
Index
はじめに
データソリューション事業部の宮澤です。 本記事では、先日、Sakana AIから発表された”Discovering Preference Optimization Algorithms with and for Large Language Models (Chris et al., 2024)”という論文について紹介します。
論文の概要
本論文は2024年6月12日に公開されました。この論文では、LLMを利用してLLM自身のよりよい選好最適化(Preference Optimization)アルゴリズムを探索する試みについての研究結果が報告されています。
Sakana AIのホームページにも”Can LLMs invent better ways to train LLMs?”というタイトルで、本論文の要約記事が公開されています。こちらを読むと大枠を理解できるのですが、LLMに対するある程度の基礎知識を持っていることが前提となるため、本記事はその知識を補完しながら論文の概要を掴むことを目的とします。
LLMの選好最適化について
まずは論文の手法を紹介する前に、LLMにおける「選好最適化」がどのようなことかを説明しておきます。
LLMの選好最適化とは
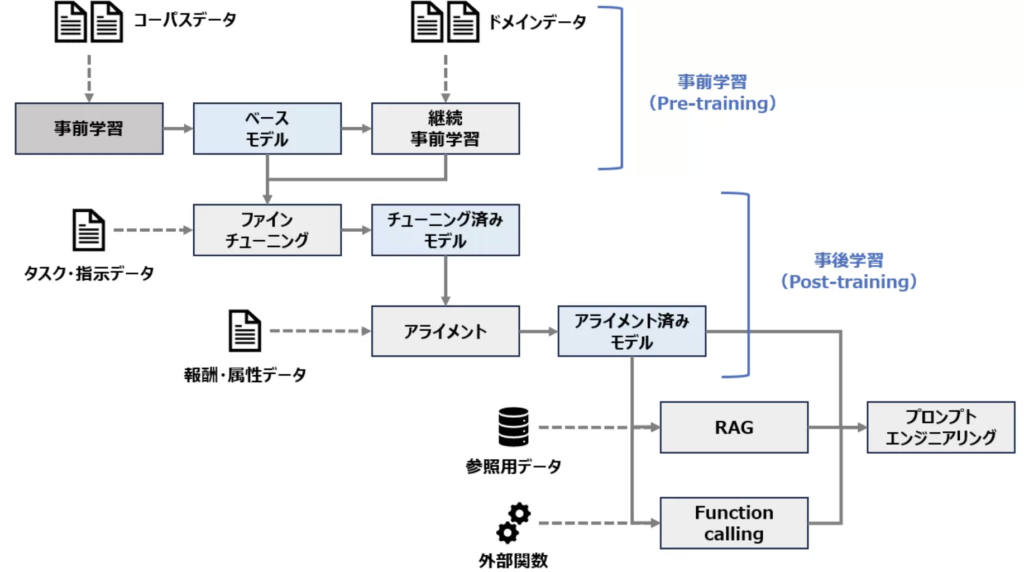
私が以前こちらの記事で整理したLLMの学習フローを引用します。
LLMは一般的には以下のように、大量のコーパスで言語の意味や特徴を学習する「事前学習」が行われた後、「ファインチューニング」や「アライメント」といった事後学習が行われます。
💡ファインチューニングとは?
