
Index
はじめに
データソリューション事業部の関田です。
本記事では、2024年10月にarXivに投稿された Differential Transformer (Tianzhu Ye, Li Dong, Yuqing Xia, Yutao Sun, Yi Zhu, Gao Huang, Furu Wei) という論文について解説します。特に、従来のTransformerとの違いや優位性について紹介していきます。
具体的な変更点を理解するためには、従来のTransformerを理解していることが要求されます。ただし専門的な知識が無くても、大雑把なイメージや、各種Transformerをベースとした言語モデルの性能比較の理解は可能ですので、参考にしていただけると幸いです。
1. 概要
Differential Transformer (DIFF Transformer) は、従来のTransformerの核であるAttention機構を改良したアーキテクチャです。改良したポイントは単純で、2つの異なるAttention Scoreを計算し、それらの差 (Differential Attention) を従来のAttentionと置き換える というものです。この変更により、従来のAttention機構に比べて、重要な情報にAttention Scoreが大きく付与され、重要でない情報にAttention Scoreが小さく付与されるようになりました。
この改良は言語モデルにおいて次のような利点を生み出します。
- 長文での精度低下を低減
- 情報検索の精度向上
- ハルシネーションの低減
- モデルサイズの削減
それでは、詳細を解説していきます。
2. 従来のTransformer
まずは従来のTransformerおよびAttention機構について、簡単に振り返ります。
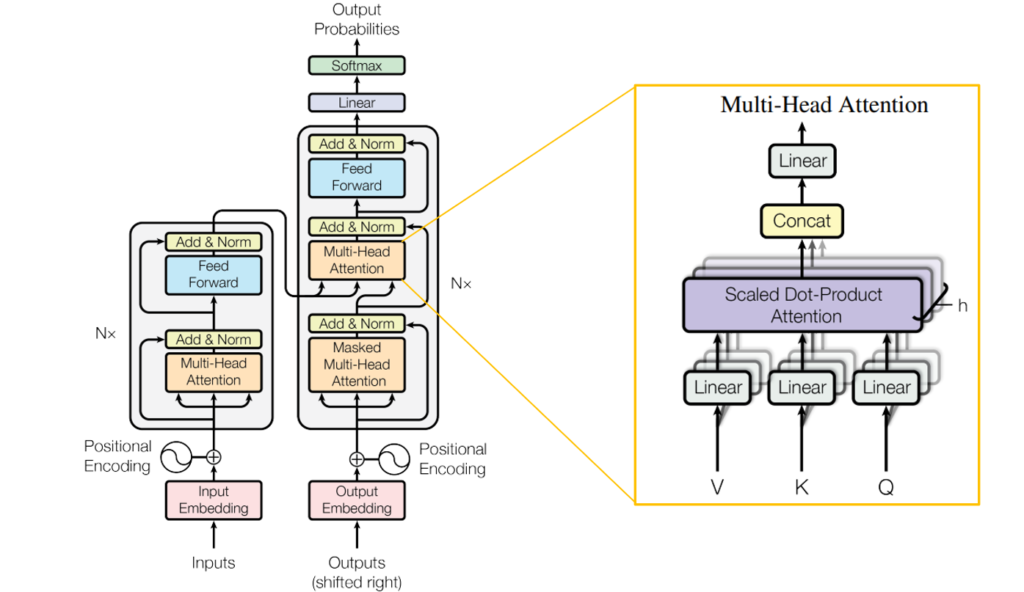
従来のTransformerは、図1左側のような全体像となっています。その中でも核となる (Multi-Head) Attention機構は図1右側のように構成されています。Attention機構では、入力からQuery, Key, Valueという3種類のベクトルを生成し、それらベクトルを用いてAttention Scoreを計算します。Attention Scoreは式 \((1)\) で表されます。
$$ \mathrm{Attention}(Q, K, V) = \mathrm{softmax}\biggl( \frac{QK^T}{\sqrt{d_k}} \biggr) V \tag{1} $$
ここで、\(Q, K, V\) はそれぞれQueryベクトル、Keyベクトル、Valueベクトルを表し、\(d_k\) はKeyベクトルとQueryベクトルの次元を表します。
自然言語におけるAttentionおよびAttention Scoreというのは図2のようなイメージです。
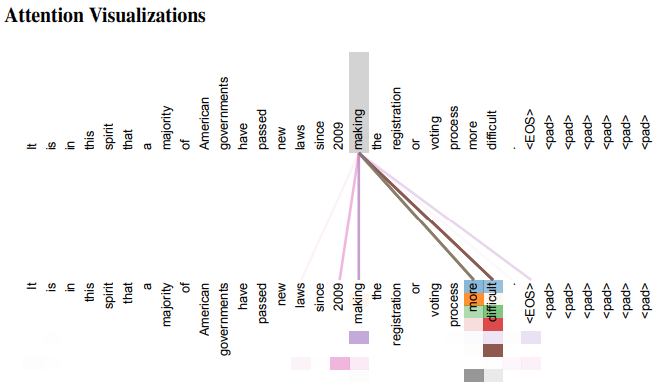
“making”という単語が同じ文中の各単語へ「どれだけ注意を払うか」がAttention Scoreです。“making”との関連が大きい“difficult”へのAttention Scoreが大きくなります。
