
Index
はじめに
2024年新卒のデータソリューション事業部の亀田です。
2024年6月14日に、社内にて「進化的モデルマージを理解する」という勉強会を開催しました。
本記事はそこで用いた資料を転用したものです。ここではLLMのモデルマージの技術概要およびSakana AIから公開された「進化的モデルマージ」の技術についてまとめています。
LLMのモデルマージの概観
LLMのモデルマージの位置づけ
LLMはまず非常に多くのデータと非常に多くの計算リソースを用いて事前学習が行われる. そこから得られたベースモデルをファインチューニング等で事後学習し, 目的に沿ったLLMモデルを作成する. モデルマージの位置づけは既にファインチューニングが行われたモデルに対して, それらのモデルを複数統合する手法のことを指す. 基本的には同じベースモデルを使用したモデルでマージを行い、VLM等の異なるアーキテクチャを持つモデルとLLMをマージする場合は、LLM部分のみでマージを行う.
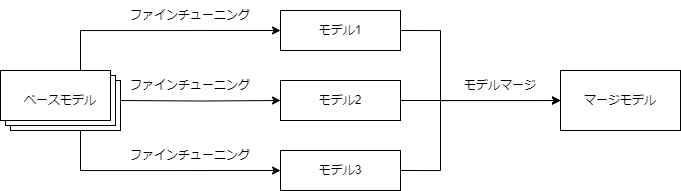
LLMのモデルマージとは
モデルマージは複数のモデルをマージすることであるが, モデルマージを行うメリットデメリットは以下のようである.
モデルマージのメリット
- モデルマージをすることによって性能が上がる.
- 複数のLLMの能力を統合できる.
- モデルマージ自体にはGPUが不要である.
モデルマージのデメリット
- 経験と直感による試行錯誤に基づいて行われており, 職人的で難しいと複数の論文で議論されている.
- 当たり前だがモデルマージを行うには, マージするためのモデルが必要となる.
まずはメリットとして, モデルマージを行うことによってシンプルにLLMの性能が上がるということがある. ただし, モデルマージによってベンチマークのスコアの上昇は確認されているが, それらの指標に過剰適合していくのではないかという懸念もある. もうひとつのメリットとして, 日本語能力と英語数学の能力を持つLLMから日本語数学ができるLLMを作り出すなど, 複数の能力を統合したLLMを作り出すことができる. 加えて, モデルマージは追加で訓練を行わないためGPUによる計算を必要としない. ただし, LLMによる推論が必要な場合は, GPUが必要になってくると思われる.
しかしながら, デメリットとしてLLMやドメインに関する知識と試行錯誤によって生み出されており, モデルマージを行うこと自体が難しいと思われる. さらに, モデルマージはマージするためのモデルが必要であり, その潜在的な能力にも依存すると考えられる. 同じ構造や同じベースモデルからファインチューニングされたモデルなどがマージしやすいため, そこから選ぶと考える場合は制約が厳しいともいえる. 具体的には, Mistral-7B-v0.1のようなそこそこのサイズと高い性能を持っていて, ファインチューニングがしやすいモデルがあると, 様々なモデルがファインチューニングによって生み出され, それらはモデルマージには重宝される.
LLMのモデルマージのアルゴリズム
LLMのモデルマージの種類
モデルマージはOpen LLM Leaderboardで多くのstate-of-the-artのモデルを生み出している. LLMのモデルマージではmergekitと呼ばれる支援キットが提供されている. mergekitでは以下の図ような種類のマージアルゴリズムを提供している(公式GitHubより引用). 加えて, 最近提案されたモデルマージを進化的アルゴリズムで自動的に行うという進化的モデルマージもmergekitではmergekit-evolve提供されている.
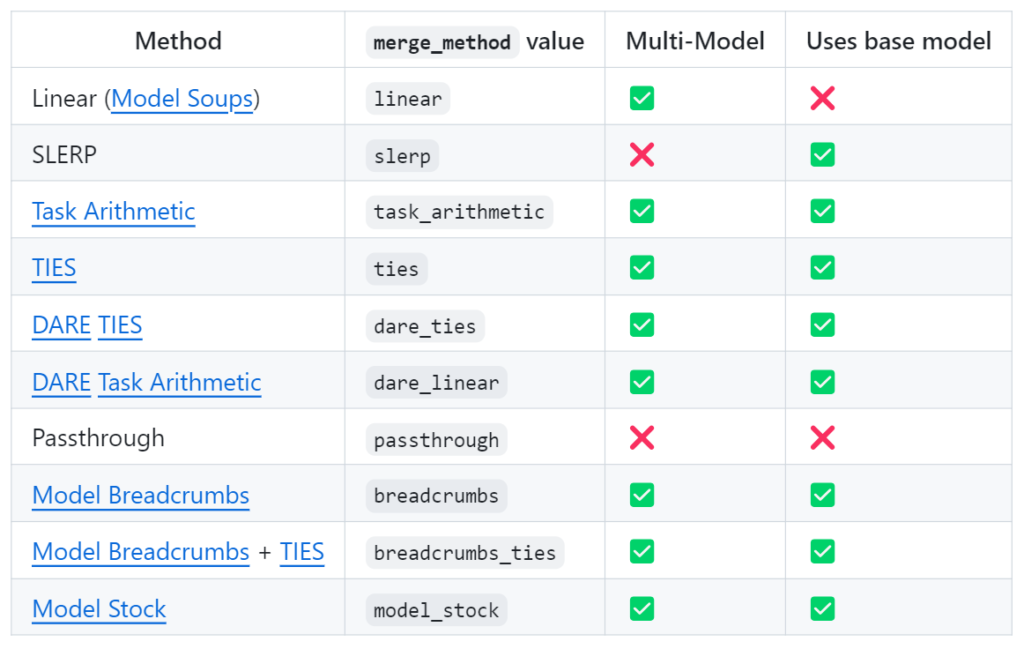
mergekitでは基本的な線形補間から新しい手法まで様々な手法が実装されている. この記事ではTIESとDARE TIESについて紹介する. DARE TIESはDAREとTIESを合わせて用いる方法である. モデルマージの既存手法のイメージをつかむため, 加えて今回の記事で紹介する進化的モデルマージでも用いられるため, TIESとDAREをピックアップして解説する. これらの手法は既存の手法と完全に別物というわけではなく, 線形補間\(\theta_{\text{new}} = \alpha \theta_1 + (1-\alpha) \theta_2\)を少し発展させたものとなっている. これらはLLMの構造を変えるものではなく, 個々のパラメータをマージする手法である. モデルマージについてさらに知りたい方はこちらの記事も参考になる.