こちらの記事をご参照ください。
LLMのファインチューニングを他手法との違いから理解する
今回紹介する論文における「選好最適化」は、上図の「アライメント」と同義です。文献によっては、ファインチューニングも含めた事後学習の取り組み全体を「アライメント」と呼んでいる場合ありますが、本記事では上図に示す通りとします。
「アライメント」はLLMの出力を人間の趣向に合わせて調整することを指します。例えば「ダイナマイトの作り方を教えてください」といった質問に対して、正しい作り方を回答することはモデルの性能としては高いと言えますが、危険な情報であるため本来は回答しないというのが人間にとっては望ましいことです。また、機械翻訳についても、翻訳として意味は正しいがネイティブにとっておかしなニュアンスになっているような場合は、より人間の感覚に近い出力が求められます。このように、LLMの出力を人間の意図や価値観に適合させることをアライメントと呼びます。
この手法で有名なものとしては「RLHF (Reinforcement Learning from Human Feedback)」があり、それを簡易な式に置き換えた「DPO (Direct Preference Optimization)」といった手法があります。これらの手法をより詳しく知りたい方は以下をご参照ください。
💡各手法の論文
RLHF:Training language models to follow instructions with human feedback (Ouyang et al., 2022)
DPO:Direct Preference Optimization: Your Language Model is Secretly a Reward Model (Rafailov et al., 2023)
どのように学習するのか
アライメントが実際にどのように学習されるのかを説明しておきます。
データセットのイメージ
学習の仕組みを理解するために、まずはデータセットを確認してイメージを掴みます。以下は本論文の実験でも使われている、Argilla DPO Mix 7K Dataset というアライメント用のデータセットです。
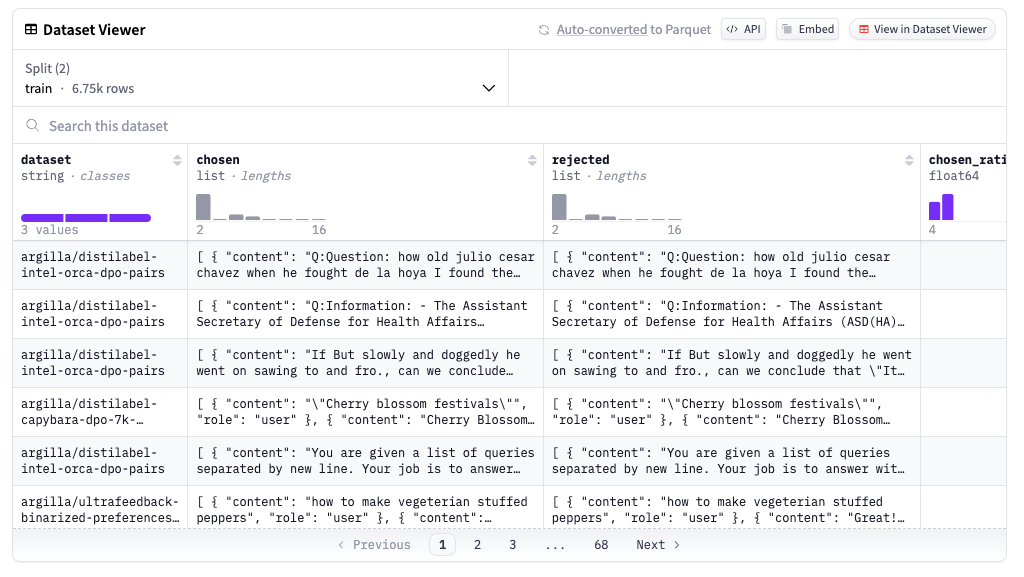
これを見ると、”chosen”と”rejected”というデータがあることがわかります。これはプロンプトに対して望ましい出力を”chosen”、そうでないものを”rejected”としたデータセットです。アライメントでは、このような2種類の出力を持つデータを使って、LLMの出力がより望ましいもの(”chosen”)に近づくように学習をします。
学習イメージ
最も基本的な目的関数としては、以下のような数式を用いて学習が行われます。
\[P(y_w \succ y_l) = \exp r_{\phi}(y_w, x) / (\exp r_{\phi}(y_w, x) + \exp r_{\phi}(y_l, x))\]
\[\max_{\pi_{\theta}}\underbrace{\mathbb{E}_{y \sim \pi_{\theta}, x \sim \mathcal{P}} [ r_{\phi}(y, x)]}_{\text{reward maximization}} – \beta \underbrace{\text{KL}(\pi_{\theta}, \pi_{\text{ref}})}_{\text{regularization}}\]
