
Index
はじめに
データソリューション事業部の宮澤です。
本記事は「LLMのファインチューニングを他手法との違いから理解する」のPart 2です。Part 1をまだお読みでない方はぜひPart 1からご覧いただければ幸いです。
LLMのファインチューニングを他手法との違いから理解する(Part 1)
Part 1では初期の事前学習を終えたLLMのベースモデルに対する様々なカスタマイズ手法を見ていきました。また、それらの手法と比較することで、本記事で焦点を当てている「ファインチューニング」の役割を定義しました。 これを念頭に置いて、Part 2ではファインチューニングの活用イメージや、機能開発の際の検討ポイントについて解説していきます。
ファインチューニングの活用イメージ
Part 2ではファインチューニングについて深掘りしていきます。まずはLLMをファインチューニングするにあたって、どのようなタスクがあるのかを見ていきます。
LLMのタスク
LLMを活用したいタスク例としては以下のようなものがあります。
- 文章分類
あらかじめ決めた分類やトピックに対して、テキストがどの分類に属するかを判定する。 - 自然言語推論
テキスト同士の間に成り立つ論理的関係(矛盾・含意など)を判定する。 - 意味的類似度計算
テキスト同士の間の意味的な類似度を計算する。 - 選択式問題
問題のテキストに対して選択肢から妥当なものを選択する。 - 潜在意味解析
テキストに含まれるトピックを推定する。 - 固有表現抽出
テキストから特定の人物や場所などの固有表現を抽出して、人名や地名など事前に決めたラベルに分類する。 - プログラミングコードの生成
自然言語による指示に対して適切なプログラミングコードを生成する。 - 機械翻訳
テキストの意味を保持したまま、別の言語に置き換える。 - 自由対話
選択肢を用意せずオープンな自然言語でのやり取りを行う。 - 文章要約
テキストの意味を理解して短くまとめる。
ここで理解しておきたいことは、ファインチューニングの難易度はタスクによって異なるということです。難易度を測る考え方は様々だと思いますが、ここでは「データセットの準備のしやすさ」と「評価指標の設計のしやすさ」という観点で考えます。
難易度が低いタスク例
「文章分類」や「自然言語推論」が該当します。これらは入力が文章であり、出力がラベル(ラベルA, ラベルB)に対するスコアとなります。文章分類の中でも感情分析などは公開データセット多くあり、データセットの準備は比較的容易であると言えるでしょう。また、これらのタスクは出力形式がラベルに対するスコアと決まっており、これは従来の分類タスクと変わらないため、評価指標も一般的な分類タスクで利用する適合率・再現率・F1スコアなど、代表的な指標を転用することができます。したがって、これらのタスクはデータセットが準備しやすく、かつ評価がしやすいタスクであると言えます。
難易度が高いタスク例
「機械翻訳」や「文章要約」が該当します。これらは入力が文章であり、出力も文章となります。これらのタスクは正解となる出力テキストを明確に決めることができない点に難しさがあります。例えば機械翻訳では、意味的に合っているとしても言語特有の言葉の使い回しなどが反映されているかどうかも評価する必要があるでしょう。また、文章要約では正解となる要約文に直接的に近くなくても、より適切な要約文が存在する可能性があります。したがって、データセットの準備と評価指標の設計がどちらもしにくいタスクであると言えます。
Instruction Tuning
上では特定のタスクについて説明しましたが、ChatGPTなどから分かるように、現在の高性能なLLMは、プロンプトの指示次第で対話も分類も汎用的にこなせるようなモデルとなっています。これはInstruction Tuningというファインチューニング手法によるもので、「対話」「翻訳」「要約」など、明示的な指示プロンプトを与えればそれらのタスクを汎用的にこなせるように、様々なデータセットで学習を行って汎用的な性能を獲得しています。
Instruction Tuningは、Finetuned Language Models Are Zero-Shot Learners (Wei et al., 2021)という論文で紹介された技術であり、端的にいうと「様々なタスクを指示と回答という形式に統一したデータセット用いて学習させる」というファインチューニングの方法です。
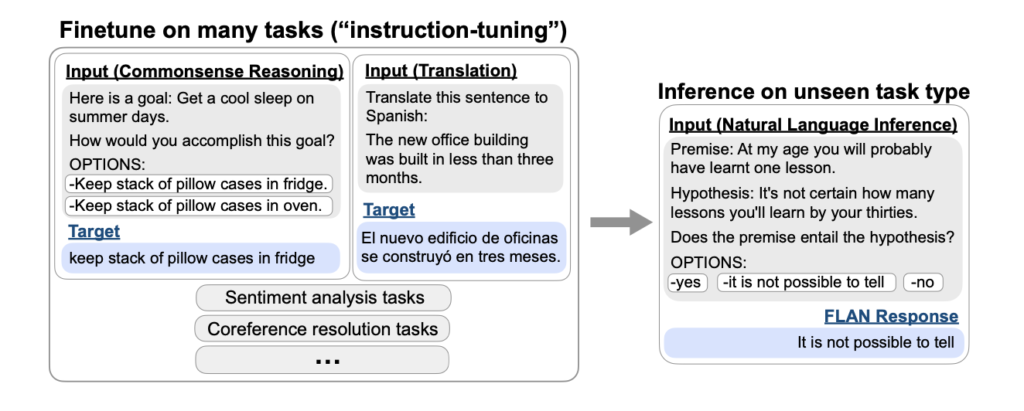
本論文ではInstruction Tuningによってゼロショット(プロンプトで例示をしない)での性能が向上したことが示されています。また、オープンソースで公開されているモデルの多くはベースモデルと呼ばれる事前学習までのモデルと、Instruction Tuningを行った指示応答モデルが公開されています。
ファインチューニングはドメイン知識の獲得に使える?