このAttention機構を携えたTransformerの登場以来、言語モデルをはじめとする多くの深層学習モデルがTransformerをベースとして開発されています。
3. Differential Transformer
3.1. Differential Attention
Transformerの台頭により言語モデルは昨今凄まじい進化を遂げていますが、情報検索の精度、ハルシネーション、巨大なモデルサイズなどの課題は依然として指摘されています。
DIFF Transformerは従来のAttention機構を改良することによって上記のような課題を改善するアーキテクチャとして提案されています。改良されたAttentionはDifferential Attentionと呼ばれ、2つの異なるAttention Scoreを計算し、それらの差 (Differential Attention) を従来のAttentionと置き換えます。具体的には、図3および式 \((2)\) のように表されます。
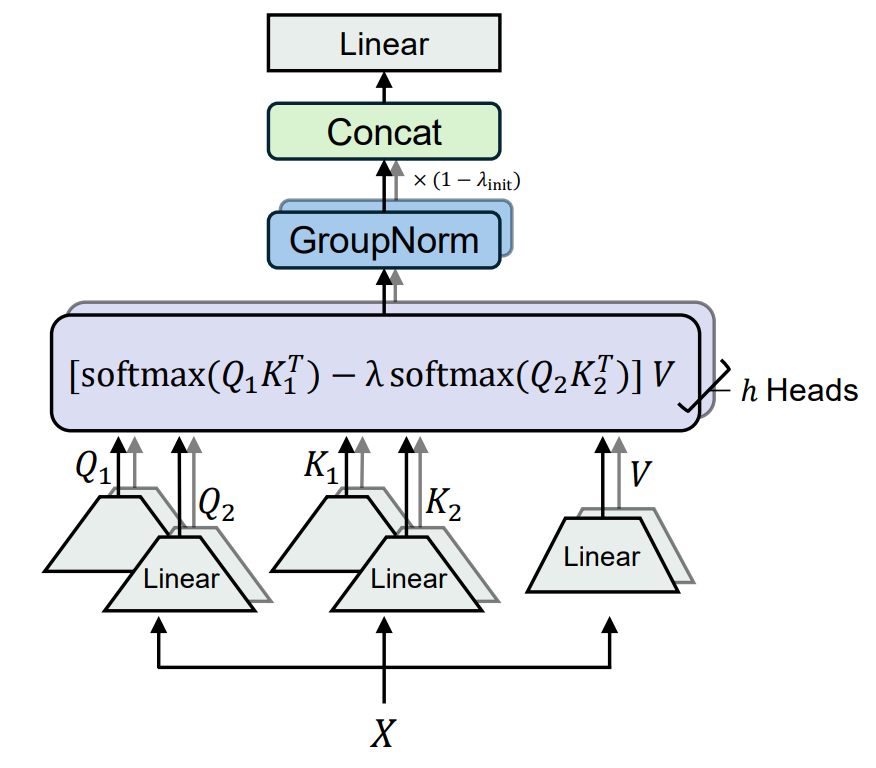
$$ \mathrm{DiffAttn}(X) = \left( \mathrm{softmax}\biggl( \frac{Q_1K_1^T}{\sqrt{d}}\biggr) -\lambda \ \mathrm{softmax}\biggl( \frac{Q_2K_2^T}{\sqrt{d}} \biggr) \right) V \tag{2} $$
ここで、\(X\) は入力を表し、\(Q_1, Q_2\) はそれぞれ \(X\) から作成された異なる2つの \(d\) 次元Queryベクトルです。\(K_1, K_2\) も同様のKeyベクトルであり、\(V\) は \(2d\) 次元のValueベクトルです。このように、Differential AttentionではQueryベクトルとKeyベクトルが2つずつ生成されます。\(\lambda\) は学習可能なパラメータです。
式 \((1)\) と式 \((2)\) を見比べることにより、Differential Attentionの新しさは「QueryベクトルとKeyベクトルを2つずつ作成し、2つのAttention Scoreの差を考えること」であることがわかります。これはヘッドホンのノイズキャンセリング機能などと同じ発想であり、逆位相の波を重ね合わせて余分な要素を打ち消し合っているイメージです。
なお、詳細な説明はここでは省略しますが、式 \((2)\) に続く標準化およびデータ結合の処理でも工夫がなされています。[1] の付録Fに記述がある通り、TransformerとDIFF Transformerでは同じハイパーパラメータを用いることが可能となっています。したがって、既存のTransformerベースモデルのTransformer部分をDIFF Transformerに置き換えるだけで新たなモデル作成が可能です。
3.2. Differential Transformerの利点
DIFF TransformerにおけるDifferential Attentionより得られる恩恵は、単一Attentionで生じる“Attention Noise”を軽減することです。ここでAttention Noiseとは、本来無関係な情報にAttention Scoreが付与されてしまうことです。Attention Noiseの発生により、本来重要な情報のAttention Scoreが相対的に大きくなりにくくなり、情報検索の精度低下などの課題につながります。