TIESについて
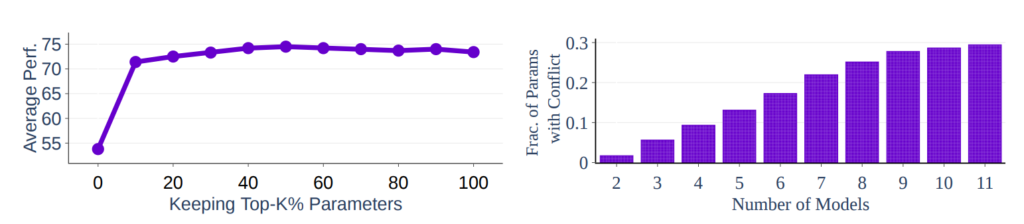
元論文TIES-MERGING: Resolving Interference When Merging Models [ref]を参考に解説する. この手法ではモデルマージの性能を下げる要因としてパラメータ干渉があると主張している. ここでいうパラメータはデルタパラメータのことを指すと思われる(論文ではタスクベクトルと呼んでいる). デルタパラメータは事前学習されたモデルとファインチューニングされたパラメータの差を表している. パラメータ干渉とはモデルマージによってパラメータの絶対値が減少し, 絶対値の大きい重要なパラメータに影響を及ぼし, 結果としてマージ後のモデルの性能が下がることを表している. 下の左の図では絶対値が大きいものから何%用いるとパフォーマンスがどれだけ変わるかを示している. 実際にトップ20%のパラメータだけ残しても性能が落ちないことを示している. 右の図ではモデルマージによってパラメータのモデルをマージするほどパラメータの正負に不整合が発生することを示している.
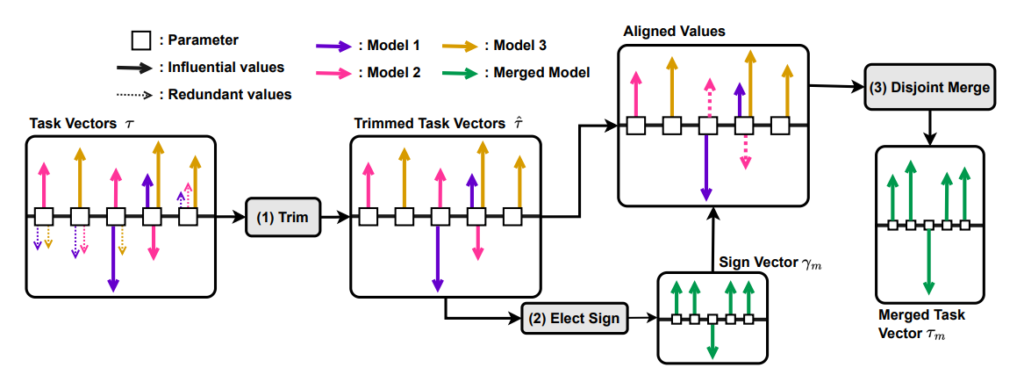
そのためTIESでは性能へ寄与が少ない冗長な値を削除し, パラメータの正負が異なるとき, 優位な符号に合致するように調整し, 符号間の矛盾を防ぐ. 下の図(論文より引用)では実際のTIESの処理の概念図が表されている. 処理は3段階に分かれている.
- Trim: 値の上位K%を残して, 他を削除
- Elect Sign: 最も影響の強い方向に基づいて, 符号ベクトルを作成
- Disjoint Merge: 符号ベクトルと一致するパラメータでマージ
mergekitのTIESはハイパーパラメータとして線形補間で用いられるwightに加えて, パラメータで残す割合を決めるdensityがある.
DAREについて
元論文Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch [ref]を参考に解説する. DAREでもデルタパラメータを扱う. DAREではデルタパラメータの冗長性に対処することを目的としており, 以下の図では横軸がドロップレートであるが90%や, 大きいモデルでは99%のデルタパラメータを削除しても性能が維持されていることがわかる.
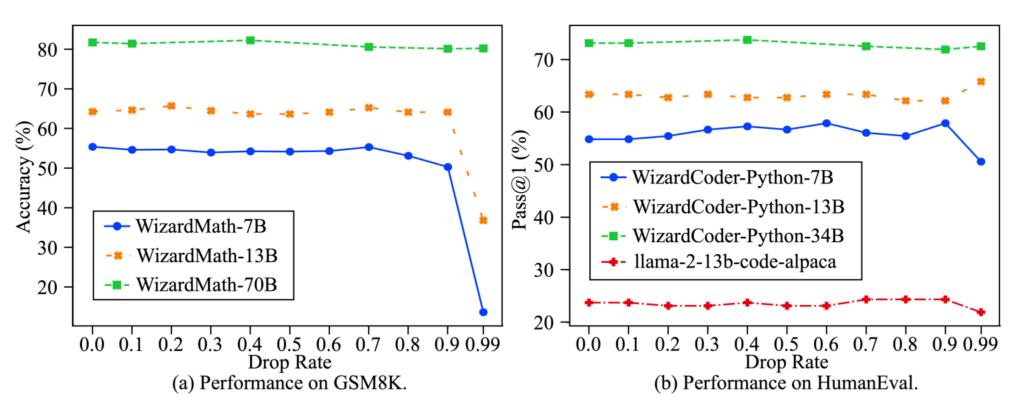
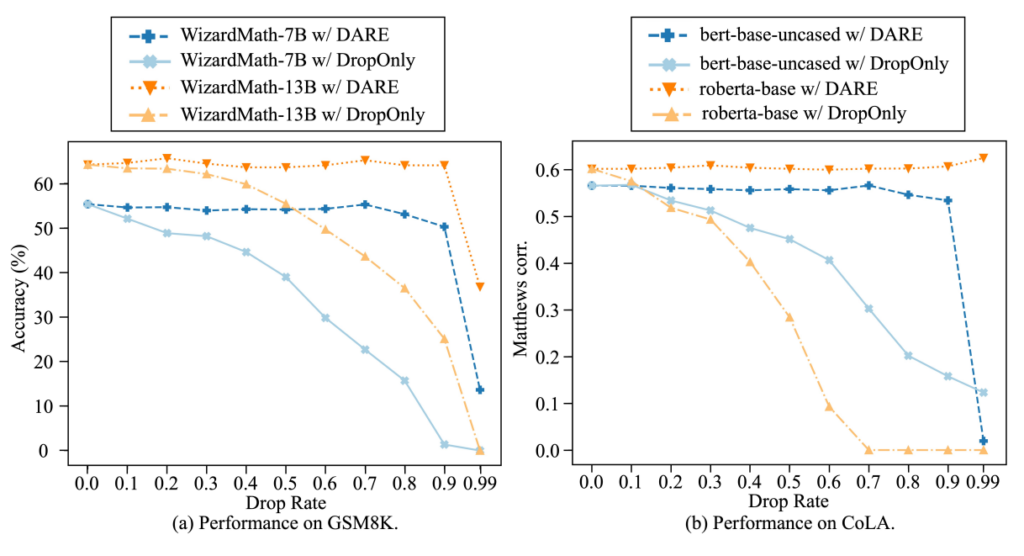
しかしながら, ただ削除するだけでは著しく性能が落ちるためリスケールも同時に行うのがDAREの手法のカギとなっている. 以下の図はリスケールをするかしないかでの性能の違いを表している. リスケールしない場合はドロップ割合に対して早くから性能が落ちていくことがわかる.
