
Index
はじめに
データソリューション事業部の力岡です。
近年、大規模言語モデル(LLM)を利用する機会は増加しており、GPTやClaudeといったクローズドなモデルだけでなく、自身の環境でオープンソースのLLMを活用したいと考える人が徐々に増えてきています。しかし、その場合に課題となるのは、推論速度の遅さや計算資源の制約です。
本記事では、LLMの推論速度を大幅に向上させることができるライブラリ「vLLM」について紹介します。さらに、vLLMの主要技術であるPagedAttentionやバッチ処理手法についても簡単に解説していきたいと思います。推論速度や計算資源に課題を感じている方は、ぜひ本記事を参考にしてください。
vLLMとは
vLLMは、LLMの推論を高速化するためのオープンソースライブラリで、Pythonで利用することができます。通常、LLMの推論は多くの計算資源を必要とし、その結果、応答時間が長くなることが課題となります。vLLMは、この課題を解決するために設計され、効率的なメモリ管理と高速な計算を実現しています。
公式ドキュメント : vLLM Docs
vLLMの特徴
- 高速な推論速度
- vLLMは、推論速度を劇的に向上させるための最適化が施されています。これにより、リアルタイムアプリケーションやインタラクティブな対話システムにおいても高いパフォーマンスを発揮します。
- 効率的なメモリ管理
- vLLMは、メモリ使用量を最小限に抑えるための技術を組み込んでおり、限られたハードウェアリソースでもLLMを実行可能にします。
- 互換性の高さ
- vLLMは、既存の多くのLLMフレームワークやモデルと互換性があります。そのため、既存のワークフローに簡単に統合でき、導入のハードルが低いです。
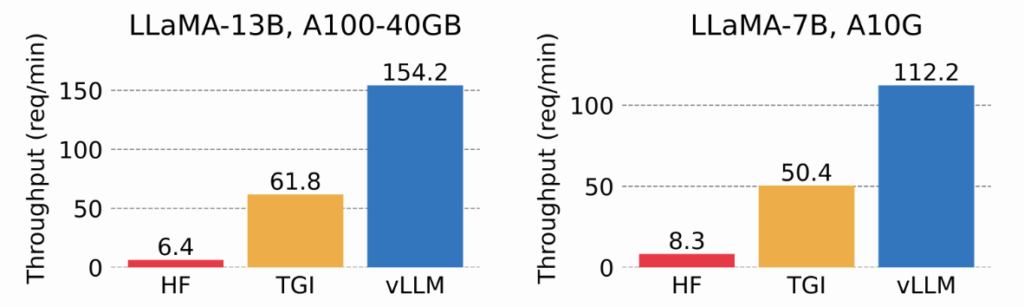
図1では、人気のあるHugging FaceのTransformers(HF)と、Hugging Face Text Generation Inference(TGI)、vLLMのスループットを比較しています。図から、vLLMは最大でHFの14~24倍、TGIの2.2~2.5倍のスループットを持つということがわかります。
vLLMの仕組み
vLLMは、PagedAttentionという革新的な手法により、効率的なメモリ管理と高スループットを実現しています。以下で、従来の推論プロセスにおける課題から始まり、vLLMで使われている技術であるPagedAttentionとContinuous Batchingについて、順を追って説明していきます。
従来の推論プロセスにおける課題
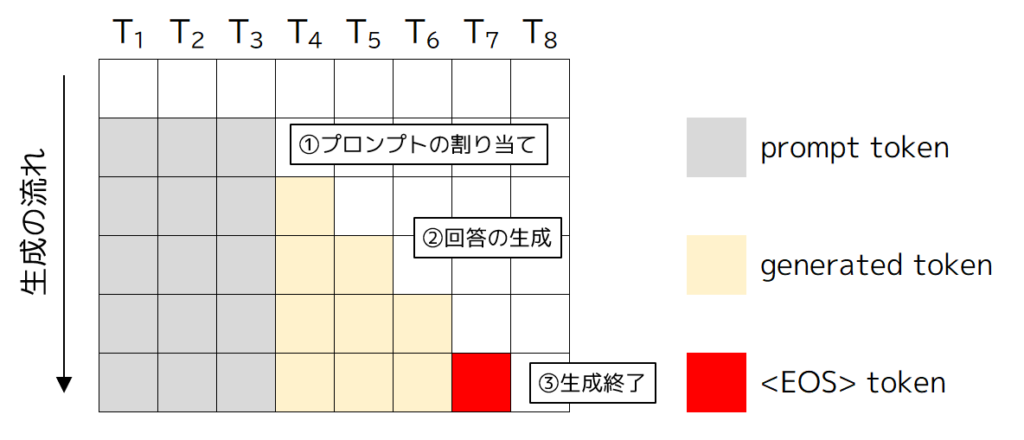
LLMの推論プロセスでは、図2のようにユーザーが入力したプロンプトを基に次のトークンを生成し、生成されたトークンをプロンプトに追加して再度モデルに入力するという操作を繰り返します。このサイクルは、シーケンスが最大長(例:2048トークン)に達するか、特定の停止トークン(例:<EOS>)が生成されるまで続けられます。
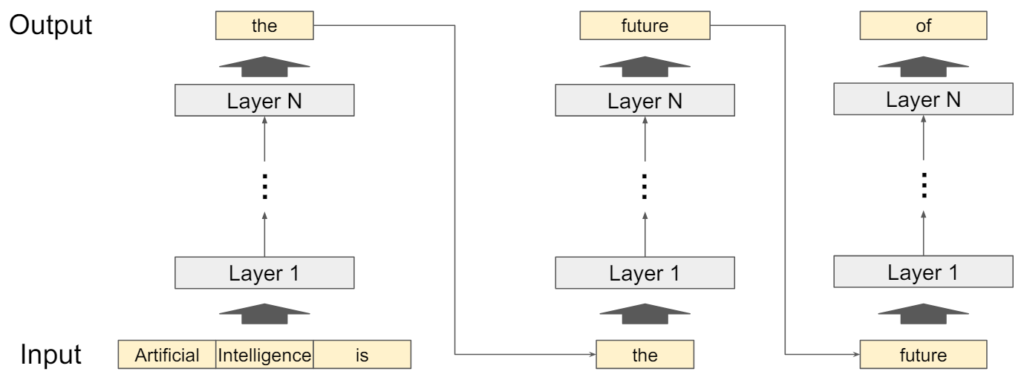
Transformerのアーキテクチャでは、新しいトークンを生成する際に、現在のトークンだけでなく、以前の全てのトークンも保持する必要があります。これらの情報はKVキャッシュというトークンの中間ベクトル表現を保存するためのメモリ領域に格納され、シーケンスが終了するまでキャッシュが蓄積されていきます。
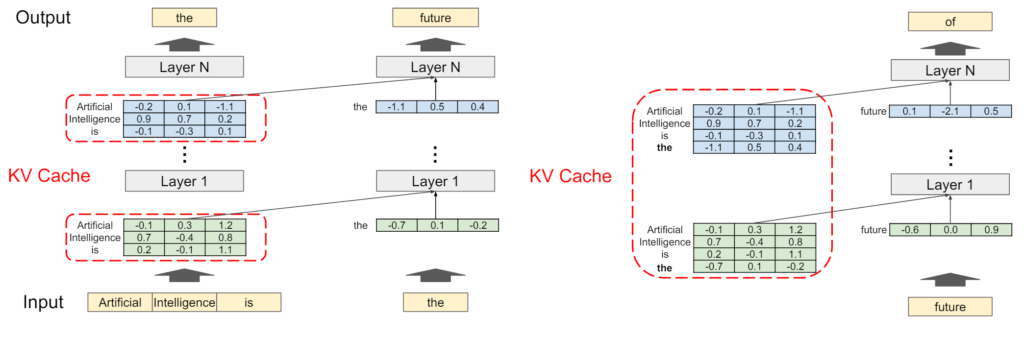
補足:KVキャッシュの必要性について
KVキャッシュは、LLMのテキスト生成を効率化するために使われます。
