAzure Cognitive Searchなどの一部のサービスには標準搭載されていますが、今回はそれらは使わずにLangChainなどを利用して実装を進めていきたいと思います。
ハイブリッド検索とは
ハイブリッド検索の定義は様々ありますが、今回はAzure Cognitive Searchに搭載されているキーワード検索とベクトル検索を組み合わせた文書検索の手法をハイブリッド検索と定義することにします。
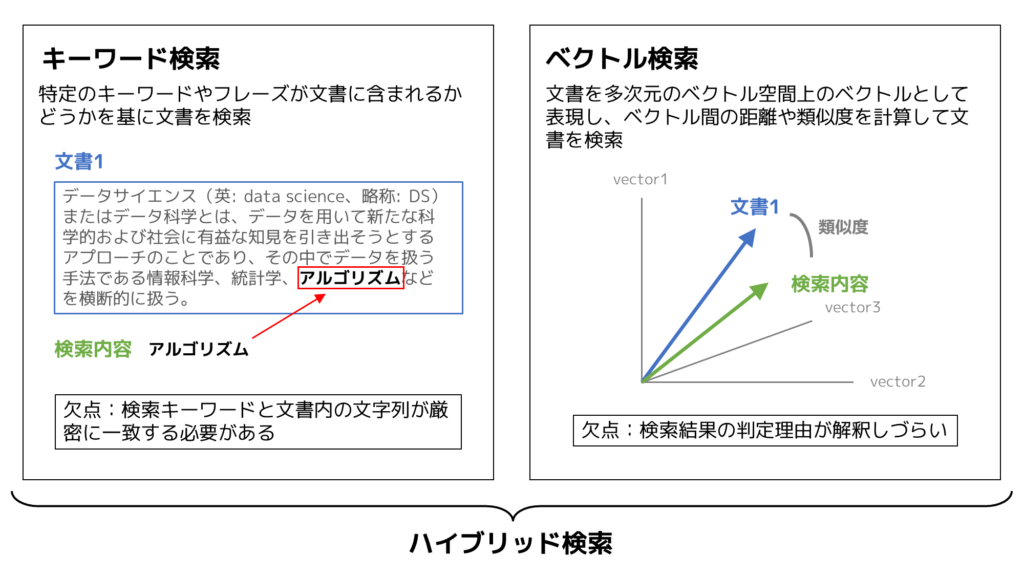
ハイブリッド検索を使う理由
キーワード検索の明確さとベクトル検索の柔軟性を併せ持つため、より高い精度で文書を検索することが可能となります。
Microsoftのコミュニティで紹介された下記リンクの文書検索手法ごとの精度比較結果においても、ハイブリッド検索はキーワード検索、ベクトル検索よりも高い精度を出せることが報告されています。
紹介記事:AI – Azure AI services Blog
実装
実装方針として、Microsoftのハイブリッド検索のデモ内容を再現して検証していきたいと思います。下記の記事に、詳細な検証内容が記載されているので、ご確認頂ければと思います。キーワード検索やベクトル検索では得ることが難しい文書を、ハイブリッド検索を使うことで検索の上位に出すことができるかを確認していきます。
紹介記事:Azure Cognitive Search のベクトル検索とハイブリッド検索の比較デモネタ
実行環境
Google Colaboratory
1. 環境構築
まずは、本実装を行うにあたり必要となるモジュールのインストールと読み込みを行います。
# ライブラリのインストール
!pip install chromadb rank_bm25 janome langchain tiktoken openaiimport os
import re
import glob
import pandas as pd
import chromadb
from rank_bm25 import BM25Okapi
from janome.tokenizer import Tokenizer
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma次に、OpenAIのAPIキーを入力します。APIキーをお持ちでない方は、OpenAIのウェブサイトから別途取得してください。
本実装では、ベクトル検索のためにOpenAIのEmbeddingモデルを利用します。このモデルの利用は従量課金制となっており、利用料が発生します。費用を抑えたい場合は、Hugging Faceで提供されている無償のEmbeddingモデルを利用することも可能ですので、その場合にはコードを適宜修正して実行してください。
# OPENAI_API_KEYを定義
os.environ["OPENAI_API_KEY"] = "sk-XXXXXXXXX"OpenAI APIの利用状況の確認方法
上述の通り、OpenAI APIは有料であり、トークン数に基づく従量課金制となっています。そのため、ご自身の利用料を都度チェックしておくことをおすすめします。APIの利用状況はこちらのページで確認が可能です。
2. データセットの読み込みと整形
今回の検証には、19人の武将に関する説明文がテキストデータ形式で格納されている戦国武将データセットを使用します。
こちらのデータセットはGitHub上に公開されていますので、まずはGoogle Colab内で使えるようにデータセットを取り込みます。
# データの読み込み
!git clone https://github.com/nohanaga/busho-index.git次にテキストデータのサイズが大きいものがあるため、適切なサイズとなるようにチャンク分割を行います。
今回は、LangChainのRecursiveCharacterTextSplitterクラスを利用してテキストを分割します。このクラスは、特定のトークン数になるまでテキストを再帰的に分割する機能を持っています。
# text splitterの定義
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=1000,
chunk_overlap=50
)GitHubから取り込んだデータセットを順次読み込み、上述した方法でチャンク分割を行った後、結果をDataFrameに追加していきます。
# データ格納用に空のDataFrameを作成
df = pd.DataFrame(columns=["source", "chunk_no", "content"])
# テキストを読み込んで分割し、DataFrameに格納
for filepath in glob.glob("busho-index/data/*.txt"):