Microsoftのから発表されたFine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs (Ovadia et al., 2023)では、LLMのドメイン知識獲得にはファインチューニングよりもRAGが適していることが報告されています。これにはRAGが動的にドメイン知識を外部から取得できることや、ファインチューニングによってパラメータを更新したことで事前学習した知識を一部忘却している可能性があることが要因であると考察されています。
ただし、本研究におけるファインチューニングは、本記事で焦点を当てている教師あり学習ではなく、継続事前学習と同じような教師なし学習であるため、教師ありファインチューニングによって改善する可能性はあります。
しかしながら、外部ドメイン知識が定期的に更新されるような場合、その都度ファインチューニングの学習コストが発生するといったことも考慮すると、やはりドメイン知識獲得にはファインチューニングよりもRAGが適していると言えるでしょう。
ファインチューニングの設計
ここからは、実際にLLMをファインチューニングする際にどのようなことを検討する必要があるのかを整理していきます。
本記事のスコープ
前提として、本記事ではファインチューニングによる機能開発部分に焦点を当てます。機能開発の前には要件定義やソリューションの設計などがあり、機能開発の後にはテスト、デプロイメント、運用、継続的な機能改善といったフェーズがあります。しかし、これらは業務目的によって異なるため、本記事では機能開発に絞って解説していきます。
ファインチューニングの流れ
ファインチューニングの機能開発までの基本的な流れは以下のように整理できます。(モデルを選定してからデータを収集したり、精度評価をしてから別のモデルを選び直すといった順番の前後も考えられますが、ここでは基本的な形として以下の図としました。)
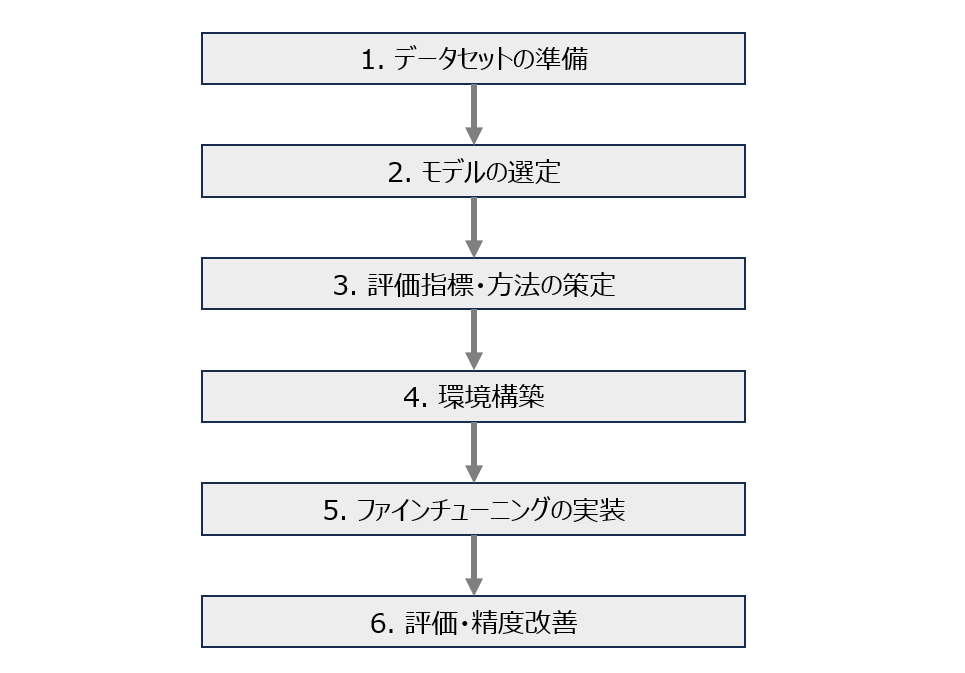
1. データセットの準備
LLMをファインチューニングするためのデータセットを、十分な量かつ適切な形式で準備します。ここでは、データセットを準備する上で考えるべきポイントをいくつか説明します。
既に利用可能なデータがあるかどうか
まず初めに考える点としてはこちらが挙げられます。例えばアンケートデータをポジティブとネガティブに分類するような文章分類モデルにファインチューニングしたい場合は、アンケートデータが存在するので利用可能なデータがすでにあると言えます。そのため、次の作業としては教師ラベルのアノテーションなどがあります。一方で、既存で利用可能なデータがない場合は、利用可能な公開データを探すか、もしくは手動を含む何かしらの方法でデータセットを作成する必要があります。
公開データの利用
ファインチューニング用のデータには、商用利用が可能なオープンなデータが存在するため、これらを利用することができます。ただし、研究目的に限定されるものも多いため、このようなデータを利用する際には必ずライセンスを確認する必要があります。中には各所から無許可にデータをまとめたようなデータセットもあるため、データの収集元まで確認することが望ましいと言えるでしょう。また、日本語のデータセットについては、元々英語のデータセットだったものを翻訳したものがあるため、不自然な日本語になっていないかといった点も確認しておくことが望ましいです。
データセット作成・アノテーション付与
ファインチューニングは基本的には教師あり学習であるため、教師ありのデータセットを準備する必要があります。利用可能な公開データがなく、かつデータセットの作成を自社で行うのが難しい場合は、データセット作成作業そのものを外注するか、もしくはアノテーション作業を外注するといった選択肢があります。他にも高精度なLLMを使って半自動的にデータを作成するという手段もあります。ただし、人手でデータセット作成を行う場合は、作業者によってブレや間違いがないような設計や指示が必要で、LLMで半自動的にデータセットを作成する場合は、それが法律や利用規約に違反していないかどうかの確認が必要です。
2. モデルの選定
プロジェクトの目的に合ったLLMの選定を行います。ここでは、モデルを選定する際に考えるべきポイントをいくつか説明します。
そもそもLLMを使う必要があるか
文章分類などの比較的簡単なタスクであれば、TF-IDFによるベクトル化とLightGBMの組み合わせなどである程度の精度が出せることがあります。多くの計算リソースを要するLLMが本当に必要かどうかは初めに検討しておくのがよいでしょう。
オープンモデルかクローズドモデルか
LLMを使う場合に大きな選択軸となるのが、オープンなモデルを使うかクローズドなモデルを使うかです。オープンなモデルとはLlama 2やMistralのようにパラメータの情報が公開されているモデルを指し、クローズドなモデルとはOpenAIのGPTモデルやGoogleのGeminiのように、APIを利用するモデルを指します。この違いは以下のような点に影響します。
精度と計算リソース
最近ではオープンモデルがGPT-3.5と同等の性能であることが発表されることも増えてきましたが、一部のタスクについてのみであったりと、総合的な性能としてはまだ劣っていると判断できます。また、高性能なオープンモデルを動かすには多くの計算リソースが必要であるため、環境準備という面で工数が必要となります。