通常、モデルは1つのトークンを生成するごとに、前のトークンの情報を基に新しい予測を行います。例えば、トークン番号100を予測する際には、前の99個のトークンの情報が必要で、次にトークン番号101を予測する際には、最初の99個のトークンに加えてトークン番号100の情報も必要になります。このプロセスにおいて、Transformerでは、各トークンごとのKeyとValueの計算を行う必要があります。
ここでKVキャッシュを使用すると、以前の計算結果を保存し、後続のトークン予測で再利用することができるようになります。これにより、同じ計算を繰り返す必要がなくなり、生成プロセスが高速化されます。
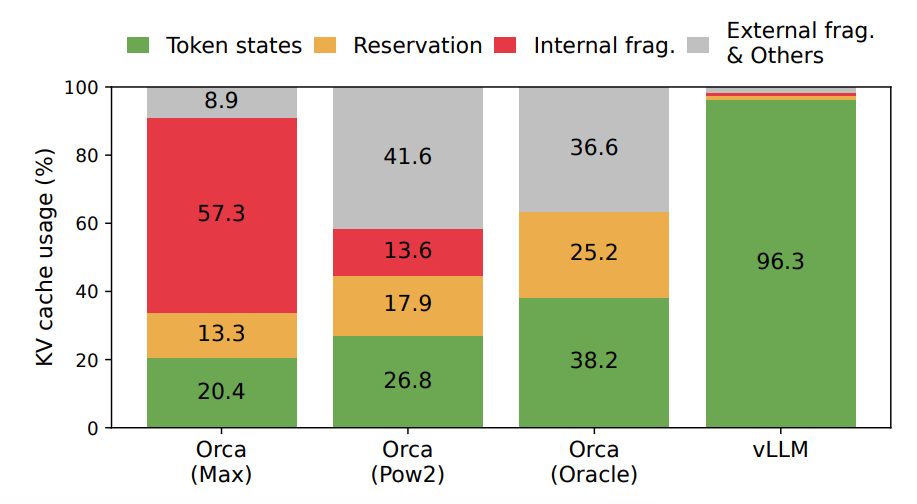
KVキャッシュはキャッシュという名前がついていますが、実際には作業セットとして機能しており、シーケンスが終了すると不要なトークンはキャッシュから削除されます。しかし、このKVキャッシュの運用について、従来の推論プロセスでは多くの無駄があるということが、調査の結果から判明しました。図4では、最大2048トークンのシーケンス長を持つリクエストが投げられた際のメモリ割り当てを示しています。ここでは、以下の3つの無駄があるということが示されています。
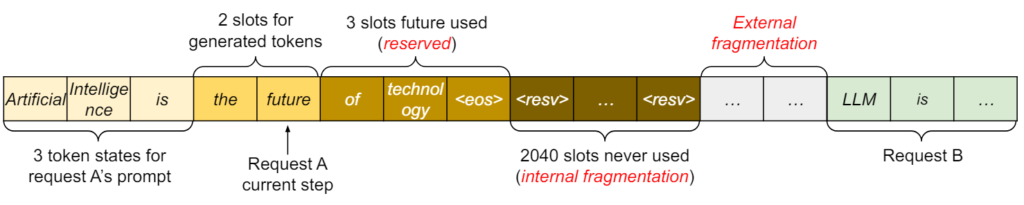
- 予約 (reserved) : 現在使用していないが、将来のトークンのためにメモリを事前に確保した領域。
- 内部断片化 (internal fragmentation) : 過剰に確保されたメモリが未使用のまま残った領域。
- 外部断片化 (External fragmentation) : メモリアロケーターの仕組みによって生じる未使用メモリの領域。
これらの無駄によって、実際にトークン保存に利用されているメモリは20〜40%に過ぎないことが調査の結果からわかりました(図5の緑の領域がトークン保存に利用されている領域)。
このKVキャッシュの無駄がLLMの推論にどのような影響を与えるかを考えます。ここでは、複数の入力を同時に処理するバッチ処理について検討してみます。
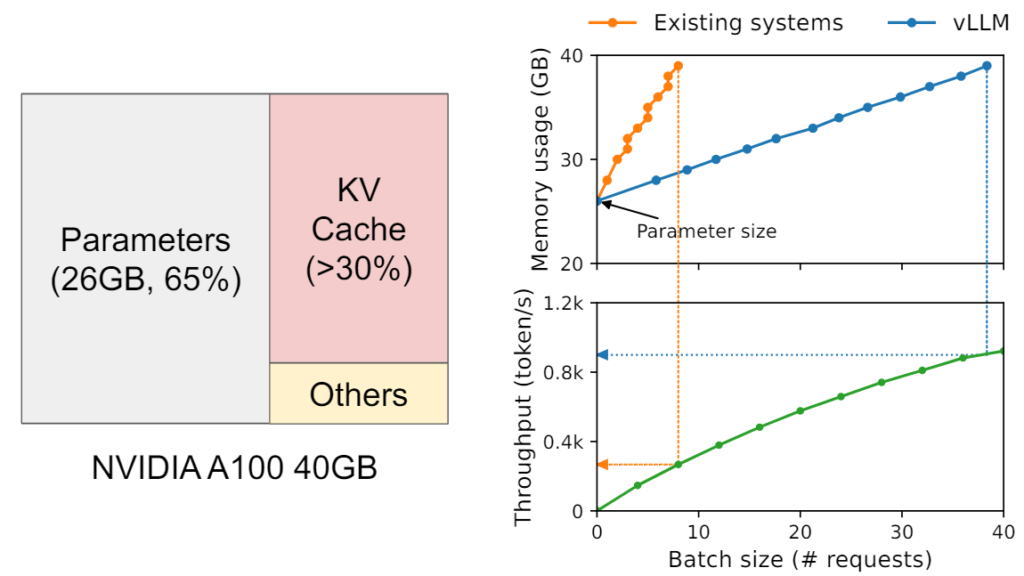
具体例として、13Bパラメータを持つLLMを考えましょう。このモデルを40GBのメモリ環境で動作させる場合、モデルパラメータを格納するために約26GBのVRAMが必要となり、残りの14GBがKVキャッシュ用に割り当てられます。図6では、この環境で推論を行った際のバッチサイズに対するメモリ使用量とスループットが示されています。従来のシステム(Existing systems)では、バッチサイズが小さい段階でVRAMの容量が限界に達し、スループットも低くなっていることがわかると思います。
この図からわかるように、バッチ処理ではKVキャッシュの保存に割り当てられるスペースがスループットに直接影響を与えます。つまり、LLMのスループットは、メモリ容量に大きく依存するということです。詳細は後述しますが、vLLMではこのKVキャッシュを効率的に運用することで、メモリ使用を最適化し、より大きなバッチを高速に処理することが可能になりました。
PagedAttention
PagedAttentionは、vLLMの高速化を支える主要な技術の一つです。この技術はOSのページング技術にヒントを得たアルゴリズムになっており、Key / Valueを一定サイズのページに分割して配置し、必要なページのみを動的にメモリにロードすることで、全体のメモリ使用量を抑えつつ高速なアクセスを実現しています。
新しいKVキャッシュ管理手法
PagedAttentionでは、各シーケンスのKVキャッシュをKVブロックに分割します。図7はそのイメージ図です。ブロックはトークンを左から右に保存できる固定サイズのメモリチャンクで、論理KVブロックと物理KVブロックの2つのブロックが定義されています。