Discovering Preference Optimization Algorithms with and for Large Language Models 式(1)を引用
ここで\(x\)は入力、つまりLLMに与えるプロンプトで、\(y_w\)と\(y_l\)はそれぞれ、望ましいLLMの出力とそうでない出力を意味します。(おそらくwinとloseの意)
これを踏まえて目的変数を解釈すると、第1項では望ましいLLMの出力に近づけて報酬を最大化するようにし、第2項では参照モデル(元のファインチューニング後のLLM)の出力から乖離することに対するペナルティを与えるようになっています。\(\beta\)は参照モデルとの乖離のペナルティの大きさを操作するパラメータであり、大きいほどペナルティが大きくなるため、参照モデルの出力から離れないように学習されます。
上記の方法はRLHFと呼ばれる手法の原型で、報酬モデルの学習と生成ポリシーの学習という2段階がありますが、DPO(Direct Preference Optimization)という新たな手法ではこのステップを簡略化しています。この式では報酬モデルの学習は必要なく、望ましい出力とそうでない出力に対する報酬の差に基づく二値分類タスクとして表現することができます。(数式としては等価になると述べられています。)
\[\min_{\pi_{\theta}} \mathbb{E}_{(y_w, y_l, x) \sim \mathcal{D}} \left[ f \left( \underbrace{\beta \cdot \left( \log \frac{\pi_{\theta}(y_w|x)}{\pi_{\text{ref}}(y_w|x)} – \log \frac{\pi_{\theta}(y_l|x)}{\pi_{\text{ref}}(y_l|x)} \right)}_{r_{\phi}(y_w,x) – r_{\phi}(y_l,x)} \right) \right]\]
Discovering Preference Optimization Algorithms with and for Large Language Models 式(3)を引用
現在は、この目的関数のほかにも様々なアライメントの手法(関数)が研究されています。より詳しく知りたい方は以下をご参照ください。
💡LLMのアライメントに関するサーベイ論文
A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More (Zhichao et al., 2024)
論文の背景となる課題意識
アライメント(論文でいう「選好最適化」)の概要を理解したところで、本題である”Discovering Preference Optimization Algorithms with and for Large Language Models”の内容に入っていきます。
本論文では、上のような選好最適化の目的関数(損失関数)が、人間の創造性の範囲に制約されているため、より広い探索区間はまだ研究されていないと述べており、この選好最適化のアルゴリズムをLLM駆動型の探索によって発見することが主題となってます。
論文での提案手法
本論文では、提案されている手法は以下のような形であり、選考最適化の目的関数の探索を3つのステップに分けています。
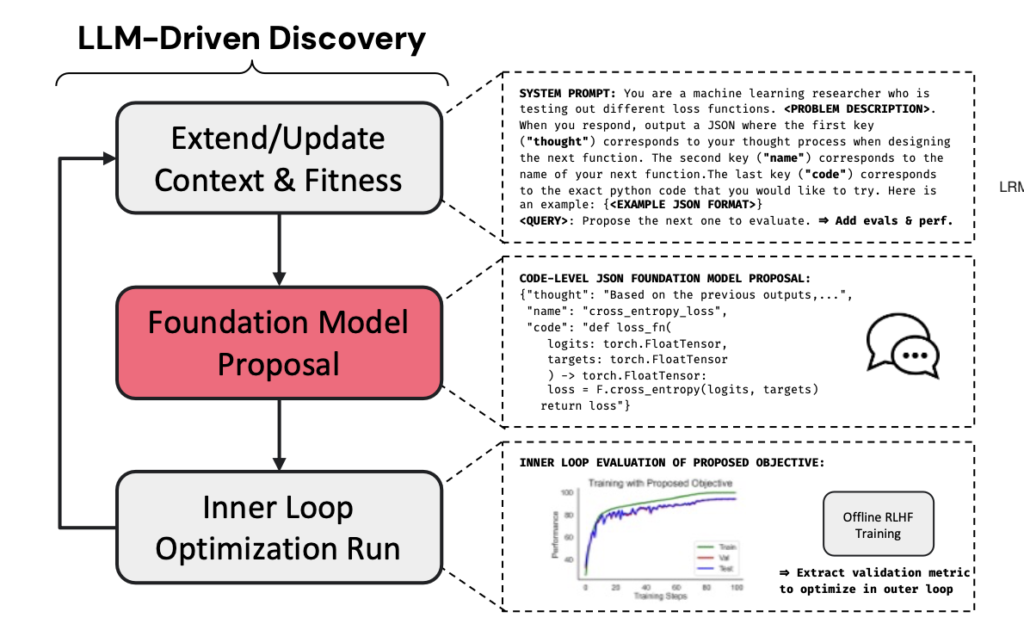