費用
クローズドモデルをAPIで利用する場合、基本的にはトークン数に応じてモデルの利用料が発生します。一方でオープンモデルを使う場合は、GPUを利用するためのクラウド費用などがかかります。いずれにしても、どの程度の費用がかかりそうかを事前に見積もっておくことが必要です。
利用環境とセキュリティ
クローズドモデルをAPIで利用する場合は、入力したデータが学習に使われるかどうかといった点を確認し、必要に応じてオプトアウト申請をしておくことが望ましいです。また、クローズドモデルでもオープンモデルでも、セキュリティ要件の則った環境構築が必要です。
カスタマイズ性
オープンモデルはソースコードが公開されているため、クローズドモデルよりもカスタマイズ性が高いと言えます。しかし、現状では総合的な性能はGPT-4のようなクローズドモデルの方が高いと言えるため、どちらを選ぶかは他の検討事項を含めて総合的に判断していく必要があります。
必要な言語に対応しているかどうか
LLMによって事前学習された言語が異なるため、想定したユースケースにあった言語を利用できるモデルを選ぶ必要があります。クローズドモデルでは事前学習されたテキストが不明なことがありますが、オープンモデルではどのような言語で学習されているかが公開されていることが多いです。例えば日本語のテキストを扱えるモデルを探している場合、クローズドモデルは実際に触ってみて日本語を処理できるかどうかを確認し、オープンモデルは事前学習されたテキストを確認して日本語が多く学習されているかどうかを確認するのがよいでしょう。
処理できるテキストの長さはどのくらいか
LLMによって一度に処理できるトークン数は異なります。例えばBERTでは512トークン、Llama 2では4,096トークンが上限となっています。短文を処理するようなモデルでは上限512トークン程度のモデルで事足りますが、文章要約のように大きなトークン数を一度に扱いたい場合は、さらに長いトークン数を処理できるモデルを選んだ方がよいと言えます。テキストを分割したり切り詰めるといった前処理を行えば十分な精度が出るという場合もあるため、必ずしも長いトークンを処理できるモデルがよいとは言えませんが、モデル選択の基準の一つとして上限トークン数という観点を持っておくことが望ましいでしょう。
ライセンス
データセットと同じく、そのモデルが商用利用可能どうかを必ず確認します。Llama 2のように条件付きで商用利用が可能なモデルもあるため、ライセンスや利用規約を注意深く確認する必要があります。
リーダーボード
モデルを選ぶ基準としては、公開されているモデル評価を参考にするという方法もあります。日本語タスクにおいては、LLMの性能評価をまとめたリーダーボードとしてWeights & Biases Japanが運営するNejumi LLMリーダーボード Neoがあります。こちらから自然言語推論や質疑応答などタスクごとの日本語性能を比較することができます。このようなリーダーボードを確認して、業務目的に近いタスクの性能が高いモデルを選択するのもよいでしょう。
他にはChatbot Arenaという、匿名でランダムに選ばれたモデルによる回答を人間がジャッジして、その評価を競うプロジェクトがあります。Hugging Faceにリーダーボードとして公開されているため、ここから汎用的なタスクにおける人間の評価が高いモデルを探すことができます。
3. 評価指標・方法の策定
実装の前に評価指標を決めます。上述したようにLLMには様々なタスクがあり、評価指標もタスクによって異なります。評価指標の設計はファンチューニングにおいて重要な点であるため、ここでは最近の研究や課題について触れておきます。
LLM評価の課題
上述したように、文章分類や固有表現認識などは、従来の分類タスクの指標である適合率や再現率を評価指標として使うことができます。一方で機械翻訳や文章要約においては、BLEUのようにリファレンス(答えとして用意したテキスト)と一致する語数を評価する場合、文法構造や語順は無視されており、文章に対する正確な評価ができているとは言えません。しかし、本来であれば機械翻訳であれば文法的な正しさ、対話応答であれば質問と回答の一貫性、要約であればもとの文章との関連性などが評価するべき観点になると考えられます。そこで最近では、文脈や意味を捉えた評価をするために、これらのタスクの評価にLLMを活用する方法も提案されており、人間による評価の工数を削減するための自動評価手法が研究されています。
LLMによるLLMの評価
LLMによる自然言語生成の評価について調査したLeveraging Large Language Models for NLG Evaluation: A Survey (Li et al., 2024)では、先に挙げたように各タスクの具体的な性質によって対象となる評価の側面やシナリオが決定されると述べられています。また、リファレンスがあるかどうかも評価において考慮するべき観点であり、リファレンスがある場合はその文章との類似度などが評価指標となり、リファレンスがない場合は文脈の一貫性などが評価の対象になると述べられています。
本論文では、LLMを活用した評価は (a) 生成ベースの手法 と (b) マッチングベースの手法があることが紹介されており、マッチングベースが限定的な範囲での評価にとどまることや、人間による評価との相関が低い課題があるとして、生成ベースの手法に焦点を当てています。