with open(filepath, "r", encoding="UTF-8") as f:
data = f.read()
chunk = text_splitter.split_text(data)
filename = os.path.basename(filepath)
for i, c in enumerate(chunk):
df = pd.concat([df, pd.DataFrame({"source": filename, "chunk_no": i, "content": c}, index=[0])])
# データ識別用にIDを作成
df["ID"] = df["source"].str.replace(".txt", "", regex=False) + "-" + df["chunk_no"].astype(str)
df = df[["ID", "source", "chunk_no", "content"]]
# DataFrameを表示
df = df.reset_index(drop=True)
df.head(3)【出力結果】

最後に冗長な空白や改行文字を削除するなど、簡易的なデータクリーニングを行います。これにより、データの品質と検索精度を向上させることができます。
# データ整形用の関数を定義
def normalize_text(s, sep_token = " \n "):
s = re.sub(r'\s+', ' ', s).strip()
s = re.sub(r". ,","",s)
s = s.replace("..",".")
s = s.replace(". .",".")
s = s.replace("\n", "")
s = s.strip()
return s
# データ整形
df["content"]= df["content"].apply(lambda x : normalize_text(x))3. ベクトル検索の実装
ベクトル検索は、LangChainを使用して実装を行っています。LangChainには、ベクトル検索をサポートする機能が非常に充実しているため、手軽でかつ柔軟に機能を実装することが出来ます。
まずは、後続のデータ処理をスムーズに行うため、DataFrameの内容をリストに格納します。
# contentとmetadataをリスト型で定義
content_list = df["content"].tolist()
metadata_list = df[["ID", "source"]].to_dict(orient="records")
# contentとmetadataを表示
print(content_list[:2])
print(metadata_list[:2])【出力結果】

次にEmbeddingモデルとVectorStoreを定義します。
今回はVectorStoreにChromaを利用しますが、他のVectorStoreも利用可能です。また、OpenAI以外のEmbeddingモデルを利用したい場合は、この定義部分を修正します。
# Embeddingの定義
embeddings = OpenAIEmbeddings()
# VectorStoreの定義
client = chromadb.PersistentClient()
db = Chroma(
collection_name="langchain_store",
embedding_function=embeddings,
client=client,
)データをベクトル化し、VectorStoreに登録します。
# Vectorstoreにデータを登録
db.add_texts(
texts=content_list,
metadatas=metadata_list,
embeddings=embeddings,
)LangChainのsimilarity_search関数を使用して、ベクトル検索を実行します。
この関数を利用することで、検索クエリに対してコサイン類似度が高い順に文書を抽出することができます。引数のkには抽出件数を指定することもできます。
# ベクトル検索の実行
query = "源実朝は征夷大将軍として知られているだけでなく、ある有名な趣味も持っています。それは何ですか。"
vector_top = db.similarity_search(query=query, k=3)
# 詳細情報を取得して表示
df_vector_top = pd.DataFrame([doc.page_content for doc in vector_top], columns=["content"])
pd.merge(df_vector_top, df, on="content", how="left")【出力結果】