論理KVブロックではトークンが自然な順序で格納されており、物理KVブロックでは連続したブロックの任意の場所にトークンが配置されます。論理KVブロックと物理KVブロックのマッピングはブロックテーブルと呼ばれる新しいデータ構造に保存されます。
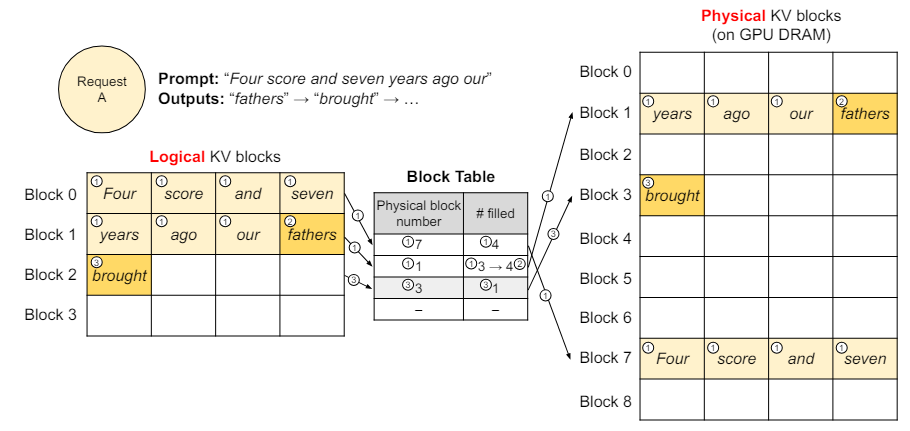
【推論の流れ】
①入力プロンプトの7つのトークンを論理KVブロック(Block 0, 1)と物理KVブロック(Block 7, 1)にマッピングする。Attentionアルゴリズムによって得られたKVキャッシュは、論理KVブロックのBlock 0, 1に格納する。
②新しく生成したトークン(fathers)は、論理KVブロックで空いているBlock 1のスロットに割り当てられる。新しく生成されたKVキャッシュもそこに保存され、ブロックテーブルの# filledレコードが更新される。
③次の生成トークン(brought)は論理KVブロックが満杯のため、新しく生成されたKVキャッシュを新しい論理KVブロック(Block 2)に保存する。このとき、新しい物理KVブロック(Block 3)を紐づけ、それをブロックテーブルに記録する。
このシステムの鍵となるのは、ブロックが事前に割り当てられるのではなく、必要に応じて割り当てられるという点です。これにより、メモリの無駄はシーケンスの最後のブロックでのみで発生し、その無駄を全体の4%未満に抑えることに成功しました。
効率的なメモリ共有
PagedAttentionには、メモリ共有という重要な利点もあります。例えば、並列サンプリングでは同じプロンプトから複数の出力シーケンスが生成されますが、既存のシステムではシーケンスのKV キャッシュが連続した別々のスペースに格納されるため、メモリを共有することは不可能でした。しかし、PagedAttentionのKVキャッシュ管理手法を使えば、出力シーケンス間でメモリを共有することが可能になります。
図8はそのイメージ図です。異なるシーケンスは論理ブロックを同じ物理ブロックにマッピングすることでメモリを共有できます。また、安全な共有を保証するため、PagedAttentionは物理ブロックの参照カウントを追跡し、Copy-on-Writeメカニズムを実装しています。これにより、効率的なメモリ使用と高性能な推論を両立させることができます。
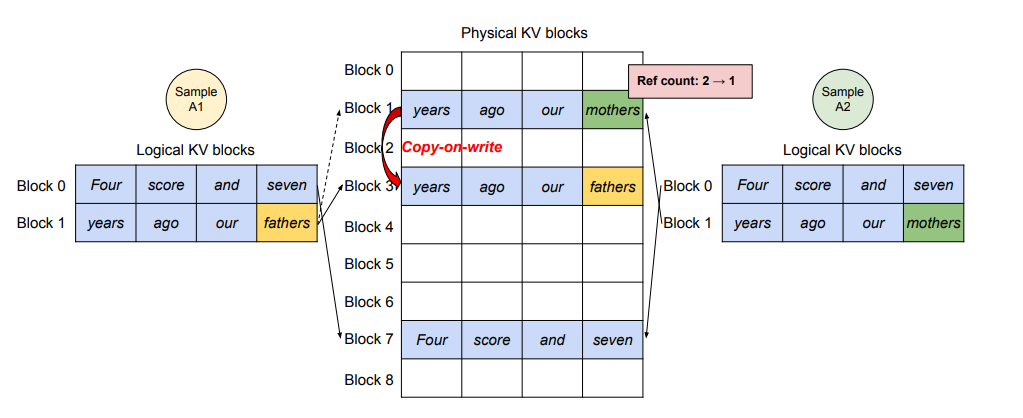
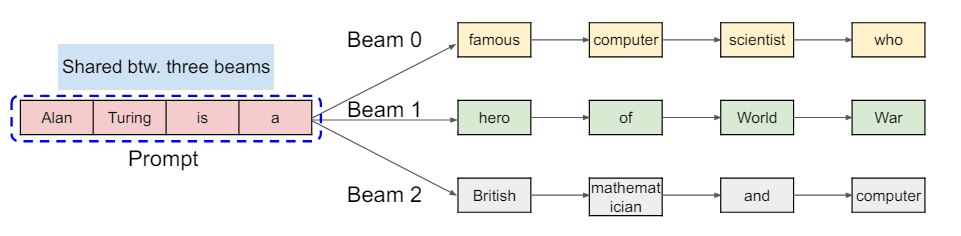
これにより、並列サンプリングやビームサーチなどの複雑なサンプリングアルゴリズムのメモリのオーバーヘッドが大幅に削減され、メモリ使用量が最大55%削減、スループットが最大2.2倍向上しました。
補足:ビームサーチ(Beam Search)とは
ビームサーチは、生成モデルで使用される探索アルゴリズムの一つで、特に文章生成や機械翻訳などのタスクで広く利用されています。深さ優先探索の一種であり、各ステップで複数の候補を保持することで、最適な出力シーケンスを探索します。
具体的には、各ステップで一定数(ビーム幅)の候補を保持し、その中から最も有望な候補を次のステップに進めます。例えば、ビーム幅が3の場合、各ステップで最も確率の高い3つのシーケンスを選び出し、その次の単語を生成します。このプロセスを繰り返すことで、最終的に最も高確率のシーケンスを出力します。利点としては、単純なグリーディーサーチ(各ステップで最も高確率の選択肢を選ぶ)に比べて、より多様な候補を考慮するため、全体としてより良いシーケンスを生成できる点です。しかし、ビーム幅が大きくなるほど計算量が増加するため、適切なビーム幅の選定が重要になってきます。
バッチ処理について
vLLMでは、スループット向上のためにContinuous Batchingという手法を採用しています。この手法により、効率的なバッチ処理が可能となります。ここでは、一般的に利用されるStatic Batchingという手法と対比しながら、説明していきます。