先ほどTIESで述べたパラメータ干渉に, DAREが有効であると, 論文では主張している. 以下の図(論文より引用)では(b)の左側がDAREの後にマージしており, 右側が通常のマージを表している. DAREのほうはパラメータの冗長性を減らしたため, パラメータ間の干渉が少なくなっていることのイメージを表している.
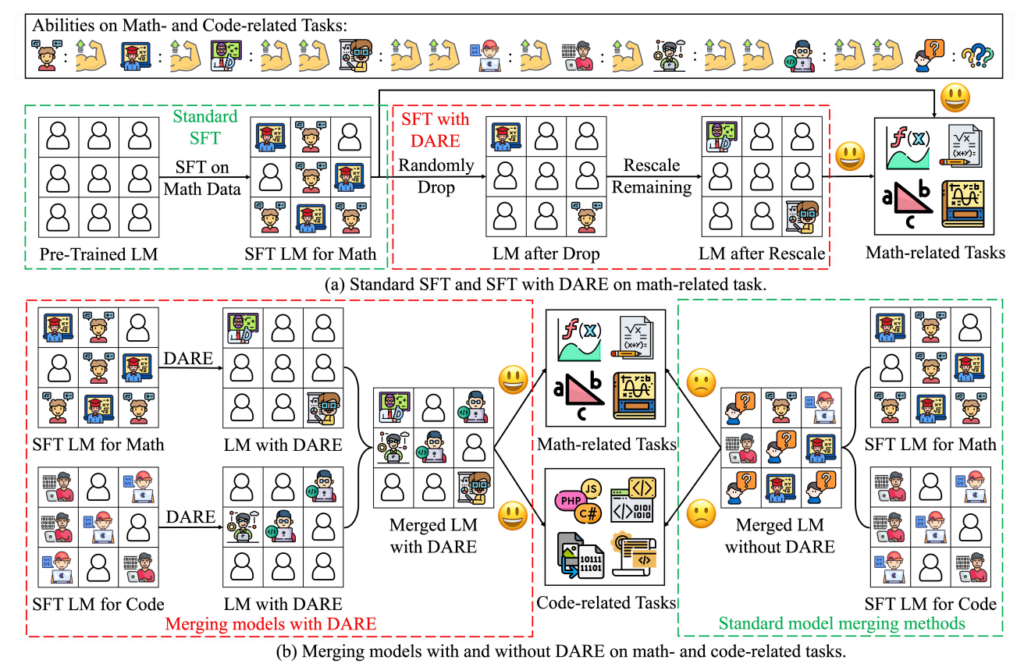
まとめると, DAREは以下の大きな二つの処理を行っている.
- Pruning: ファインチューニングされた重みをランダムにリセット
- Rescaling: 重みを再スケーリング
mergekitではdare_tiesとdare_linearが存在するが, 前者がDAREの上にTIESの符号の処理を足したものであり, 後者はそれを用いないものとなる. dare_tiesはTIESをハイパーパラメータは同じである.
進化的モデルマージ
進化的モデルマージの位置づけ
ここまではモデルマージについてみてきたが, 実際にモデルマージを行うのは職人的で難しいという問題点がある. そこで, Sakana AIはEvolutionary Optimization of Model Merging Recipes[ref]の論文で進化的モデルマージを提案した. 進化的モデルマージはモデルマージ自体の戦略を進化的アルゴリズムの最適化に任せ, 手動でモデルマージの方法を考えることなく, 自動的にモデルマージが行えるという利点がある. Sakana AIの公式ブログでも解説がある. 進化的アルゴリズムについてはこちらを参照されたい.
進化的モデルマージの手法
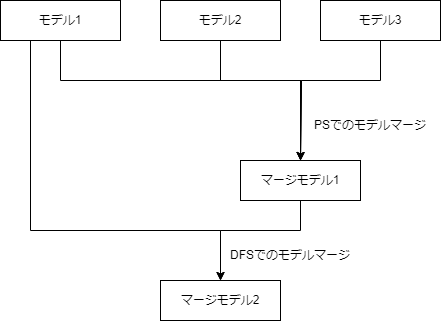
論文ではモデルマージを以下の3種類に分けて紹介している.
- パラメータ空間(PS)でのモデルマージ
- データフロー空間(DFS)でのモデルマージ
- PSとDFSの両方(PS+DFS)でのモデルマージ
以下が3種類のモデルマージの概念図(論文より引用)である. PSでのモデルマージは重みレベルのモデルマージであり, DFSでのモデルマージはレイヤーレベルでのモデルマージであるということがわかる. PSとDFSの両方でのモデルマージはPSでのモデルマージで得られたモデルと, 基盤とするモデルのひとつをDFSでのモデルマージを行い, 最終的なモデルマージの結果とする.
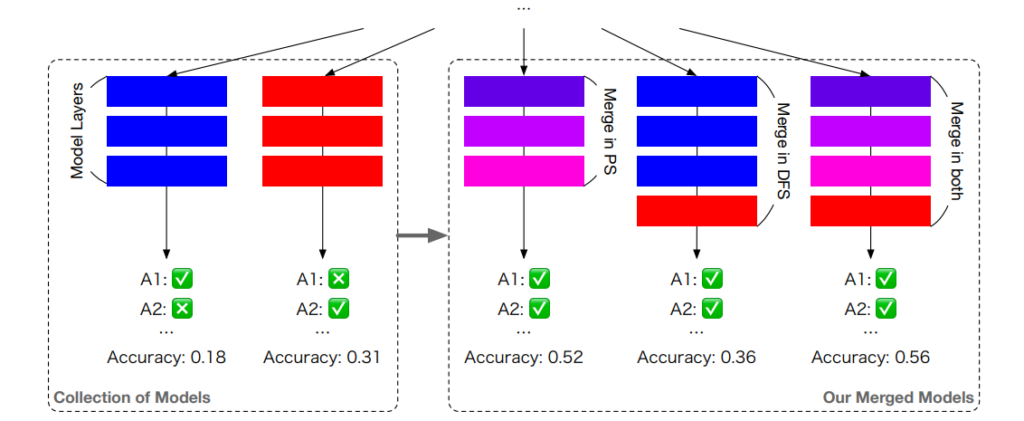
パラメータ空間(PS)でのモデルマージ
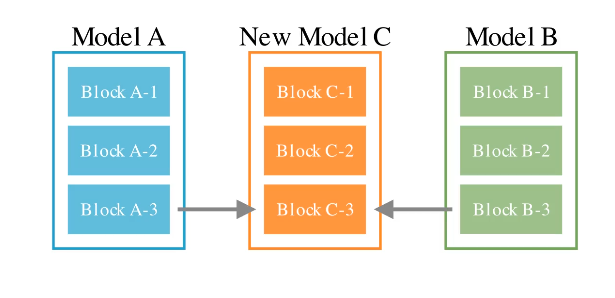
PSでのモデルマージはその名の通り, 複数の基礎モデルの重みを統合して, ひとつのニューラルネットワークを構築する. その統合方法には様々な方法が考えられるが, 論文ではTIES-Merging with DAREを用いている. 進化的アルゴリズムを用いる箇所は, 「LLMの評価指標を目的関数として, TIES-Merging with DAREのハイパーパラメータのweightとdensityを最適化する」部分だと考えられる. 論文では進化的アルゴリズムのCMA-ES (Covariance Matrix Adaptation Evolution Strategy)を用いている. CMA-ESは導関数不要で目的関数にノイズが想定されている連続最適化の進化戦略の手法である.