源頼朝の文書が多くヒットしています。ベクトル検索を利用しているので、検索理由は明確ではないですが、征夷大将軍という単語が含まれる文書が多く、そのあたりで高スコアとなっているのかもしれません。
4. キーワード検索の実装
キーワード検索には様々な手法が存在し、正規表現やTF-IDFなどが広く利用されています。今回はBM25という手法を採用し、ライブラリはrank_bm25を使用して実装を進めていきます。なお、LangChainにもBM25の機能は提供されていますが、カスタマイズの自由度が低く、使いづらさが感じられたため、今回は独自に実装を行っています。
BM25は、TF-IDFの拡張版ともいえる手法で、TF-IDFの計算式に単語の出現頻度がある程度以上になるとその重要度の増加が飽和するような項が追加されています。詳細な理論については、以下の記事が非常にわかりやすくまとめられているため、参考にしてください。
紹介記事:[自然言語処理/NLP] Okapi BM25についてざっくりまとめ (理論編)
キーワード検索を行うためには、まず文書を単語に分割する必要があります。英語のテキストはスペースで単語を区切ることができますが、日本語のテキストは単語の区切りが明確でないため、形態素解析器の利用が必要となります。今回は手軽に利用できる形態素解析器として、Janomeを採用しました。
検索処理においては、文書用とクエリ用のTokenizerを分けて利用しています。検索クエリ中の名詞や動詞以外の助詞や助動詞などは基本的に検索に重要でないことが多いため、クエリ用はそれらを除外するように実装しています。
# Tokenizerの初期化
t = Tokenizer()
# 文書用のTokenizerの定義
def tokenize(text):
return [token.surface for token in t.tokenize(text)]
# クエリ用のTokenizerの定義
def query_tokenize(text):
return [token.surface for token in t.tokenize(text) if token.part_of_speech.split(',')[0] in ["名詞", "動詞", "形容詞"]]文書をTokenizerを利用して単語リストに分割した後、BM25モデルに投入します。
# 文書を単語リストに分割
tokenized_documents = [tokenize(doc) for doc in content_list]
# BM25
bm25 = BM25Okapi(tokenized_documents)検索クエリも単語リストに分割し、rank_bm25ライブラリのget_top_n関数を使用してキーワード検索を実行します。
この関数は、キーワードに基づいて関連する文書を検索し、順位付けして抽出します。引数のnには抽出件数を指定することもできます。
# キーワード検索の実行
query = "源実朝は征夷大将軍として知られているだけでなく、ある有名な趣味も持っています。それは何ですか。"
# クエリをキーワード単語リストに分割して検索
tokenized_query = query_tokenize(query)
keyword_top = bm25.get_top_n(tokenized_query, content_list, n=3)
# 詳細情報を取得して表示
df_keyword_top = pd.DataFrame(keyword_top, columns=["content"])
pd.merge(df_keyword_top, df, on="content", how="left")【出力結果】

こちらも中々思うように対象の文章を探し出すことが出来ていません。検索クエリの単語リストは、[‘源実朝’, ‘征夷大将軍’, ‘知ら’, ‘れ’, ‘いる’, ‘有名’, ‘趣味’, ‘持っ’, ‘い’, ‘それ’, ‘何’]となっていますが、特に征夷大将軍や有名といった単語を持つ文書が上位に来ています。
5. ハイブリッド検索の実装
キーワード検索ではBM25アルゴリズム、ベクトル検索ではコサイン類似度という異なる手法によってスコアリングされます。これらの結果を統合し、より精度の高い検索を実現するために、ハイブリッド検索ではReciprocal Rank Fusion(RRF)という手法を採用してスコアリングを行います。
RRFは、文書の順位を基にスコアを計算する手法であり、各文書の順位が高い(つまり、検索結果の上位に位置する)ほど、スコアが高くなる仕組みとなっています。これにより、キーワード検索とベクトル検索の両方で高くランク付けされた文書を効果的に特定することが可能になります。

全ての文書に対して、まずベクトル検索とキーワード検索を実行し、それぞれの検索手法による順位付けを行います。その後、Reciprocal Rank Fusion (RRF)を利用して、これらの検索結果を統合し、ハイブリッド検索のスコアを算出します。今回の実装では、RRFのパラメータkを60と設定し、スコアの計算を行いました。