繰り返しの説明となりますが、LLMの推論は図10のように、ユーザーが入力したプロンプトを基に次のトークンを生成し、生成されたトークンをプロンプトに追加して再度モデルに入力するプロセスを繰り返します。そして、このプロセスは、シーケンスが最大長に達するか、特定の停止トークンが生成されるまで続けられます。
Static Batching(静的バッチ処理)
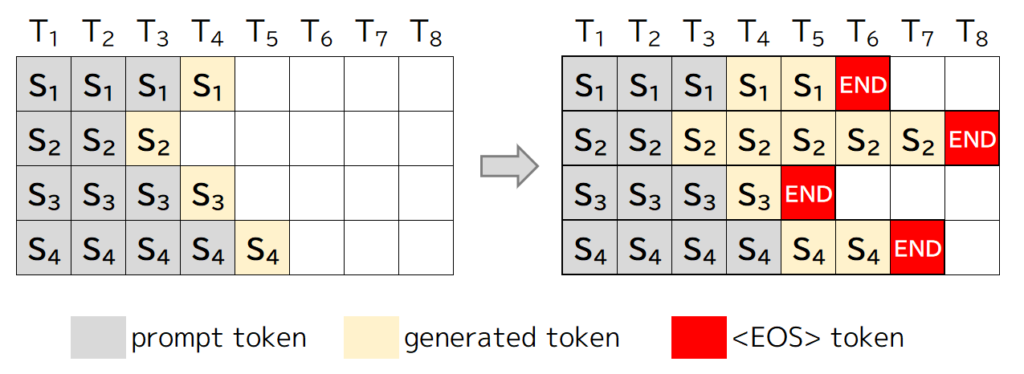
Static Batchingとは、事前に決められたサイズのバッチを用いてモデル推論を行う手法です。
バッチサイズは固定されているため、特定のデータセットや処理パターンが事前に予測可能な場合には有用な手法となります。しかし、LLMの推論においては、リクエストがバッチ内で早期に終了する可能性があり、早く生成を終えた列は生成が完了していない列を待つ必要があるため、GPUの利用効率が低くなるという問題が生じてしまいます(図11において、1,3,4行目のシーケンスは2行目のシーケンスの完了を待つ必要があります)。
Continuous Batching(連続バッチ処理)
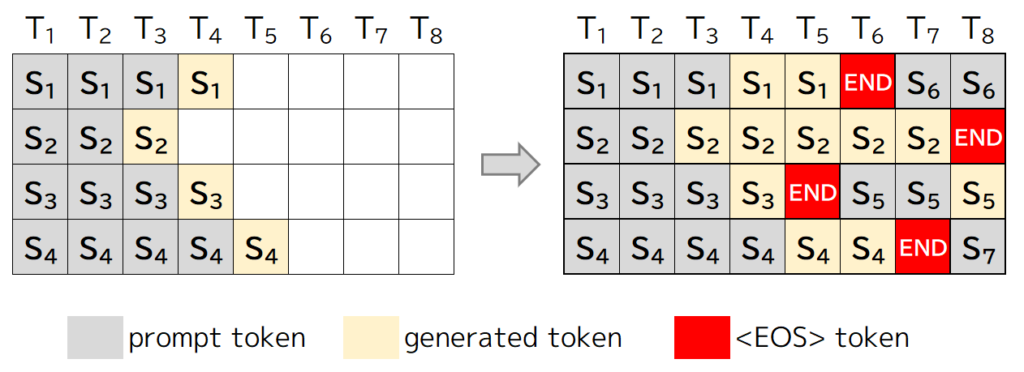
そこで採用されたのが、Continuous Batchingです。Continuous Batchingは、一定の時間間隔で到着する入力データを動的にバッチにまとめて推論を行う手法です。
バッチ内のすべてのシーケンスの生成が完了するまで待つのではなく、各反復ごとにバッチサイズを決定するので、バッチ内のシーケンスの生成が完了すると、新しいシーケンスをその場所に挿入でき、Static BatchingよりもGPUの利用効率が高くなります。
vLLMでは、この仕組みを取り入れることで、早期に生成を完了したシーケンスのリソースを即座に新しいシーケンスに割り当てることが可能となり、待機時間を減らしGPUの利用効率を最大化しました。
バッチ処理の詳細について、気になる方は以下の記事をお読みください。
参考記事 : How continuous batching enables 23x throughput in LLM inference while reducing p50 latency
vLLMの速度検証
次に、実際にvLLMを利用することで推論速度がどのくらい変わるかを簡単に検証します。比較の対象はHugging FaceのTransformers(HF)です。検証は以下の2パターンで実施しました。
- 単純な推論速度の比較
- プロンプト1件
- 同一プロンプト10件
- 異なるプロンプト10件
- 同一プロンプトの同時実行数増加に伴う推論速度の比較
LLMには、楽天が公開した日本語LLM「RakutenAI-7B-chat」を利用しました。推論速度の指標として、throughput(1秒あたりの出力トークン数)と全ての出力が完了した時間を確認します。
※ Transformersは直列実行、vLLMは並列実行と実行方法に違いがあります。また、使用するライブラリが異なるため、条件を完全に一致させることはできていません。あくまで結果は推論速度の目安としてご参考にしてください。
検証結果
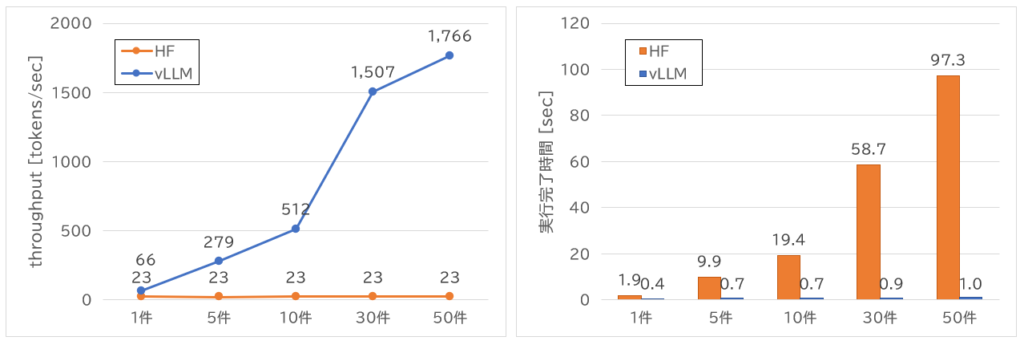
結果は以下の通りです。vLLMはバッチ処理に特化しているため、同時実行数が増えるとスループットが高くなることが分かります。また、シーケンス間のメモリ共有機能もあるため、異なるプロンプトよりも同一プロンプトの方が、共有できる部分が増えてスループットが高くなることも結果から明らかになりました。
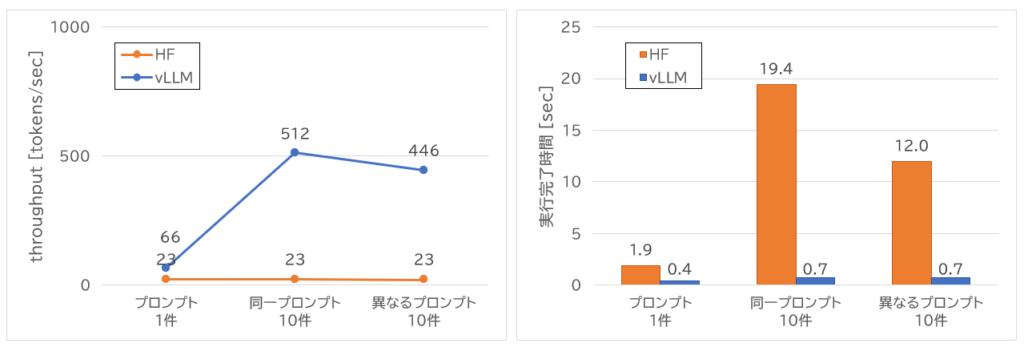
HFは直列実行のため、基本的にスループットには変化がありませんが、vLLMは同時実行数が増えるに従ってスループットが大幅に向上していることがわかります。実行完了時間も件数が増えてもほとんど差がなく、メモリに余裕がある場合は高い推論速度を維持できることが確認できました。