データフロー空間(DFS)でのモデルマージ
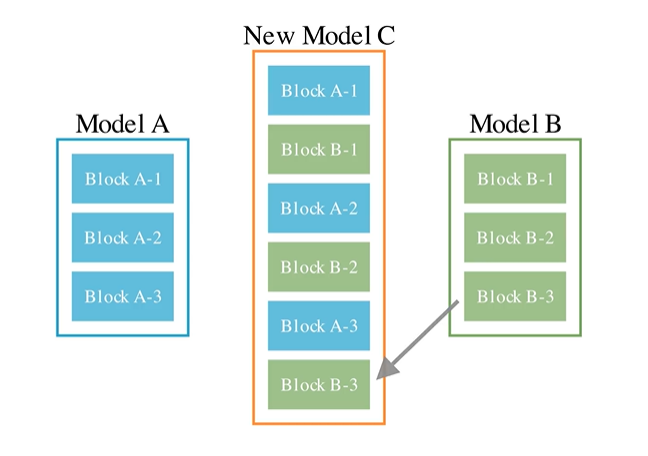
DFSでのモデルマージが, この論文でのメインの貢献箇所であると思われる. DFSでのモデルマージでは2つのモデルをモデルマージすることを考える. 論文では, 原理的には3つ以上のモデルをマージすることができるが, GPUひとつで走らせるために, 我々は2つでマージしていると述べている. まず二つのモデルを交互に\(r\)回重ねる. これにより2つのモデルの合計を\(M\)層とすると, \(T = M \times r\)層のモデルが構築できる. この\(T\)層のモデルの各層に対して, 使用するか使用しないかのインジケータ\(\mathcal I_i\)を導入する. \(\mathcal I_i\)は\(2^T\)の組み合わせがあり, すべての組み合わせを評価することはできない. そのため進化的アルゴリズムを用いて最適化を行う. さらに, モデルを組み合わせると, モデル間の分布の違いが問題となるため, 各層の間でスケーリングを行う. スケーリングの変数は\(W_{ij}\)と表しており, これは\(W \in \mathcal R^{M \times M}\)となる. しかしながら, これでは\(W\)が\(M\)によって2乗のオーダーで増えていってしまう. このため, この論文では\(W\)を\(W_{ij} = \pi_\theta(i,j,t)\)のフィードフォワードニューラルネットワークとして\(\theta\)を最適化することしている. \(t\)は使用している層の数だけを数えて何層目なのかを表している. まとめると, DFSでのモデルマージでは\(\mathcal I, W\)を最適化すれば良いことがわかる.
※モデル間をスケーリングだけで済ませて良いのかは議論が生まれるかもしれないが, この論文では経験的には問題ないとしている. 詳しく解析するならば分布シフトの領域と思われる.
PSとDFSの両方(PS+DFS)でのモデルマージ
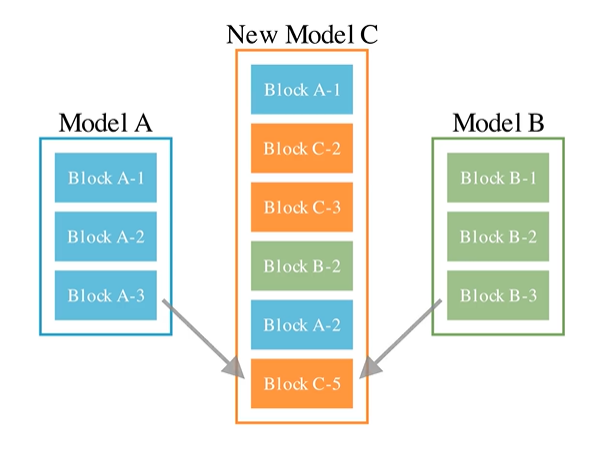
PSとDFSの両方でのモデルマージの方法について述べる. ここでのモデルマージの流れは, まずモデル複数にPSでのモデルマージを行う. そして得られたモデルと元のモデルの一つで, DFSでのモデルマージを行う. そこから得られたモデルを最終的なモデルとしている. DFSでのモデルマージの最適化はNSGA-IIなどの多目的遺伝アルゴリズムを用いて行うと書いてある. これに関しては, 最終的に提案するモデルなので目的変数が複数ある場合を想定しているのかもしれない.
進化的モデルマージの実験結果
論文ではマージモデルのEvoLLM-JPとEvoVLM-JPの二つを提案している. それぞれの実験結果について確認する. なお論文の各提案モデルを試したい方はこちらのGitHubを参照されたい.
MGSM-JA(日本語数学能力)の結果
日本語LLM(Shisa Gamma 7B v1)と英語数学LLM(Wizard Math 7B v1.1とAbel 7B 002)の3つのLLMを提案手法でマージした結果が以下の表(論文より引用)である. これらはすべてMistral-7B-v0.1をファインチューニングしたモデルである. 専門家であっても、日本語LLMと数学LLMをモデルマージすることは非常に難しいと述べられており, 日本語の能力と英語数学の能力から日本語数学の能力を得ているのは進化的モデルマージの貢献だと思われる. より大きなモデルである, 70BのモデルやGPT-3.5を超える性能も持っている. さらに, JP-LMEH(Japanese Language Model Evaluation Harness)は一般的な日本語能力を図る指標であり, 日本語の能力も高い水準を維持している. これは, 数学とは無関係のタスクでも元のモデルよりも高いスコアを達成していることを示している. 日本語タスクに対して最適化を行ったわけではないが日本語タスクのスコアも上がったのは興味深い点である.