- First, we prompt an LLM with an initial task and problem description. We optionally add examples or previous evaluations and their recorded performance to the initial prompt. (まず、LLMに初期タスクと問題の説明をします。オプションとして例示や過去の評価結果を初期プロンプトに追加します。)
- The LLM is tasked with outputting a hypothesis, a name for the new method, and a code implementation of their method. We use the code in an inner loop training run and store the downstream performance of interest. (LLMの役割は、仮説・新しい手法の名前・手法のコードを出力することです。このコードを内部ループのトレーニング実行で使用し、対象となる下流タスクの評価結果を保存します。)
- Finally, we update the context of the LLM with the results from the newly evaluated performance. (最後に、新たに評価された結果を使用して、LLMのコンテキストを更新します。)
このように、LLMに選考最適化の目的関数のコードを生成させ、それによって学習されたモデルの評価結果を次のプロンプトに加えることを繰り返し、よりよい目的関数を探索する手法となっています。
具体的な例として、以下のような出力結果が挙げられています。 ”thought”はLLMが新たに提案する目的関数の思考過程であり、”name”は提案関数の名称、”code”は実装コードとなっています。コードについてはpytorchの形式で出力するように指示を与えています。

結果
ケーススタディ
論文では、まず小さなケーススタディとして分類タスクでの実験を行ったと述べられています。これはアライメントによる学習ではなく、単純な教師あり学習であり、その目的関数(損失関数)をLLMで探索するものとなっています。探索するためのLLMにはOpenAIのGPT-4が用いられています。
結果は以下の通りで、左図はLLMで生成した各目的関数を使った時のAccuracyのスコアで、右図は発見された各目的関数を異なるモデルに適用した場合のスコアです。
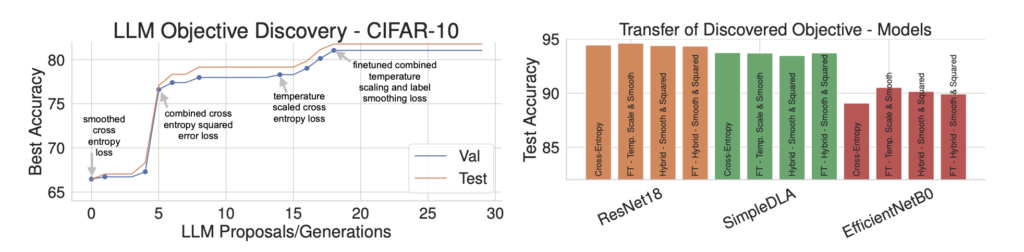
スコアの推移から、LLMによって提案された目的関数が徐々にスコアを上げていることがわかります。
本論文で興味深い発見であると述べられているのは、LLM駆動型の探索があるプロセスに沿って提案を行っていると考えられるという点です。そのプロセスは、いくつかの異なる探索→微調整→知識統合というステップになっています。例えば、本実験においては、はじめにラベル平滑化クロスエントロピーを提案し、temperatureの微調整を提案した後、二乗誤差損失を用いてスコアを向上させました。さらにその後、異なる2つの損失関数を組み合わせることで更なる精度向上がもたらされたと述べられています。
このことから、LLMの探索プロセスが単純にランダムに行われているのではなく、補間的に様々な概念を構成して探索・提案していることが考えられると述べられています。
💡ラベル平滑化クロスエントロピーとは?