# ハイブリッド検索の実行
query = "源実朝は征夷大将軍として知られているだけでなく、ある有名な趣味も持っています。それは何ですか。"
# チャンク数を計算
n = len(content_list)
# ベクトル検索
vector_top = db.similarity_search(query=query, k=n)
vector_rank_list = [{"content":doc.page_content, "vector_rank":i+1} for i, doc in enumerate(vector_top)]
df_vector = pd.DataFrame(vector_rank_list)
# キーワード検索
keyword_top = bm25.get_top_n(tokenized_query, content_list, n=n)
keyword_rank_list = [{"content":doc, "keyword_rank":i+1} for i, doc in enumerate(keyword_top)]
df_keyword = pd.DataFrame(keyword_rank_list)
# 順位を結合して表示
df_rank = pd.merge(df_vector, df_keyword, on="content", how="left")
df_rank["hybrid_score"] = 1/(df_rank["vector_rank"]+60) + 1/(df_rank["keyword_rank"]+60)
df_rank = pd.merge(df_rank, df, on="content", how="left")
df_rank.sort_values(by="hybrid_score", ascending=False).head()【出力結果】

源実朝-0の情報が3番目に来ています。ベクトル検索は9位、キーワード検索は10位と両者ともに高い順位ではないですが、RRFの手法を取り入れることで文書の順位が上がってきました。こちらの文書には、”源実朝が歌人であった”という内容が含まれているため、RAGとしてLLMに情報を与えることで正しく質問に回答を生成できるようになります。
まとめ
今回はハイブリッド検索の実装手順について説明しました。Microsoftの検証結果といくつか異なる点がありましたが、本手法によって適切な文書を検索できることが確認できました。
一般的なRAGシステムでは、ベクトル検索のみが利用されることが多いですが、キーワード検索との組み合わせによるハイブリッド検索の実装を通じて、検索クエリの内容により焦点を当てた文書検索が可能となります。実装や計算コストもあまり必要ないので、検索精度の向上を図りたい方には、このハイブリッド検索のアプローチを採用することをお勧めします。
今後もRAGシステムにおける文書検索精度向上のための検証や、汎用的にRAGシステムを構築できるモジュール開発などに取り組んでいきたいと思います。
検索精度を向上させるためには
最後に文書検索の精度をさらに向上させるためのいくつかのアプローチを記載します。
- 高性能な形態素解析器の導入
TokenizerにBERTやMeCabなどの高性能な形態素解析器を導入することで、文書のトークン化精度を向上させることができます。 - 文書のクリーニングとストップワードの追加
文書をクリーニングし、Tokenizerにストップワードを追加することで、重要な単語に焦点を当てた検索を実現できます。 - 高精度なEmbeddingモデルの採用
精度の高いEmbeddingモデルを採用することで、文書とクエリの意味的関連性をより正確に捉えることが可能となります。リーダーボードでの高評価を参考に、最適なモデルを選択してみてください(参考:LeaderBoard)。 - セマンティックハイブリッド検索の実装
セマンティックハイブリッド検索を実装することで、より精度の高い検索を実現できます (参考:比較デモの後半部分)。
参考
本記事の執筆にあたっては、以下の記事を参考にさせていただきました。
- Azure Cognitive Search: Outperforming vector search with hybrid retrieval and ranking capabilities
- Azure Cognitive Search のベクトル検索とハイブリッド検索の比較デモネタ
- [自然言語処理/NLP] Okapi BM25についてざっくりまとめ (理論編)
- RAG質問応答システムに使うRetrieverの精度比較
- Embeddingモデル LeaderBoard