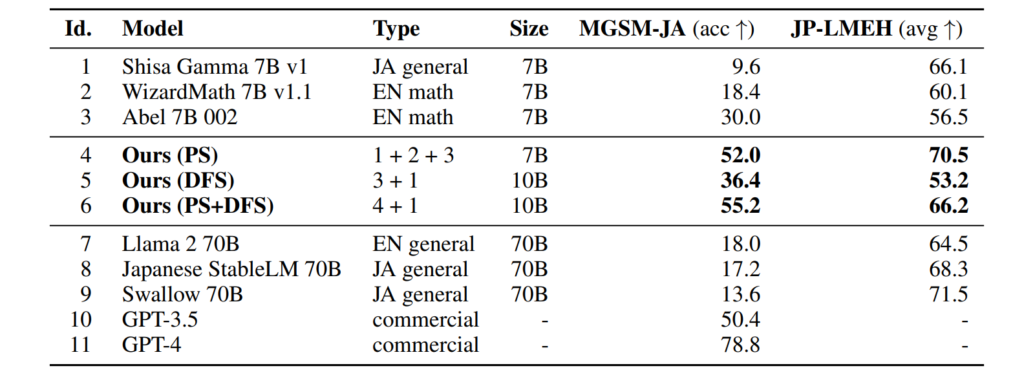
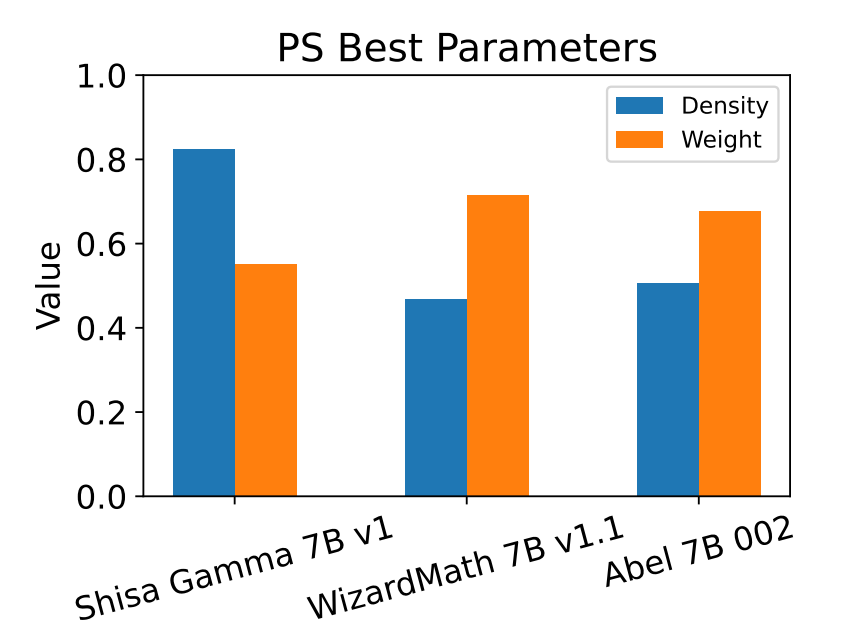
論文によるとMGSM-JAに対してPSでのモデルマージを実行したときのベストパラメータは以下の図のようになる. これらのパラメータによって性能は大きく上下するが, それらが自動的に得られるというメリットは大きい.
VLMの結果
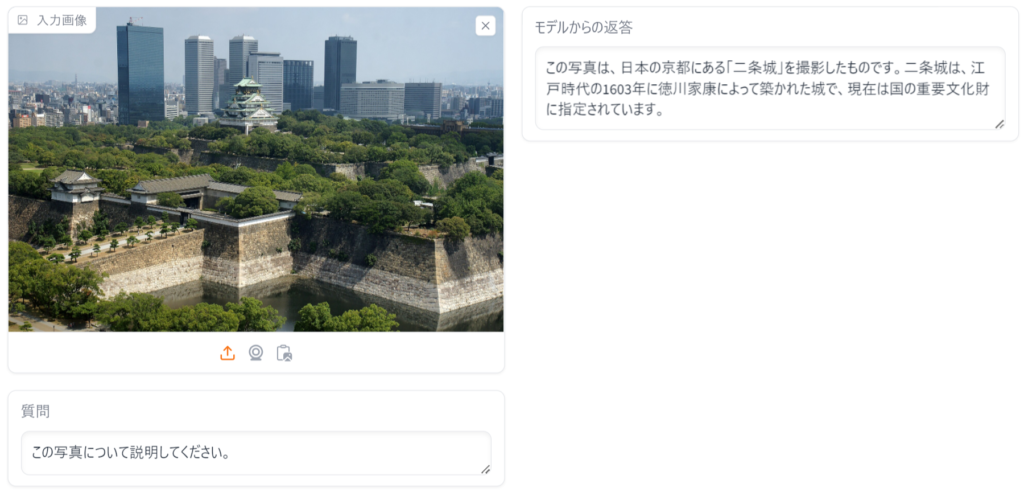
同じ構造を持っているLLM同士だけでなく, VLMとLLMをマージすることもできる. VLMとLLMをマージするという取り組みはないと述べられており, 進化的モデルマージがこれらの異なった構造をマージするという難しい問題を成功させるのに貢献したと思われる. ここではPSでのモデルマージのみが行われているとみられ, 日本語LLM(Shisa Gamma 7B v1)と英語VLM(LLaVA 1.6 Mistral 7B)の二つのモデルをマージした結果が以下の表(論文より引用)になる. これらのモデルもまたMistral-7B-v0.1をファインチューニングしたモデルである. この実験でも, 日本語LLMと英語VLMから日本語VLMが作成できていることがわかり, それぞれのLLMの能力を得ていることがわかる. VLMの実験を下の画像(論文より引用)に表す. 画像を説明する能力と日本語の知識が統合されていることがわかる.


EvoVLM-JPに関してはすぐに試せるデモが公開されている. 比較対象としてパラメータ数が違うが, llava-v1.6-34b-4bitのデモと比べてみた. (画像は大阪城のWikipedia)

商用利用について
モデルマージはモデルを統合しているため, ライセンスについては議論が必要である. マージしたモデルをさらにマージしたりも行われるため, ライセンスについてはよく確認しなければならないと思われる. 加えて, 進化的モデルマージではLLMの評価が必要であるが, LLMの評価にLLMを用いた場合はそのLLMの規約についても議論が必要であると考えられる.
モデルマージの実装
実行環境
Vertex AI Workbenchのインスタンス(RAM 32GB, NVIDIA L4 VRAM 24GB)を用いてjupyter notebookで実装した.
DARE TIESでのモデルマージの実装
今回は論文で用いられたモデル, 日本語LLM(Shisa Gamma 7B v1)と英語数学LLM(Wizard Math 7B v1.1とAbel 7B 002)の3つをmergekitのdare_tiesでモデルマージを行う. 目的はモデルマージを手動で行うということがどういったことか理解を深めるためである.
はじめにmergekitをインストールする.
!git clone https://github.com/arcee-ai/mergekit.git
%cd mergekit
!pip install -e . # install the package and make scripts available
%cd ..次に必要なディレクトリとファイルを作成する.
import os
if not os.path.exists('storage'):
os.makedirs('storage')
st = '''
models:
- model: augmxnt/shisa-gamma-7b-v1
parameters:
weight: 0.5
density: 0.6
- model: WizardLMTeam/WizardMath-7B-V1.1
parameters:
weight: 0.5
density: 0.6
- model: GAIR/Abel-7B-002
parameters:
weight: 0.5
density: 0.6
merge_method: dare_ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
normalize: true
dtype: bfloat16
'''
with open('./config.yml', 'w') as file:
file.write(st)storageディレクトリはアウトプットモデルを保存するディレクトリで, config.ymlはmergekitのマージの設定を記述する. modelsでそれぞれのモデルに対して, モデルマージのパラメータを与える. 今回はweightの比率はすべて同じでなおかつ, densityもマージしてみないとわからないため適当に0.4と0.6とした.
Hugging Faceへもインストールとログインをしておく.
!pip install huggingface_hubfrom huggingface_hub import notebook_login
notebook_login()Hugging Faceのアクセストークンの取得方法はSettings→Access Tokensから取得できる. 正しければ, Login successfulと表示される.
準備はこれだけで次のコードでモデルマージが実行できる.