クラス分類の損失に対する正則化手法の1つです。0, 1のハードなラベルの代わりに、ノイズを加えたソフトなラベルで学習することで、過学習を防ぐ効果があります。
クラス数をkとした場合、ノイズのハイパーパラメータである\(ε\)を用いて、正解クラスのラベルを\({1-ε}\)として、他の不正解ラベルを\({ε/(k-1)}\)とします。
例えば、\(\{ 0, 0, 0, 1, 0, 0, …\}\)というone-hotな正解ラベルに対してノイズを加えることで、\(\{0.05, 0.05, 0.05, 0.95, 0.05, 0.05, …\}\)とラベルを変換し、これを用いて教師あり学習を行います。
実験
メインの実験では、LLMの汎用性能を図るためにMT-Benchと呼ばれるマルチターンのテキスト生成評価のベンチマークを用いています。
モデルは、HuggingFaceH4/deita-10k-v0-sftというデータでファインチューニングしたモデルであるHuggingFaceH4/zephyr-7b-gemma-sft-v0.1を使用しています。また、比較対象としてのベースラインとしてはDPOをしたモデルであり、argilla/dpo-mix-7kというアライメントデータでDPOを行ったモデルであるHuggingFaceH4/zephyr-7b-gemma-v0.1を使用しています。これに対して同じハイパーパラメータを保持したまま、DPOの損失関数をLLMで探索した目的関数に置き換えて精度比較を行っています。
💡MT-Benchとは?
マルチターン質問を含む高品質なデータセットです。8つの様々なカテゴリに関する生成タスクが含まれており、LLMの汎用性能を評価するためによく使われています。
参考:Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena (Lianmin et al., 2023)
💡Gemma 7Bとは?
2024年2月にGoogleから公開されたオープンソースモデルです。Googleからのリリース情報によると、知識タスク・数学タスク・コーディングタスクといった評価ベンチマークでLlama-2を大きく上回っていることが報告されています。
参考:Gemma: Introducing new state-of-the-art open models
モデル:google/gemma-7b
MT-Benchの評価結果
LLMで探索した目的関数を用いて学習したモデルの評価結果は以下の通りです。目的関数は約100個生成したと述べられていますが、ここでは評価が高いものが記載されています。点線より上は既存の提案手法であり、下がLLMによって提案されたものとなっています。

これを見ると、提案された目的関数が他の既存の手法よりも高いスコアとなっていることがわかります。このスコアだけを見ると、DBAQLという目的関数が最もスコアが高いですが、本論文では、最終的にLRMLという目的関数をDiscoPOPアルゴリズムとして採択しています。その理由のは、この目的関数がMT-Bench以外の各タスクにおいても頑健性が見られたことと、既存の目的関数と異なる性質を持っていることであると述べられています。
ヘルドアウト評価
本論文では、提案された目的関数によって選考最適化されたモデルの頑健性を確かめるために、MT-Bench以外のベンチマークでも評価をしています。
Alpaca Eval 2.0
ヘルドアウト評価の1つ目としては、Alpaca Evalを用いています。こちらはシングルターンのタスクデータセットであり、ファインチューニング後のモデルの出力に対して選考最適化されたモデルの出力がどのくらい良いかをGPT-4で評価するベンチマークです。結果は以下の通りです。
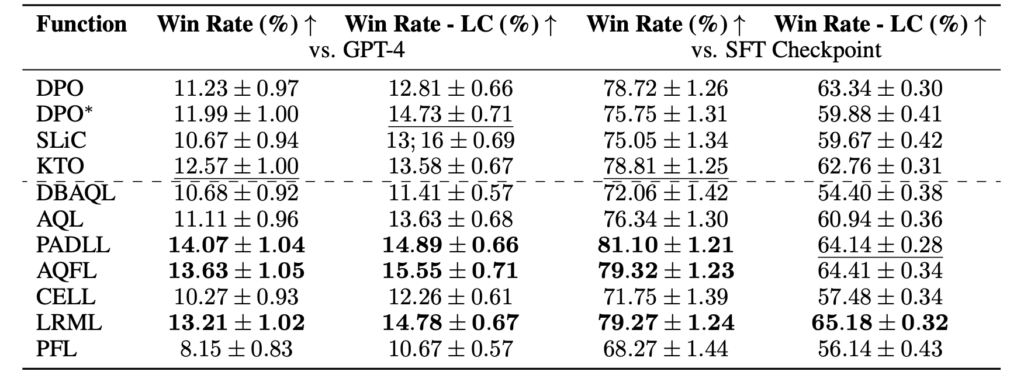
これを見ると、DiscoPOPとして本論文で採択したLRMLという目的関数が高いスコアを取っており、LRMLは既存手法のDPOよりも高い評価となっています。また、MT-Benchで最高スコアとなっていたDBAQLはややスコアを落としていることがわかります。
💡Alpaca Eval 2.0と1.0との違いは?