実行環境
実行環境:Google Colabratory
GPU:NVIDIA A100 40GB
実装コード(HF)
!pip install -q transformers accelerate sentencepiece
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Rakuten/RakutenAI-7B-chat"
# modelとtokenizerの読み込み
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
def generate_text_and_calculate_tokens(requests, tokenizer, model):
total_time = 0
total_tokens = 0
for req in requests:
start = time.time()
input_ids = tokenizer(req, return_tensors="pt", add_special_tokens=False).to(model.device)
output_ids = model.generate(
**input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.01,
pad_token_id = tokenizer.pad_token_id,
)
elapsed_time = time.time() - start
total_time += elapsed_time
output = tokenizer.decode(output_ids[0][len(input_ids[0]):], skip_special_tokens=True)
total_tokens += len(tokenizer(output, return_tensors="pt")["input_ids"][0])
print(f"Time: {elapsed_time:.2f} s, Output: {output}")
# 1秒あたりの生成token数を計算
tokens_per_second = total_tokens / total_time
print()
print(f"Total time: {total_time:.1f} s")
print(f"Total tokens generated: {total_tokens}")
print(f"Tokens per second: {tokens_per_second:.2f} tokens/s")
# 実験1:プロンプト1件
requests = ["USER: 大規模言語モデルについて1行で教えてください。 ASSISTANT:"]
generate_text_and_calculate_tokens(requests, tokenizer, model)
# 実験2:同一プロンプト10件
requests = ["USER: 大規模言語モデルについて1行で教えてください。 ASSISTANT:"] * 10
generate_text_and_calculate_tokens(requests, tokenizer, model)
# 実験3:異なるプロンプト10件
requests = [
"USER: 大規模言語モデルについて1行で教えてください。 ASSISTANT:",
"USER: 生成AIについて1行で教えてください。 ASSISTANT:",
"USER: 機械学習について1行で教えてください。 ASSISTANT:",
"USER: 深層学習について1行で教えてください。 ASSISTANT:",
"USER: 強化学習について1行で教えてください。 ASSISTANT:",