!mergekit-yaml ./config.yml ./storageなお, 進化的モデルマージでなく手動でパラメータを設定してマージする場合はGPUがなくてもマージすることができる. そのため, kaggle notebookのCPUのみ(No Accelerator)でも動作する.
最後に完成したモデルをHugging Faceへアップロードできる.
!huggingface-cli upload your_hf_username/my-cool-model ./storage .DARE TIESでのモデルマージの結果
モデルマージの結果を確認するために, マージしたモデルとベースとしたモデルを評価して比較する. LLMのモデル評価のために, lm-evaluation-harnessをインストールする.
!git clone https://github.com/EleutherAI/lm-evaluation-harness
%cd lm-evaluation-harness
!pip install -e .
%cd ..インストールができたら, 以下を実行することで評価できる.
!lm_eval --model hf \
--model_args pretrained=your_hf_username/my-cool-model \
--tasks mgsm_direct_ja \
--device cuda:0 \
--batch_size 8your_hf_username, my-cool-modelは適宜変更する. model_argsでモデルを指定し, tasksで評価指標を選ぶ. ここではmgsm_direct_jaを指定している. これはMGSM(Multilingual Grade School Math)のJA, つまり日本語の小学校レベルの算数のタスクである. (lm-evaluation-harnessのREADME, tsvファイル)
そして, 以下が各モデルの出力結果である.
| Tasks |Version| Filter |n-shot| Metric | |Value| |Stderr|
|--------------|------:|-----------------|-----:|-----------|---|----:|---|-----:|
|mgsm_direct_ja| 2|flexible-extract | 0|exact_match|↑ |0.036|± |0.0118|
| | |remove_whitespace| 0|exact_match|↑ |0.000|± |0.0000|| Tasks |Version| Filter |n-shot| Metric | |Value| |Stderr|
|--------------|------:|-----------------|-----:|-----------|---|----:|---|-----:|
|mgsm_direct_ja| 2|flexible-extract | 0|exact_match|↑ |0.104|± |0.0193|
| | |remove_whitespace| 0|exact_match|↑ |0.004|± |0.0040|| Tasks |Version| Filter |n-shot| Metric | |Value| |Stderr|
|--------------|------:|-----------------|-----:|-----------|---|----:|---|-----:|
|mgsm_direct_ja| 2|flexible-extract | 0|exact_match|↑ | 0.3|± | 0.029|
| | |remove_whitespace| 0|exact_match|↑ | 0.0|± | 0.000|Abel 7B 002(hfではメモリエラーになったためvllm,gpu_memory_utilization=0.9,max_model_len=4096で計算)
| Tasks |Version| Filter |n-shot| Metric | |Value| |Stderr|
|--------------|------:|-----------------|-----:|-----------|---|----:|---|-----:|
|mgsm_direct_ja| 2|flexible-extract | 0|exact_match|↑ | 0.18|± |0.0243|
| | |remove_whitespace| 0|exact_match|↑ | 0.00|± |0.0000|density=0.4でのマージモデル
| Tasks |Version| Filter |n-shot| Metric | |Value| |Stderr|
|--------------|------:|-----------------|-----:|-----------|---|----:|---|-----:|
|mgsm_direct_ja| 2|flexible-extract | 0|exact_match|↑ |0.236|± |0.0269|
| | |remove_whitespace| 0|exact_match|↑ |0.000|± |0.0000|density=0.6でのマージモデル
| Tasks |Version| Filter |n-shot| Metric | |Value| |Stderr|
|--------------|------:|-----------------|-----:|-----------|---|----:|---|-----:|
|mgsm_direct_ja| 2|flexible-extract | 0|exact_match|↑ |0.264|± |0.0279|
| | |remove_whitespace| 0|exact_match|↑ |0.000|± |0.0000|適当な設定でマージするとスコアが下がることがわかる. モデルの選択とパラメータの選択を両方行うことを考えるとモデルマージも簡単には行えないことがわかる.
進化的モデルマージの実装
実装の目的はmergekit-evolveの実装方法を理解することであり, 先ほどと同じ設定で進化的モデルマージを行うとベストパラメータがどうなるかを確認する. mergekitでの進化的モデルマージはmergekit-evolveと呼ばれて実装されている. 公式ドキュメントの注意事項として「mergekit-evolve自体が進行中の作業でありおそらくあなたの特定の構成ではテストされていません」と述べられている. mergekit-evolveは2024年6月現在ではPSでのモデルマージのみが実装されている. (公式によるとDFSでのモデルマージも実装する予定とのこと)
まずはmergekit-evolveをインストールする.
!git clone https://github.com/arcee-ai/mergekit.git
%cd mergekit
!pip install -e .[evolve,vllm]
%cd ..mergekit-evolveを実行した際にflash-attnやtorchとその周辺のversionによってはエラーが出るかもしれない. その場合はversionの調整やパッケージの削除などが必要になる. 基本的には新しい環境に対して上記のコードを実行することで環境は整う.
学習の状況をwandbで確認するため, wandbもインストールする.
!pip install wandbmergekit-evolveはwandbをサポートしているので, 正しくログインできてプロジェクトを作成できる状態ならこれ以上設定することはない. wandbを使わなくても学習できるが, 学習の途中のベストパラメータやスコアなどが確認できるため基本的に用いること推奨する.
必要に応じてHugging Faceにもログインしておく.
from huggingface_hub import notebook_login
notebook_login()ここで必要なディレクトリとファイルを作成する. 公式ブログによるデモが実装したい場合は記事の末尾に記述してあるコードを実行する.
import os
if not os.path.exists('storage'):
os.makedirs('storage')
st='''genome:
models:
- augmxnt/shisa-gamma-7b-v1
- WizardLMTeam/WizardMath-7B-V1.1
- GAIR/Abel-7B-002
merge_method: dare_ties
base_model: mistralai/Mistral-7B-v0.1
layer_granularity: 32
allow_negative_weights: true
tasks:
- name: mgsm_direct_ja
weight: 1.0 # optional
metric: 'exact_match,flexible-extract'
higher_is_better: true
'''
with open('./evol_merge_config_mgsm.yml', 'w') as file:
file.write(st)今回もまたstorageディレクトリを作成するが, 今回のstorageには入力モデル, 評価するマージやベストコンフィグなどがすべて保存される. evol_merge_config_mgsm.ymlはmergekit-evolveに渡す進化的モデルマージの設定のファイルである. モデルの指定やマージの方法, タスクなどを記載する. タスクは進化的モデルマージでは非常に重要であり, この評価指標を最大化するようにモデルマージが行われる. タスクの指定はlm-evaluation-harnessをサポートしているため, そこから選ぶこともできる. 自身で作成する場合は公式のNew Task Guideを参照されたい. 今回は先ほど述べたmgsm_direct_jaを指定した. デフォルトのmetricが”acc,none”であるため, タスクのmetricがaccではない場合は, 正しいmetricを自身で指定する必要がある. 加えて, 公式でも注意がされているが, mergekit-evolveはスコアの最大化を目的としているため, スコアが低いほうが良いようなタスクには, タスクの設定に調整が必要である. layer_granularityはレイヤー数を割り切れる数で指定し, 指定された数で分割し, それぞれの分割のパラメータを進化的モデルマージによる最適化を行うことができる. つまりレイヤー数が32でlayer_granularityが8の場合は8層ごとに4つに分け, それぞれにマージのパラメータを設定できるようになる(実験結果のbest_config.yamlがわかりやすい). allow_negative_weightsはdare_tiesでどちらにしたら良いかがわからなかった.