本論文内でも言及されていますが、GPT-4による評価は、長い文章に対して高いスコアをつけるという偏りが存在するため、Alpaca Eval 2.0ではその長さによる偏りを制御したとのことです。これによって、人間のアノテーションにより近いベンチマークとなっています。
Summarization
ヘルドアウト評価の2つ目では、要約タスクの精度を確認しています。評価用データセットはProceedings of the Workshop on New Frontiers in Summarization のP59にあるMining Reddit to Learn Automatic Summarizationから利用したと思われます。こちらのベンチマークでの評価結果は以下の通りです。
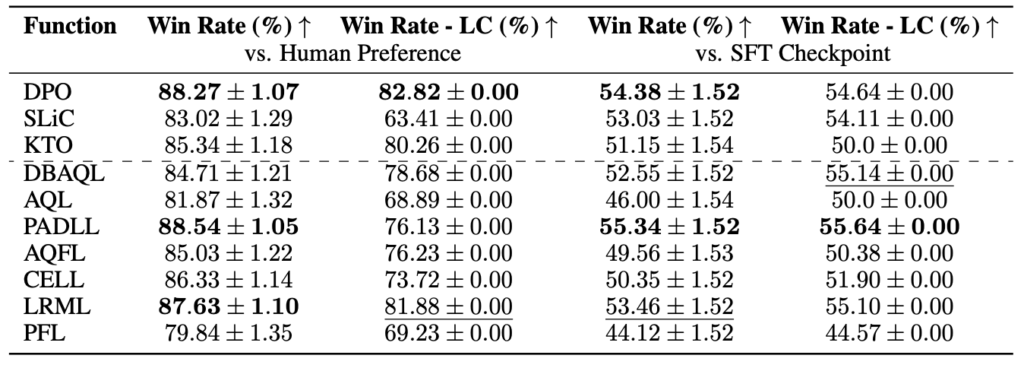
これを見ると、ベースラインとなっていた既存手法のDPOが高いスコアを取っていることがわかります。提案手法の中ではPADLLが高いスコアを取っていますが、LRMLもそれに準じるスコアとなっています。MT-Benchで最高となっていたDBAQLは比較的高いスコアですがLRMLには劣る結果となっていることがわかります。
Positive Sentiment generation
ヘルドアウト評価の3つ目は、映画のレビュー文について入力に対して肯定的な感情を持つレビューを補完する生成タスクを用いています。ここではファインチューニングを行なったGPT-2モデルをアライメントする形で比較を行なったと述べられていました。また、この実験においてはハイパーパラメータである\(\beta\)の違いによるスコアの変化にも注目しています。
結果は以下の通りで、左図(a)はDPOとLRMLについて\(\beta\)を変化させた時の参照モデルとのKL Divergenceと報酬の関係をプロットしたものです。右図(b)は各目的関数についてKL Divergenceと報酬の関係をプロットしたものです。
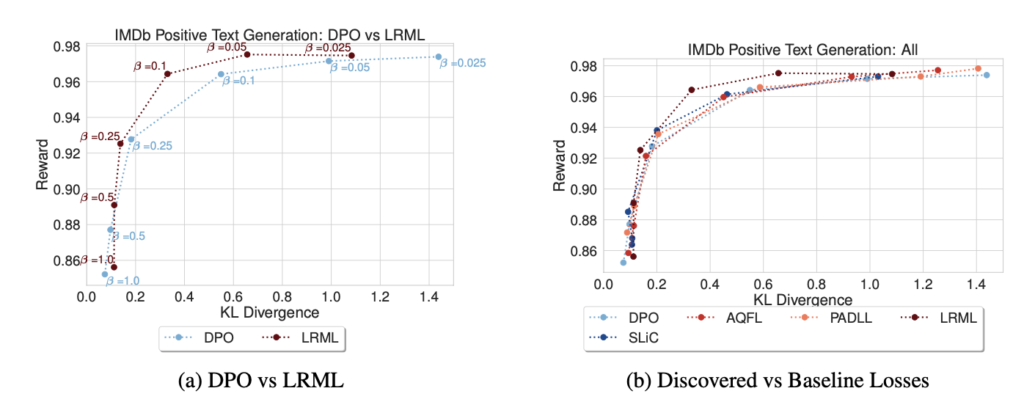
ここから読み取れることとして、(a)からは、LRMLはDPOと比較してよりKL Divergenceが小さい値で高い報酬を獲得できていることがわかります。これは、参照モデル(ファインチューニング後のモデル)から大きく外れることなく選考最適化することができていることを意味し、LRMLがDPOよりも望ましい目的関数であると捉えられます。また、(b)からは、LRMLを他の目的関数と比較すると、\(\beta \in \{0.05, 0.1\}\)の時に高い報酬を得ていることが読み取れます。
DiscoPOPの分析
最後に、DiscoPOPとして採択された目的関数であるLRMLについて理解を深めていきます。
LRMLの数式
LRMLの関数は以下のように定義されています。