DIFF Transformerでは、式 \((2)\) で見たように、2つの異なるAttention Scoreを算出しその差を計算しています。これにより、2つのAttention計算で共通して生じるnoiseが打ち消し合うのです。
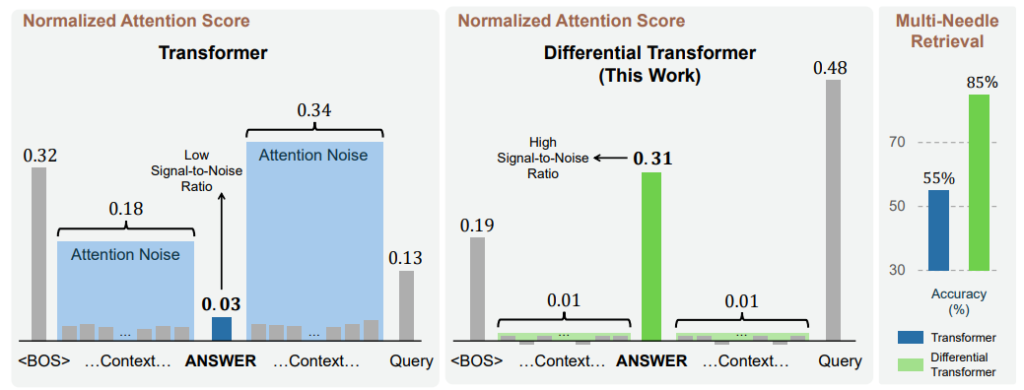
図4は、従来のTransformerとDIFF TransfomerにおけるAttention Noiseの比較(左、中央)および情報検索の精度の比較(右)です。従来のTransformerは正解の情報に対してAttention Scoreが0.03となっており、他の情報に対してあまり大きな値となっていません。Attention Noiseは合計0.52と、正解情報へのAttention Scoreよりも大きくなっています。一方、DIFF Transformerでは正解の情報に対して0.31のAttention Scoreが付与され、0.02のAttention Noiseに比べて約15倍も大きな値になっています。この結果、情報検索の精度は従来のTransformerが55%であったのに対し、DIFF Transformerでは85%にまで向上しています。
4. 性能検証:Transformer vs DIFF Transformer
論文中では大きく8つの検証がされていますが、ここではそのうちの4つをご紹介します。
4.1. 言語モデル性能比較
まずはTransformerベースの言語モデルとDIFF Transformerベースの言語モデルの一般的な性能を比較します。それぞれ3Bサイズの言語モデルを350Bトークンで訓練し、各種ベンチマークのスコアを算出しています。ベンチマークにはLanguage Model Evaluation Harness [3] を用いています。TransformerとDIFF Transformerの違い以外にモデル構成やハイパーパラメータの違いはありません。詳細は [1] の3.1節および付録Bをご参照ください。
7つのベンチマークに対して、zero-shotおよびfew-shotでの各モデルの結果は図5の通りです。
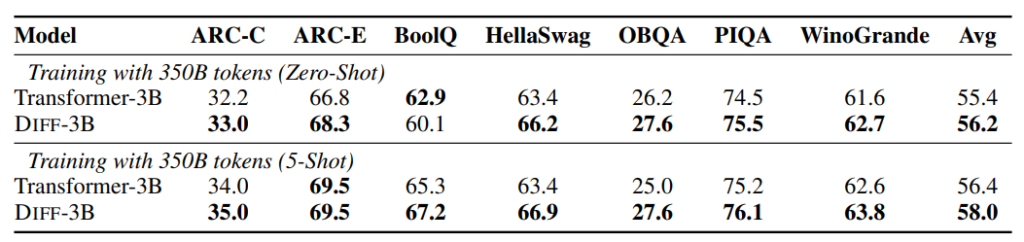
ほとんどの結果でDIFF Transformerが従来のTransformerを上回っていることがわかります。
4.2. モデルサイズ比較
言語モデルのパラメータ数と訓練に用いるトークン数をそれぞれ大きくしていき、サイズごとの性能(Loss)を比較します。Transformerベースの言語モデルとしてLLaMA [4] を使用し、DIFF Transformerでも同様の設定のモデルで実験を行います。
結果は図6の通りです。図6 (a) はモデルのパラメータ数を830Mから13.1Bまで大きくしていった結果を表し、図6 (b) は本記事の4.1節で挙げた3Bモデルに対して、訓練トークン数を40Bから360Bまで大きくした結果を表します。
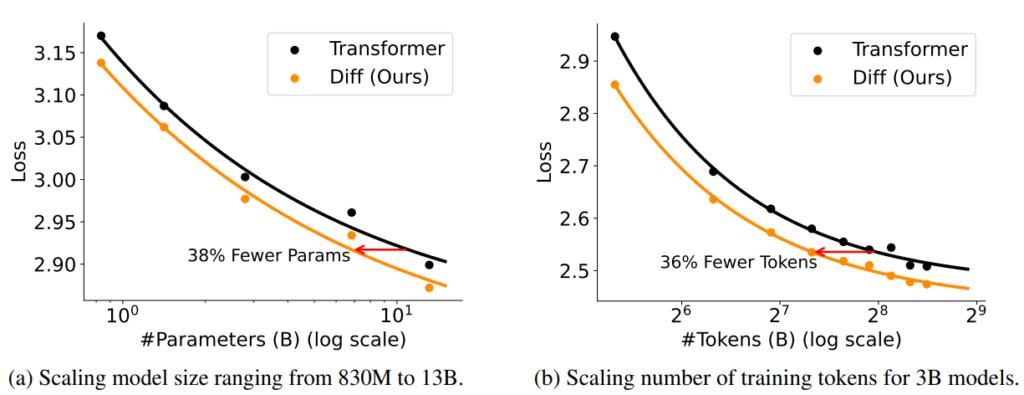
図6より、DIFF Transformerは従来のTransformerに比べて小さなモデルサイズで同等の性能を出すことがいえます。具体的には、以下のような値が算出されています。