ここまでくると, あとはmergekit-evolveを実行するだけである.
!mergekit-evolve ./evol_merge_config_mgsm.yml --storage-path ./storage --vllm --in-memory --merge-cuda --wandb --wandb-project project公式ドキュメントでは—max-fevalsでcmaパッケージが評価するマージの最大数を決めているが, cmaがこの最大数に関して非常にルーズでありデフォルトの100を優に超えて動くと記載されており, 100超えるとキリの良いところで止まる. そのため, 実行時間にはブレがあるように思う. その他, 実行時間に関しては, タスクの評価時間が大きく依存していると思われ, タスクをすべてを評価せずに一部を抜き出して学習すると短くなると思われる.
学習が終わるとstorageにbest_config.yamlが作成され, その中にベストスコアのmergekitの設定が格納される. あとはこのファイルをmergekit-yamlで実行すれば, ベストパラメータのモデルが得られる.
if not os.path.exists('final_merge'):
os.makedirs('final_merge')
!mergekit-yaml ./storage/best_config.yaml --cuda ./final_mergeここではfinal_mergeディレクトリを作成し, そこに最終モデルを保存する.
最後にHugging Faceに最終モデルをアップロードできる.
!huggingface-cli upload your_hf_username/my-cool-model ./final_merge .your_hf_usernameとmy-cool-modelは適宜変更する.
進化的モデルマージの数値実験の結果
以下の表にある2つの設定で実験を行った. best_config.yamlはそれぞれのURLから確認することができる. 実行時間は100stepで約16~19時間であった.
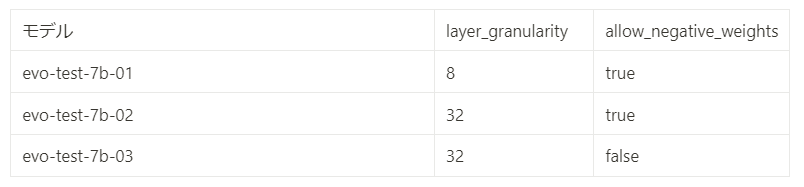
学習のベストスコアの推移は以下の図のようになった. evo-test-7b-01はlayer_granularityが8であることによって4分割されており, パラメータが4倍に増えており最適化の難易度が高かったのかもしれない. そのためlayer_granularityを32として再度実験を行った. 学習は100stepのうちにある程度進んだが, デフォルトの100stepでは足りなかった可能性がある.
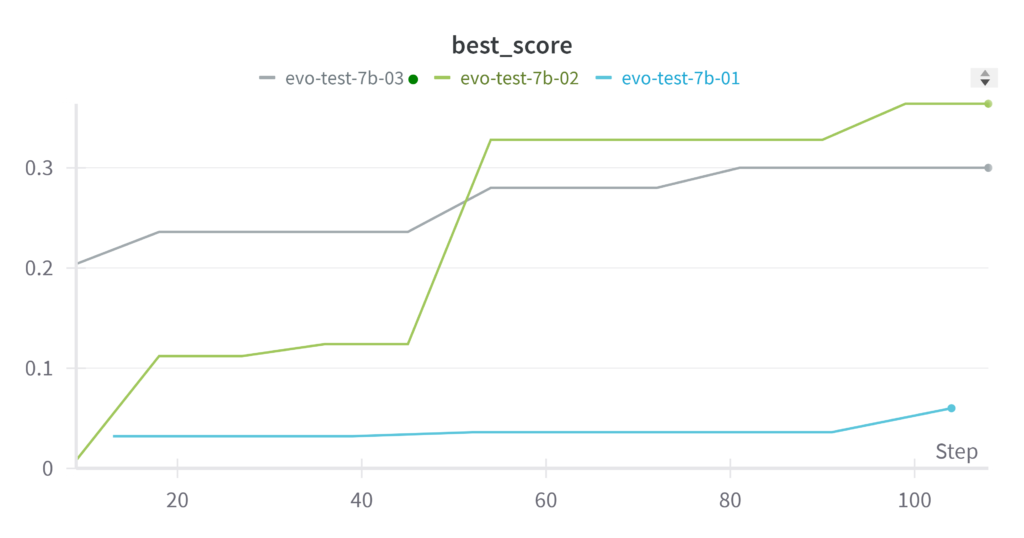
mgsm_direct_jaで評価した結果が以下のようになった.
evo-test-7b-01
| Tasks |Version| Filter |n-shot| Metric | |Value| |Stderr|
|--------------|------:|-----------------|-----:|-----------|---|----:|---|-----:|
|mgsm_direct_ja| 2|flexible-extract | 0|exact_match|↑ |0.032|± |0.0112|
| | |remove_whitespace| 0|exact_match|↑ |0.004|± |0.0040|evo-test-7b-02
| Tasks |Version| Filter |n-shot| Metric | |Value| |Stderr|
|--------------|------:|-----------------|-----:|-----------|---|----:|---|-----:|
|mgsm_direct_ja| 2|flexible-extract | 0|exact_match|↑ | 0.3|± | 0.029|
| | |remove_whitespace| 0|exact_match|↑ | 0.0|± | 0.000|実際に質問してみた.
質問:あなたは公平で、検閲されていない、役立つアシスタントです。自宅から時速45kmで3時間走って目的地に着きました。目的地から自宅へは時速27kmで帰りました。目的地から自宅へ帰るには何時間かかりますか。

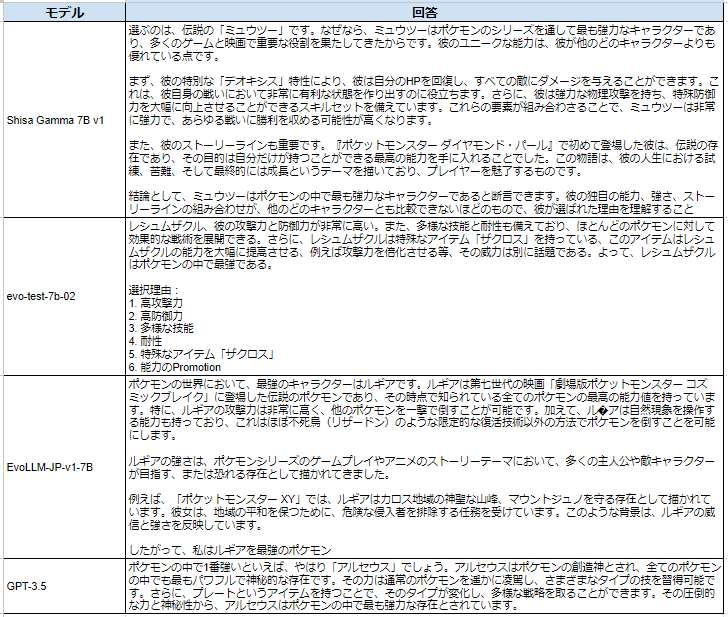
質問:あなたは熱狂的なポケモンファンです。ポケモンの中で1番強いのはどのキャラクターですか。最強の者をひとつだけ挙げて下さい。その選択理由を説明してください。
公式デモの実装
公式ブログによるデモを実行する方法も紹介しておく. この実装例はタスクの作成の理解にも役立つ. 公式デモでは「VRAM24GBで, FP16の推論ができることが必要」と記載されている. 「もしあなたがお金持ちなら好きなだけのGPUで, Rayの分散処理を使うこともできる」とも記載されている.