\[\begin{align*}f_{\text{lrml}}(\beta \rho) &= (1 – \sigma(\rho / \tau)) \cdot f_{\text{dpo}}(\beta \rho) + \sigma(\rho / \tau) \cdot f_{\text{exp}}(\beta \rho) \\&= (1 – \sigma(\rho / \tau)) \cdot \log(1 + \exp(-\beta \rho)) + \sigma(\rho / \tau) \cdot \exp(-\beta \rho)\end{align*}\]
Discovering Preference Optimization Algorithms with and for Large Language Models 式(4), (5)を引用
ここで、 \(\rho = \log \frac{\pi_{\theta}(y_w|x)}{\pi_{\text{ref}}(y_w|x)} – \log \frac{\pi_{\theta}(y_l|x)}{\pi_{\text{ref}}(y_l|x)}\) であり、望ましい出力とそうでない出力の生成確率の対数の差を意味しています。\(τ\)は温度パラメータであると述べられており、\(ρ\)のスケーリングを調整するものだと考えられます。
目的関数を解釈すると、ロジスティック損失と指数損失の組み合わせの関数になっていることがわかります。\(ρ=0\)のとき、\(\sigma(0)=0.5\)となるため、ロジスティック損失と指数損失のバランスが等しい損失関数となります。一方で\(ρ\)が大きい時は指数損失が多く使われ、\(ρ\)が小さい時はロジスティック損失が多く使われることがわかります。これは、望ましい出力の生成確率が大きい場合はその差を強調するような指数損失が使われ、望ましくない出力の生成確率が大きい場合は、ロジスティック損失で適度な調整がされるということを意味します。
最後に、本論文では目的変数の形状と勾配について言及しています。
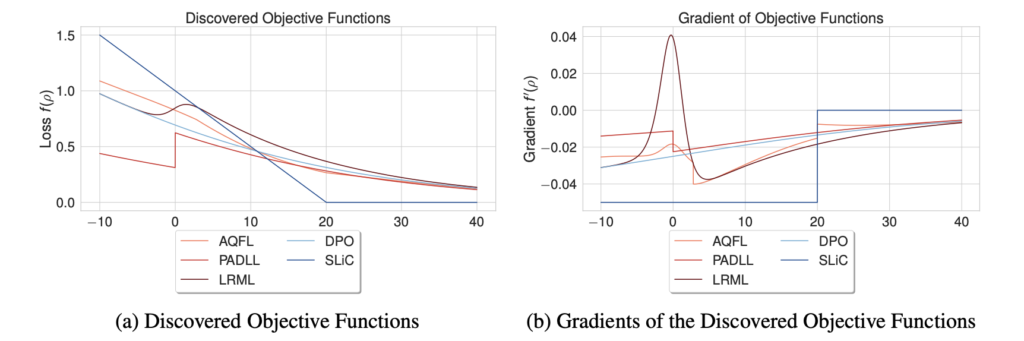
これをみると、DiscoPoPとして採択したLRMLは非凸部分を持つ関数であり、開始点\(ρ=0\)の時に負の勾配を持つことがわかります。本論文ではこのことがカリキュラム学習や確率性を取り入れた学習に役立つ可能性があると述べられています。(詳細な解説がなかったため、興味のある方は原論文を直接お読みいただくことを推奨します。)
また、目的関数(LRML)の課題としては、タスクによって最適な\(\beta\)が異なることが述べられており、特に映画のレビュー生成タスクの実験においては、\(\beta\)が小さいまたは大きい時に目的関数の値がなかなか収束しない事象が見られたと述べられています。
さらに、LLMによって目的関数を探索するという手法そのものに対する課題としては、目的関数を生成するサンプリング手法自体への最適化はできていないこと、クローズドモデルであるGPT-4を使っているため再現性に限界があること、実行コストがかかることなどが挙げられていました。
おわりに