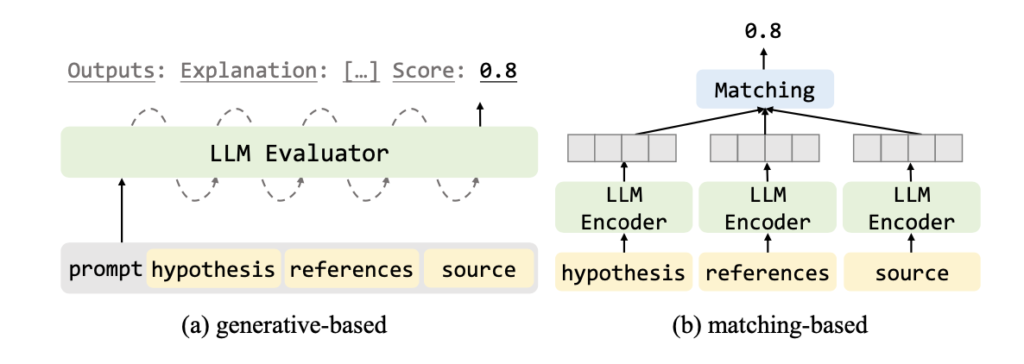
LLMを利用した評価の具体的な方法として、以下の方法が挙げられています。(一部抜粋)
- Score-based
生成されたテキストに対して、0〜100のような連続的なスコアで評価する方法。 - Likert-style
生成されたテキストに対して、「0: 合致していない, 1: どちらとも言えない, 2: 合致している」のように多段階尺度で評価を行う方法。 - Pairwise
2つの生成されたテキストのペアを比較し、どちらがより優れているかを評価する方法。 - Ensemble
異なるモデルやプロンプトの評価用LLMを複数用意し、それぞれ異なる観点から評価を行い、その結果を結合して最終的な評価を決める方法。
このように、LLMのタスクにはシステム的に評価することが難しいものがあり、その場合は人手による評価やLLMを活用した評価が選択肢として挙げられます。いずれにしても人間やLLMのバイアスがかかるといった課題があるため、複数人や複数モデルの評価などで対処することが望ましいと考えられます。
4. 環境構築
こちらは業務で利用する環境や実際に利用するモデルによって大きく異なるため、本記事では割愛します。
5. ファインチューニングの実装
ここまでの準備が完了したら、いよいよファインチューニングを実装します。
実装方法
クローズドモデルであればそのモデルのAPI リファレンス等に従って容易に実装することができます。一方でオープンモデルであれば、HuggingFaceのtransformersライブラリはLLMを扱うための様々なクラスが提供されているため、これを利用することで比較的容易に実装することができます。(具体的な実装コードはここでは割愛しますが、後述する実装例ではOpenAI APIを用いたファインチューニングの実装例を紹介します。)
効率的なファインチューニング手法
ファインチューニングはモデルのパラメータを更新するため、大規模なモデルであるほど計算コストが大きくなります。そこで、現在は「PEFT (Parameter-Efficient Fine-tuning)」と呼ばれる、できるだけ精度を落とさずに一部のパラメータだけを更新する効率的なファインチューニング手法を使うことが主流となっています。その中でも精度が高く主流となっているのがLoRA: Low-Rank Adaptation of Large Language Models (Hu et al., 2021)という論文で提案された「LoRA」という手法です。
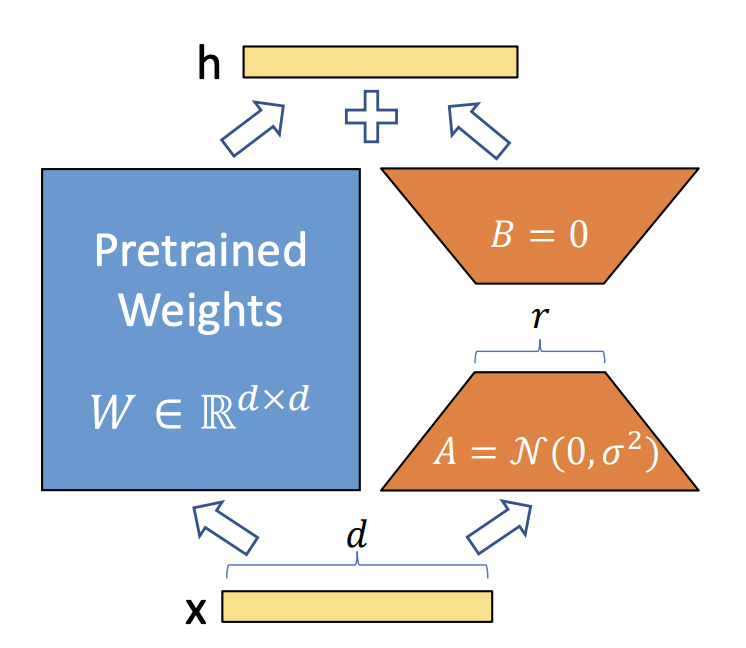
LoRAは低ランク行列分解を用いてチューニングするパラメータ数を削減する手法であり、更新後の出力をhとして、以下の式で表すことができます。
\[h = W’x = Wx + \Delta{W}x = Wx + BAx\]
LoRAではファインチューニング前後のパラメータの重みの差分行列\(\Delta{W}\)とし、これを2〜64の任意のランク\(r\)を用いた行列\(B \in R^{d\times{r}}\)と\(A \in R^{r\times{d}}\)として分解します。もともとパラメータ数が\(d^2\)であった差分行列を\(BA\)と低ランクに分解することで、更新するパラメータ数を\(2dr\)に減らしています。 このように一部のパラメータのみを更新対象にすることで、計算リソースを削減しながら精度を保つことができます。
LoRAの発展的な手法
– QLoRA: Efficient Finetuning of Quantized LLMs (Dettmers et al., 2023)
LoRAに量子化技術を適用し、精度を保ちつつメモリ使用量を削減する方法。
– LoRA+: Efficient Low Rank Adaptation of Large Models (Hayou et al., 2024)
行列A, Bに対して異なる学習率を用いることでLoRAの性能を改善する手法。
– DoRA: Weight-Decomposed Low-Rank Adaptation (Liu et al., 2024)
重み行列を重みmと方向Vに分解し、方向の更新にLoRAを適用ことで学習能力と訓練の安定性を向上する手法。
6. 評価・精度改善
ファインチューニングを終えたらモデルの精度を評価します。あらかじめ決めていた評価指標と方法に従って精度を検証することが重要です。どのように評価を行うかはタスクによって異なりますが、精度が思わしくなかった場合に改善する取り組みとしては、以下のようなことが考えられます。
原因を分析する
評価が低い場合は実際の生成テキストを確認し、「何ができており、何ができていないのか」を明らかにします。一般的な機械学習でもやることは同じですが、現在のモデルのどこに問題があるのかを明らかにする必要があります。ここで立てられた仮説をもとに、以下の改善の取り組みを試してみましょう。
改善する
データの追加
まず考えられるのが学習データの不足です。単純にファインチューニングに使用するデータの量が不足しており、求めている精度まで学習できていないことが考えられます。ファインチューニングに必要なデータ量はタスクやモデルによっても異なるため、どのくらい必要かというのは断言できかねますが、データ不足が考えられる場合は過去の検証結果や同類のタスクの事例を参考にしてみるのがよいでしょう。