"USER: 自然言語処理について1行で教えてください。 ASSISTANT:",
"USER: 畳み込みニューラルネットワークについて1行で教えてください。 ASSISTANT:",
"USER: Transformerモデルについて1行で教えてください。 ASSISTANT:",
"USER: AIと機械学習の違いについて1行で教えてください。 ASSISTANT:",
"USER: 生成モデルと識別モデルの違いについて1行で教えてください。 ASSISTANT:",
]
generate_text_and_calculate_tokens(requests, tokenizer, model)
実装コード(vLLM)
!pip install -q vllm
import time
import torch
import vllm
model_name = "Rakuten/RakutenAI-7B-chat"
# modelとtokenizerの読み込み
model = vllm.LLM(
model=model_name,
dtype="auto",
trust_remote_code=True,
)
tokenizer = model.get_tokenizer()
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
def generate_text_and_calculate_tokens_vllm(requests, tokenizer, model):
total_tokens = 0
sampling_params = vllm.SamplingParams(
temperature=0.01,
max_tokens=100
)
start = time.time()
responses = model.generate(requests, sampling_params=sampling_params, use_tqdm=False)
total_time = time.time() - start
for response in responses:
total_tokens += len(response.outputs[0].token_ids)
print(response.outputs[0].text)
# 1秒あたりの生成token数を計算
tokens_per_second = total_tokens / total_time
print()
print(f"Total time: {total_time:.1f} s")
print(f"Total tokens generated: {total_tokens}")
print(f"Tokens per second: {tokens_per_second:.2f} tokens/s")
# 実験1:プロンプト1件
requests = ["USER: 大規模言語モデルについて1行で教えてください。 ASSISTANT:"]
generate_text_and_calculate_tokens_vllm(requests, tokenizer, model)
# 実験2:同一プロンプト10件
requests = ["USER: 大規模言語モデルについて1行で教えてください。 ASSISTANT:"] * 10
generate_text_and_calculate_tokens_vllm(requests, tokenizer, model)
# 実験3:異なるプロンプト10件
requests = [
"USER: 大規模言語モデルについて1行で教えてください。 ASSISTANT:",
"USER: 生成AIについて1行で教えてください。 ASSISTANT:",
"USER: 機械学習について1行で教えてください。 ASSISTANT:",
"USER: 深層学習について1行で教えてください。 ASSISTANT:",