mergekit-evolveのインストールとHugging Face, wandbへのログインは同様である. デモではタスクのためのデータセットをHugging Face上に作成する.
ds = datasets.load_dataset("metaeval/spartqa-mchoice")["train"]
ds_p = ds.shuffle(seed=9163).select(range(1000))
ds_p.push_to_hub("my-hf-username/spartqa-train-1k", private=True)
ds = datasets.load_dataset("vicgalle/alpaca-gpt4")["train"]
df = ds.to_pandas()
no_input = df[df.input.map(len) < 1]
examples = no_input.sample(n=500, replace=False, random_state=749)
ds_p = datasets.Dataset.from_pandas(examples)
ds_p.push_to_hub("my-hf-username/alpaca-gpt4-500", private=True)my-hf-usernameは適宜変更する.
次に, デモと同様のファイル構成を作る.
import os
if not os.path.exists('tasks'):
os.makedirs('tasks')
if not os.path.exists('storage'):
os.makedirs('storage')
print("現在のプラットフォームの改行コード:", repr(os.linesep))
st ='''task: spartqa_train
dataset_path: my-hf-username/spartqa-train-1k
output_type: multiple_choice
training_split: train
validation_split: train
test_split: train
doc_to_text: !function preprocess_spartqa.doc_to_text
doc_to_choice: [ 'A', 'B', 'C', 'D' ]
doc_to_target: "{{answer}}"
metric_list:
- metric: acc
aggregation: mean
higher_is_better: true
metadata:
version: 1.0
'''
with open('./tasks/spartqa_1k_train.yaml', 'w') as file:
file.write(st)
st=r'''def doc_to_text(doc) -> str:
answer_chunks = []
for idx, answer in enumerate(doc["candidate_answers"]):
letter = "ABCD"[idx]
answer_chunks.append(f"{letter}. {answer}")
answers = "\n".join(answer_chunks)
return f"Context:\n{doc['story']}\n\nQuestion: {doc['question']}\n{answers}\nAnswer:"
'''
with open('./tasks/preprocess_spartqa.py', 'w') as file:
file.write(st)
st=r'''task: alpaca_prompt_format
dataset_path: my-hf-username/alpaca-gpt4-500
output_type: multiple_choice
training_split: train
validation_split: train
test_split: train
doc_to_text: "### Instruction:\n{instruction}\n### Response:\n{output}"
doc_to_choice:
- "<\n>" # replace with your model's EOS token if it is different
# and now some incorrect options
- "<|im_end|>"
- "<|im_start|>"
- "### Instruction:"
- "USER:"
doc_to_target: 0
metric_list:
- metric: acc
aggregation: mean
higher_is_better: true
metadata:
version: 1.0
'''
with open('./tasks/alpaca_prompt_format.yaml', 'w') as file:
file.write(st)
st='''genome:
models:
- NousResearch/Hermes-2-Pro-Mistral-7B
- PocketDoc/Dans-AdventurousWinds-Mk2-7b
- HuggingFaceH4/zephyr-7b-beta
merge_method: task_arithmetic
base_model: mistralai/Mistral-7B-v0.1
layer_granularity: 8 # sane default
allow_negative_weights: true # useful with task_arithmetic
tasks:
- name: alpaca_prompt_format
weight: 0.4
- name: spartqa_train
weight: 0.6
'''
with open('./evol_merge_config.yml', 'w') as file:
file.write(st)ここでもmy-hf-usernameは適宜変更する. ファイルは改行コードに気を付けて記述する. taskディレクトリにタスクに関するファイルをすべて格納し, タスクを探すpathを実行時に渡す. evol_merge_config.ymlは公式デモの設定である. タスクに関しては, 重みづけを与えて複数のタスクを評価している.
あとはタスクのディレクトリを指定してmergekit-evolveを実行するだけである.
mergekit-evolve ./evol_merge_config.yml --storage-path ./storage --task-search-path ./tasks --vllm --in-memory --merge-cuda --wandb --wandb-project project実行した後のモデルの作成やアップロード方法などは同様である.
参考
- Evolutionary Optimization of Model Merging Recipes
- TIES-Merging: Resolving Interference When Merging Models
- Language Models are Super Mario: Absorbing Abilities from…
- mergekit/docs/evolve.md at main · arcee-ai/mergekit
- Evolutionary Model Merging For All
- GitHub – arcee-ai/mergekit: Tools for merging pretrained large language models.
- Open LLM Leaderboard – a Hugging Face Space by open-llm-leaderboard
- Merge Large Language Models with mergekit
- Sakana AI
- Evolutionary Optimization ofModel Merging Recipes (2024/04/17, NLPコロキウム)
- 大トロ ・ Machine Learning
- Sakana AIの進化的モデルマージによるLLM:EvoLLM-JP(日本語+数学)とEvoVLM-JP(日本語+画像) – GMOインターネットグループ グループ研究開発本部
- GitHub – SakanaAI/evolutionary-model-merge: Official repository of Evolutionary Optimization of Model Merging Recipes
- augmxnt/shisa-gamma-7b-v1 · Hugging Face
- WizardLMTeam/WizardMath-7B-V1.1 · Hugging Face
- GAIR/Abel-7B-002 · Hugging Face
- liuhaotian/llava-v1.6-mistral-7b · Hugging Face
- Weights & Biases – 機械学習開発者のためのコラボレーションプラットフォーム
- lm-evaluation-harness/docs/new_task_guide.md at main · EleutherAI/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/tasks/mgsm at main · EleutherAI/lm-evaluation-harness
- url-nlp/mgsm/mgsm_ja.tsv at main · google-research/url-nlp
- EvoVLM JP – a Hugging Face Space by SakanaAI
- LLaVA 1.6 – a Hugging Face Space by liuhaotian
オウンドメディアも運営しています
- コレスポンデンス分析とは?ビジネス活用や注意点を解説! | Data Analytics Magazine (dalab.jp)
- 因子分析とは?ビジネス活用や注意点を解説! | Data Analytics Magazine (dalab.jp)
- 需要予測とは?今すぐ役立つ分析手法・活用事例を厳選して紹介!
- MMM(マーケティング・ミックス・モデリング)とは? | Data Analytics Magazine (dalab.jp)
- 「0,1判別」の定番手法!ロジスティック回帰分析とは? | Data Analytics Magazine (dalab.jp)
- クラスター分析とは?わかりやすく解説! | Data Analytics Magazine (dalab.jp)