データの品質を見直す
データの量が十分である場合、データの品質に問題があることが考えられます。例えばアノテーションの誤りや言葉の誤りなどラベルの不均衡などが影響している可能性があるため確認が必要です。また、目的のタスクに合ったデータが含まれているかどうかの確認も必要です。例えばInstruction Tuningをした際に翻訳の精度が低く、データセットを見ると翻訳用のデータが含まれていなかったといった事象が考えられます。このように訓練に使用するデータが目的に対して適切な品質であるかを確かめるのがよいでしょう。
PEFTの手法を見直す
先に挙げたLoRA以外以外にも様々なチューニング方法があります。また、LoRAの発展的な手法が提案されているため、これらの手法を見直すことで精度が向上する可能性があります。ただし、APIを利用するクローズなモデルでは自由な調整をすることができない場合が多いため注意が必要です。
ハイパーパラメータを見直す
バッチサイズ、学習率、エポック数、LoRAのランクなど、ファインチューニングの学習設定を見直すことで精度が改善される可能性があります。過去の検証結果や他の研究事例などを参考にハイパーパラメータを調整するのがよいでしょう。
モデルを見直す
データの量も品質も十分であり、ハイパーパラメータの調整でもうまくいかない場合、モデルとしての限界が考えられます。モデル選定の基準をもとに、より適切なモデルがないかを再度確認するのがよいでしょう。
ファインチューニングの実装例
最後に、簡単なファインチューニングの実装例を見ていきます。今回はOpenAIのgpt-3.5-turbo-0125をファインチューニングして、特定の出力形式に調整することを試みました。
ファインチューニングの設計
実現したいこと
今回は、子どもがよく言う「なんで〇〇なの?」という疑問に対して、わかりやすく簡潔に回答するモデルを作ることを目指しました。そのままの出力では丁寧語で比較的長いテキストを生成しますが、これを子ども向けの言葉遣いで、かつ短く簡潔に回答するようにファインチューニングをしていきます。
ファインチューニングを使う理由
今回の目的は、新しいドメイン知識を獲得するとこでも最新の情報を外部から取得することでもなく、すでに学習されている言語知識を用いた上で出力形式を調整することであるため、継続事前学習やRAGではなくファインチューニングが選択肢となります。
データセット
手元に既存のデータセットはなく、調査したところ活用できそうな公開データもなかったため、手動でデータセットを作成しました。入力を「なんで」から始まる疑問文とし、出力を「〜だよ。」という子ども向けの言葉遣いを持つ簡潔な一文としています。

学習に70件、検証に30件、テストに30件として、計130件のデータセットを用意しました。
モデル
今回は、OpenAIのgpt-3.5-turbo-125を使用しました。理由は3つあります。
- 手動で作成できるデータ量に限界があり、少量の訓練データでも精度高く学習できる大規模なモデルが望ましいと考えたため。
- 高い性能を持つオープンモデル(約70Bの大きさ)はモデルサイズが大きく、ファインチューニングできるだけの計算リソースを手元に持ち合わせていなかったため。
- 対話型のモデルを想定しており、特定の質問文以外にも対話のやりとりができるように、元々ある程度汎用的な性能が備わっていることが望ましいと考えたため。
費用の見積もり
gpt-3.5-turbo-0125のファインチューニングは、トークン数に応じて費用がかかります。チューニング後のモデルの利用も同様にトークン数に応じた費用がかかりますが、ここでは一旦学習の費用を見積もります。
OpenAIのPricingページを見ると、Fine-tuningの項目に以下のように料金が記載されています。(執筆日時点)

今回は学習および検証データを計100件用いて、トークン数と費用はそれぞれ以下の通りでした。
10,719トークン * ($8 / 1,000,000トークン) ≒ $0.086
また、ファインチューニング後のモデルの利用は通常より割高になります。以下は通常のgpt-3.5-turbo-0125の費用です。

これを見ると、ファインチューニング後のモデルは通常モデルよりも、入力は6倍、出力は4倍の費用であることがわかります。実用上はこのあたりの費用も考慮して見積もりをしておく必要あるでしょう。
トークン数の概算方法
OpenAIのtiktokenライブラリを使用することで、簡単にトークン数の計算ができます。以下はサンプルコードです。JSON形式用になっているため、使用するデータ形式に合わせてください。
import tiktoken
# エンコーダ
encoder = tiktoken.encoding_for_model("gpt-3.5-turbo-1106")
# トークン数を計算する関数
def calculate_total_tokens(encoder, file_path):
total_tokens = 0
with open(file_path, 'r', encoding='utf-8') as jsonl_file:
for line in jsonl_file:
entry = json.loads(line)
messages = entry['messages']
for message in messages:
token_num = len(encoder.encode(message['content']))
total_tokens += token_num
return total_tokens
# 学習データセットのトークン数を計算
train_tokens = calculate_total_tokens(encoder, 'data/train_dataset.jsonl')
print(f"学習データのトークン数: {train_tokens}")
# 検証データセットのトークン数を計算
validation_tokens = calculate_total_tokens(encoder, 'data/validation_dataset.jsonl')
print(f"検証データのトークン数: {validation_tokens}")評価指標・方法
今回は、以下の観点に基づいて、当てはまるかどうかの二値のスコアの合計を評価指標として使うこととしました。評価方法は人間による確認としました。
- 文脈の整合性:質問に対する応答が文脈として適切であるかどうか。
- 正確さ:回答の情報が明らかに間違ったものではないか。
- 言葉遣い:「よ」や「だよ」で終わるような子ども向けのものになっているかどうか。
- 簡潔さ:回答が簡潔な一文で返されているかどうか。
環境構築
今回は検証であり機密性の高いデータも扱っていないため、ローカルのPython環境を使いました。環境変数にOpenAIのAPIキーを設定しています。
ファインチューニングの実装
1. 初期設定
# ライブラリインポート
import pandas as pd
from openai import OpenAI
import json
import tiktoken
import time# モデルを指定
model_name = "gpt-3.5-turbo-0125"2. データ準備(今回はCSVファイルをJSON形式に変換しました。)
# データ読み込み
df = pd.read_csv("data/dataset_for_finetuning.csv")
# データの確認
display(df.head())# データをシャッフルし、学習、検証、テスト用に分割
# シードを固定して再現性を確保
seed = 42
df_shuffled = df.sample(frac=1, random_state=seed).reset_index(drop=True)
# データを分割(学習70件、検証30件、テスト30件)
train_size = 70
val_size = 30
test_size = 30
df_train = df_shuffled[:train_size]
df_val = df_shuffled[train_size:train_size+val_size]
df_test = df_shuffled[train_size+val_size:train_size+val_size+test_size]
# 分割したデータの確認
print("学習データの件数:", len(df_train))
print("検証データの件数:", len(df_val))
print("テストデータの件数:", len(df_test))
# 保存
df_train.to_csv("data/train.csv")
df_val.to_csv("data/validation.csv")
df_test.to_csv("data/test.csv")# データをjsonlに変換する関数
def df_to_jsonl(df, file_name):
with open(f'data/{file_name}.jsonl', 'w', encoding='utf-8') as jsonl_file:
for index, row in df.iterrows():
jsonl_entry = { # jsonlファイルに書き込むデータ
"messages": [
{"role": "system", "content": "あなたは子どもの疑問に簡潔かつわかりやすい言葉で答えるチャットボットです。"}, # システム設定
{"role": "user", "content": row['question']}, # ユーザーの質問
{"role": "assistant", "content": row['answer']} # LLMの回答
]
}
jsonl_file.write(json.dumps(jsonl_entry, ensure_ascii=False) + '\n') # jsonl形式に変換して書き込み# 学習・検証データを変換
df_to_jsonl(df_train, "train_dataset") # 学習データ
df_to_jsonl(df_val, "validation_dataset") # 検証データ
# 確認
!head -n 1 data/train_dataset.jsonl{"messages": [{"role": "system", "content": "あなたは子どもの疑問に簡潔かつわかりやすい言葉で答えるチャットボットです。"}, {"role": "user", "content": "なんで魚は海の中で息ができるの?"}, {"role": "assistant", "content": "魚は「えら」を使って水中にある酸素を取り入れることができるからだよ。"}]}3. ファインチューニング