"USER: 強化学習について1行で教えてください。 ASSISTANT:",
"USER: 自然言語処理について1行で教えてください。 ASSISTANT:",
"USER: 畳み込みニューラルネットワークについて1行で教えてください。 ASSISTANT:",
"USER: Transformerモデルについて1行で教えてください。 ASSISTANT:",
"USER: AIと機械学習の違いについて1行で教えてください。 ASSISTANT:",
"USER: 生成モデルと識別モデルの違いについて1行で教えてください。 ASSISTANT:",
]
generate_text_and_calculate_tokens_vllm(requests, tokenizer, model)
その他の高速化手法
最後にvLLM以外にも様々なLLMの推論高速化手法がありますので、簡単に紹介します。手元で速度比較は行えていないため、推論速度についてはあまり触れずに技術の概要の紹介だけに留めさせて頂きます。
DeepSpeed-Inference
DeepSpeedはMicrosoftが開発した深層学習処理の最適化ライブラリです。
公式ドキュメント : DeepSpeed Docs
GitHub : https://github.com/microsoft/DeepSpeed
DeepSpeedには、大規模な深層学習モデルの訓練や推論に利用できる様々な機能が搭載されており、LLMの推論に利用できる機能としてDeepSpeed-Inferenceがあります。
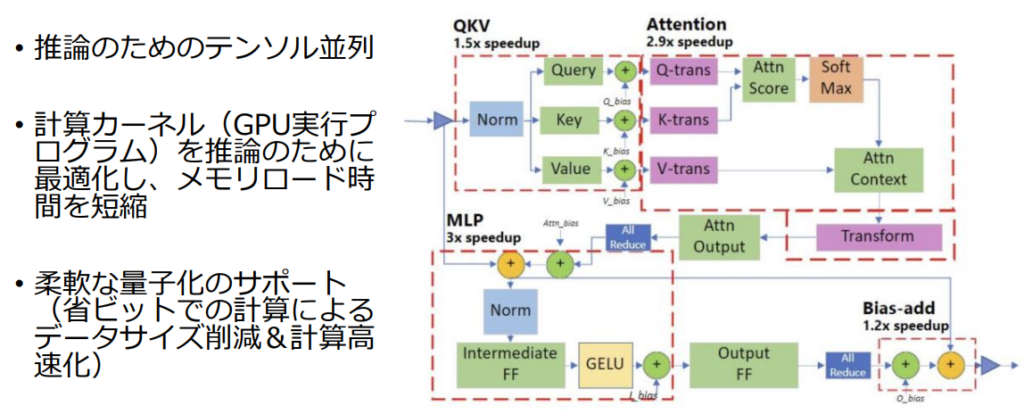
DeepSpeed-Inferenceでは、Transformerカーネルの工夫や並列計算、GPUのメモリに乗りきらないモデルをCPUのメモリを使って動かすなど、様々な機能が利用できます。
FlashAttention
FlashAttentionは、Transformerモデルの自己注意メカニズムの計算効率とメモリ使用量を大幅に改善する手法です。従来の自己注意メカニズムでは、系列長が増えると計算量とメモリ使用量が二次的に増加する問題があります。これに対し、FlashAttentionは計算アルゴリズムとGPUメモリへのアクセス方法を最適化することで、GPUメモリ使用量を系列長に対して線形に抑え、計算速度も向上させました。
具体的には、Tiling技術を使用して、巨大な注意行列をHBMに格納せず、SRAM上で計算を行うことでメモリアクセス時間を削減しています。また、Recomputation技術を活用し、順伝播で使用した正規化係数を保存し、逆伝播計算時に高速に再計算することで、メモリ使用量をさらに減少させています(結果をメモリに保存するより再計算した方が速いため)。この結果、FlashAttentionは系列長に対して線形のメモリ使用量を実現し、標準的なAttention実装に比べて高速かつメモリ効率が良くなりました。
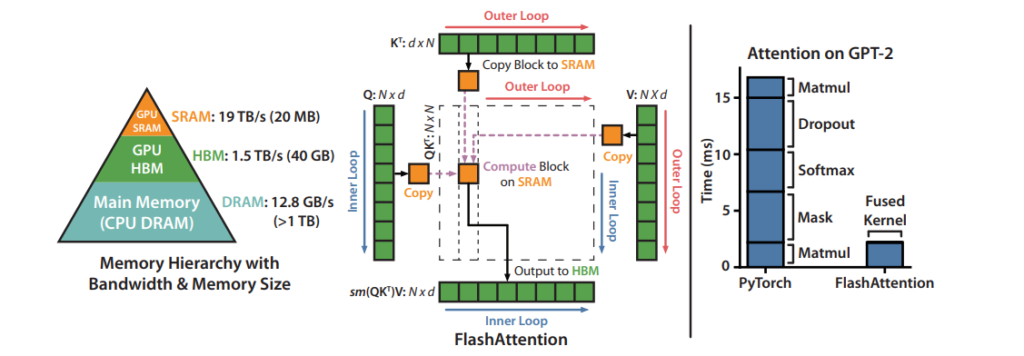
FlashAttentionは継続的に改良が重ねられており、執筆時点ではFlashAttention-3まで公開されています。
FlashAttention
FlashAttention-2
- 並列化とワークパーティショニングをさらに改善
- 論文 : FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
FlashAttention-3
- Nvidia Hopper GPU(H100およびH800)に最適化
- 論文 : FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
詳細は以下の記事がわかりやすかったので、参考にしてください。
参考記事 : GPU と FlashAttension をちゃんと理解したい