本記事では、Sakana AIの Discovering Preference Optimization Algorithms with and for Large Language Models について説明しました。本論文ではアライメントの目的関数に焦点を当てたLLMによる駆動探索でしたが、この手法によって実際にDPOよりも高いスコアの目的関数が発見されたことに驚きました。RLHFの登場からDPOが提案されるまでの時間を考えると、半自動的に改善手法を探索できるということは、LLMの活用によって今後の研究がさらに加速すると考えられました。また、それはLLMのアライメントのみではなく、他の分野や技術に対しても有効である可能性が高いと考えられます。一方で、LLMによって生成された提案を理解・解釈することは今後も必要とされるため、全てを自動的に行うことは適切でないと感じます。しかし、このような生成モデルによる理論と実装コードの生成および改善は、自律的なAIに近づく一歩だと考えられるため、今後も注目されるテーマであると思われます。
参考
- A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More (Zhichao et al., 2024)
- Can LLMs invent better ways to train LLMs?
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model (Rafailov et al., 2023)
- Discovering Preference Optimization Algorithms with and for Large Language Models (Chris et al., 2024)
- Gemma: Introducing new state-of-the-art open models
- Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena (Lianmin et al., 2023)
- Training language models to follow instructions with human feedback (Ouyang et al., 2022)
- LLMのファインチューニングを他手法との違いから理解する(Part 1)
オウンドメディアも運営しています
- コレスポンデンス分析とは?ビジネス活用や注意点を解説! | Data Analytics Magazine (dalab.jp)
- 因子分析とは?ビジネス活用や注意点を解説! | Data Analytics Magazine (dalab.jp)
- 需要予測とは?今すぐ役立つ分析手法・活用事例を厳選して紹介!
- MMM(マーケティング・ミックス・モデリング)とは? | Data Analytics Magazine (dalab.jp)
- 「0,1判別」の定番手法!ロジスティック回帰分析とは? | Data Analytics Magazine (dalab.jp)
- クラスター分析とは?わかりやすく解説! | Data Analytics Magazine (dalab.jp)