# インスタンスの生成
client = OpenAI()# データアップロード
train_file = client.files.create(
file=open("data/train_dataset.jsonl", "rb"),
purpose="fine-tune"
)
validation_file = client.files.create(
file=open("data/validation_dataset.jsonl", "rb"),
purpose="fine-tune"
)
train_file_id = train_file.id
validation_file_id = validation_file.id# ファインチューニングの実行
job = client.fine_tuning.jobs.create(
training_file=train_file_id,
validation_file=validation_file_id,
model=model_name
)
job_id = job.id # ファインチューニングのジョブID# ステータスの確認
event = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=100)
status = client.fine_tuning.jobs.retrieve(job_id)
num = 0
for i in reversed(range(len(event.data))):
message = event.data[i].message
message_partition = message.partition(":")[0]
print(f"Event {num}: ", message_partition)
num += 1
print(f"Current Status: ", status.status)
# イベントをキャンセルする
# client.fine_tuning.jobs.cancel(job_id)ハイパーパラメータの設定
OpenAI APIのファインチューニングでは、以下のハイパーパラメータを設定することができます。(参考:https://platform.openai.com/docs/api-reference/fine-tuning/create)
– batch_size:バッチサイズ。大きいほど更新頻度が小さく、分散も小さくなる。
– learning_rate_multiplier:学習率のスケーリング因子。小さくすることで過学習を抑えられる。
– n_epochs:学習エポック数。エポックは学習データを一巡することを意味する。
4. モデルIDの受領
ファインチューニングのジョブが完了すると、OpenAIからメールが送られてきます。そこに記載されているモデルIDがファインチューニング済みモデルなので、IDを引数にしてモデルを呼び出すことができます。
5. テストデータに対する推論
# 設定
client = OpenAI()
model_id = "{ここにモデルIDを入力してください}"
instruct_prompt = "あなたは子どもの疑問に簡潔かつわかりやすい言葉で答えるチャットボットです。"# テストデータの読み込み
df_test = pd.read_csv("data/test.csv")
# 質問のリスト作成
questions = df_test['question'].tolist()
# テストデータの質問に対する回答を取得
correct_answers = df_test['answer'].tolist()
# テストデータの質問に対する回答を取得
generated_answers = []
# テストデータの質問に対する回答を取得
def answer_question(model_name, model_id, instruct_prompt, question):
response = client.chat.completions.create(
model=f"ft:{model_name}:personal::{model_id}",
messages=[
{"role": "system", "content": instruct_prompt},
{"role": "user", "content": f"{question}"}
]
)
return response.choices[0].message.content# テストの実行
for question, correct_answer in zip(questions, correct_answers):
answer = answer_question(model_name, model_id, instruct_prompt, question)
print("指示:", instruct_prompt)
print("質問:", question)
print("回答:", answer)
print("リファレンス:", correct_answer)
generated_answers.append(answer)
time.sleep(2)指示: あなたは子どもの疑問に簡潔かつわかりやすい言葉で答えるチャットボットです。
質問: なんであくびが出るの?