vAttention
vAttentionは、Microsoftが開発したライブラリで、動的なメモリ管理を行うことでスループットの向上を図る手法です。PagedAttentionの問題点を解決するために設計されました。
論文 : vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention
GitHub : https://github.com/microsoft/vattention
上記の論文では、PagedAttentionの問題点として、非連続な仮想メモリの使用がソフトウェアの複雑さを増し、効率性にも課題があることが指摘されています。vAttentionはこの問題を解決するために提案された手法で、KVキャッシュを連続した仮想メモリに格納し、OSのサポートを活用して物理メモリをオンデマンドで割り当てることで、既存のアテンションカーネルに対して動的な物理メモリ割り当てのサポートを追加し、より効率的な動作を実現します。このアプローチにより、vAttentionはvLLMよりも高速に動作することが実証されています。

おわりに
本記事では、vLLMの仕組みの理解と推論速度の向上を簡単に検証しました。結果として、複数のシーケンスを同時に扱う場合において、vLLMが大幅に推論速度を向上させることが確認されました。大量の評価プロンプトを用いてLLMの性能を評価する場面や、大量のリクエストを受けるサービスを運用する場面などで、vLLMは効果を発揮するでしょう。
今後、オープンソースのLLMを積極的に活用する段階に移行する際には、必要に応じてvLLMなどの高速化手法を取り入れることを検討していこうと思います。また、時間があれば、他の高速化手法との性能比較も行ってみたいと思います。
参考
- vLLM Docs
- vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
- Race to the Bottom? LLM Inference in 2024
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- How continuous batching enables 23x throughput in LLM inference while reducing p50 latency
- DeepSpeed Docs
- https://github.com/microsoft/DeepSpeed
- DeepSpeed:深層学習の訓練と推論を劇的に高速化するフレームワーク
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
- GPU と FlashAttension をちゃんと理解したい
- vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention
- https://github.com/microsoft/vattention
オウンドメディアも運営しています
- コレスポンデンス分析とは?ビジネス活用や注意点を解説! | Data Analytics Magazine (dalab.jp)
- 因子分析とは?ビジネス活用や注意点を解説! | Data Analytics Magazine (dalab.jp)
- 需要予測とは?今すぐ役立つ分析手法・活用事例を厳選して紹介!
- MMM(マーケティング・ミックス・モデリング)とは? | Data Analytics Magazine (dalab.jp)
- 「0,1判別」の定番手法!ロジスティック回帰分析とは? | Data Analytics Magazine (dalab.jp)
- クラスター分析とは?わかりやすく解説! | Data Analytics Magazine (dalab.jp)