(a) 7.8BサイズのDIFF Transformerモデルと13.1BサイズのTransformerモデルが同性能:40.5%のパラメータ数削減
(b) 160Bトークンで訓練したDIFF Transformerモデルと251Bトークンで訓練したTransformerモデルが同性能:36.3%の訓練トークン数削減
4.3. 情報検索の精度比較
The Needle-In-A-Haystack test [5] を用いて情報検索の精度を比較します。情報検索タスクの内容は、数字と都市名を紐づける文章が用意され、それをもとにクエリで与えられた都市名と紐づく数字を答えるというものです。与える文章の長さやクエリの数を変更して実験しています。
4.3.1. 短い文章に対する情報検索
文章の長さが4Kの場合の結果は図7の通りです。ここで、\(N\) は数字と都市名のペア数、\(R\) はクエリで与えられた都市数(答えるべき数字の数)です。\(N\) が大きいと、余計な情報が増えて難しいタスクとなります。

\(N, R\) が小さい場合、精度に大差ありませんがDIFF Transformerの方が高性能といえます。特に注目すべきは \(N\) が大きい場合で、\(N\) の増大に伴ってTransformerモデルでは精度が大きく減少する一方、DIFF Transformerモデルでは高精度を維持しています。\(N =6, R=2\) の場合では精度に30%もの差が生じています。
4.3.2. 長い文章に対する情報検索
文章がさらに長い場合の結果は図8の通りです。図8 (a) がTransformer、図8 (b) がDIFF Transformerの結果を表しています。各図の横軸は文章の長さ、縦軸は正解位置の文章中の位置であり、各長さ、位置に対応する精度が記載されています。
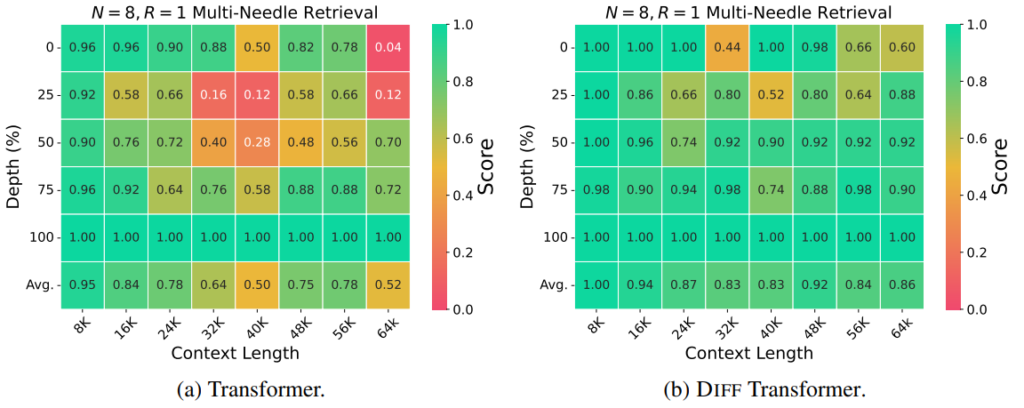
図8の2つを見比べると、全体的にDIFF Transformerの方が高精度であり、かつ、文章の長さや情報抽出位置に対する精度の依存度が小さいことがわかります。TransformerとDIFF Transformerで差が最も顕著であった箇所(64KのDepth 25%)では、DIFF Transformerの方が76%も精度が高いという結果となりました。
4.3.3. Attention Score
最後に、図9で正解位置に対するAttention Scoreと、Attention Noiseについても比較します。図9の上部0%, 25%, …, 100%というのは、図8と同様に正解位置を表します。

図9より、DIFF Transformerは正解位置へのAttention ScoreがTransformerの約4倍から10倍大きく、Attention Noiseは約25倍から50倍小さいことが確認できます。
4.4. ハルシネーション比較
本記事の4.1節で挙げた3Bモデルで要約と質疑応答タスクを行い、ハルシネーションについて評価・比較を行います。ハルシネーションの評価には、人間の評価に近いとされるGPT-4oを用いた手法 [6] を適用しています。
結果は図10の通りです。図10 (a) が要約の正答率、図10 (b) が質疑応答の正答率を表しています。それぞれ3つのデータセットを用いて評価を行っています。