回答: あくびは体の中にたまっている二酸化炭素を外に出すために、深呼吸を沢山しているときに起こるよ。
リファレンス: あくびは、目を覚ましたりリラックスをしたり、脳の状態を変えようとした時に出ると言われているよ。精度評価
評価表のテストデータ30件を使って精度を評価しました。上の結果のように簡潔で子ども向けの言葉遣いとすることができました。全体の評価結果としては以下の通り、テスト30件のうちほとんどが評価指標を満たしており、うまく学習ができていることが確認できました。
- 文脈の整合性:29 / 30件
- 正確さ:28 / 30件
- 言葉遣い:30 / 30件
- 簡潔さ:29件 / 30件
追加検証
念のため、ファインチューニングによって元々の対話性能が損なわれていないかを確認してみました。結果としては以下の通り、「なんで〇〇なの?」という質問文以外も子ども向けに回答を得られることがわかり、対話性能への影響は問題ないことがわかりました。
検証結果(一部):
プロンプト: こんにちは。いろいろ教えてね。
回答: こんにちは。わかる範囲で答えるので、なにか教えたいことがあれば言ってね。
プロンプト: お金ってどうやって稼ぐの?
回答: お金を稼ぐ方法はいろいろあるけど、商品を売ったりサービスを提供して売上を得たりする方法が一般的だよ。
プロンプト: ディズニーランドって知ってる?
回答: ディズニーランドは、アメリカのカリフォルニア州にある世界最初のディズニーパークだよ。乗り物やショーを楽しむことができるよ。
補足
ここではファインチューニングの実装例を紹介するために手法ありきで実装しましたが、今回のようにシンプルなタスクをgpt-3.5-turbo-0125のように高性能なモデルに適用させたい場合は、プロンプトエンジニアリングの工夫だけでも精度高く実現することができます。
ただしこの場合、Few-shotで固定した例示を毎回プロンプトに入れる必要があり、そのトークン数によってはファインチューニングよりも費用が高くなります。(上述したように、通常モデルとファインチューニング済みのモデルでは入力トークン数では6倍の価格差があるため、プロンプトエンジニアリングによる増加分のトークン数が6倍以上になる場合は、ファインチューニング済みのモデルを使う方が費用を抑えられると考えられます。)
またプロンプトエンジニアリングのみの場合、与えた例示に特化しすぎることで、モデルが元々持っている汎化性能がうまく活用できず、質問以外の他の対話などがうまくできない可能性が出てきます。
実用の際には予備調査として、プロンプトエンジニアリング(Few-shotなど)だけで実現が可能かどうか、またその場合の費用はどのくらいかを検証しておくことが望ましいと考えられます。
おわりに
今回の「LLMのファインチューニングを他手法との違いから理解する」では、Part 1でLLMのカスタマイズ手法も概観することでファインチューニングの役割を定義し、Part 2ではファインチューニングの活用イメージや検討ポイントを簡単な実装例を交えて解説しました。
今後さらにLLMのビジネス活用が増えていく場合、LLMを特定の目的に合わせてファインチューニングすることの需要はより高まっていくと考えられます。最近ではGemini 1.51でも使われていると発表のあった「MoE (Mixture of Experts)」のように、特定のタスクに特化したモデルを複数用意して切り替える手法も注目されています。この場合にも特化モデルを学習させるための手法としてファインチューニングが選択肢となるため、この技術を理解しておくことは有用であると言えるでしょう。
今回はInstruction Tuningの実装やアライメントの実装まで触れることができなかったため、次回以降の技術記事にて紹介および検証をしていきたいと思います。
注釈
参考
- Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models
- Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, Quoc V. Le. 2021. Finetuned Language Models Are Zero-Shot Learners
- Oded Ovadia, Menachem Brief, Moshik Mishaeli, Oren Elisha. 2023. Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
- Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Min-Hung Chen. 2024. DoRA: Weight-Decomposed Low-Rank Adaptation
- Soufiane Hayou, Nikhil Ghosh, Bin Yu. 2024. LoRA+: Efficient Low Rank Adaptation of Large Models
- Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer. 2023. QLoRA: Efficient Finetuning of Quantized LLMs
- Zhen Li, Xiaohan Xu, Tao Shen, Can Xu, Jia-Chen Gu, Chongyang Tao. 2024. Leveraging Large Language Models for NLG Evaluation: A Survey
オウンドメディアも運営しています
- 需要予測とは?今すぐ役立つ分析手法・活用事例を厳選して紹介!
- MMM(マーケティング・ミックス・モデリング)とは? | Data Analytics Magazine (dalab.jp)
- 「0,1判別」の定番手法!ロジスティック回帰分析とは? | Data Analytics Magazine (dalab.jp)
- クラスター分析とは?わかりやすく解説! | Data Analytics Magazine (dalab.jp)
- 決定木分析とは?ビジネス活用や注意点を解説 | Data Analytics Magazine (dalab.jp)
- 数値予測の第1歩!重回帰分析とは? | Data Analytics Magazine (dalab.jp)