図10から分かる通り、要約および質疑応答ともに、DIFF Transformerは従来のTransformerに比べて高い正答率を出しました。つまり、DIFF TransformerはTransformerに比べて与えられた文章から得られる情報をより正確に出力し、ハルシネーションを低減していることがいえます。
おわりに
今回はDifferential Transformerという新たなアーキテクチャを提案する論文を紹介しました。昨今大きな話題となっている言語モデルを基礎から進化させる技術として、DIFF Transformerが今後注目を浴びていくことは想像に難くないでしょう。言語モデルをはじめとする生成AIのこれからには目が離せません。
参考
[1] Tianzhu Ye, Li Dong, Yuqing Xia, Yutao Sun, Yi Zhu, Gao Huang, Furu Wei. Differential Transformer. arXiv preprint arXiv:2410.05258v1, 2024.
[2] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention Is All You Need. arXiv preprint arXiv:1706.03762v7, 2017.
[3] Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework for few-shot language model evaluation. Zenodo, 2024.
[4] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. LLaMA: Open and Efficient Foundation Language Models. arXiv preprint arXiv:2302.13971v1, 2023.
[5] Greg Kamradt. Needle in a Haystack – pressure testing LLMs. GitHub, 2023.
[6] Yung-Sung Chuang, Linlu Qiu, Cheng-Yu Hsieh, Ranjay Krishna, Yoon Kim, James Glass. Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps. arXiv preprint arXiv:2407.07071v2, 2024.
オウンドメディアも運営しています
- Meridianとは?Googleの新MMMを徹底解説!| Data Analytics Magazine (dalab.jp)
- コレスポンデンス分析とは?ビジネス活用や注意点を解説! | Data Analytics Magazine (dalab.jp)
- 因子分析とは?ビジネス活用や注意点を解説! | Data Analytics Magazine (dalab.jp)
- 需要予測とは?今すぐ役立つ分析手法・活用事例を厳選して紹介!
- MMM(マーケティング・ミックス・モデリング)とは? | Data Analytics Magazine (dalab.jp)
- 「0,1判別」の定番手法!ロジスティック回帰分析とは? | Data Analytics Magazine (dalab.jp)