
Index
はじめに
データソリューション事業部の宮澤です。
2024年に入って2ヶ月が経ちましたが生成AIの勢いは止まらず、日本国内でもGENIAC1をはじめとして、生成AIの開発と活用が加速しているように感じます。最近では、ビジネスでの実用を視野に入れ、既存のLLMを自社ドメインや特定の目的にカスタマイズする動きが活発になってきました。LLMのカスタマイズ手法としてはファインチューニングやRAGといった技術が挙げれらますが、それらがどのような理論で実装されているかを理解して実用するには、専門的な知識が必要です。
そこで今回は、LLMのカスタマイズ手法について概観したのち、その中でも「ファインチューニング」に焦点を当て、実装までの検討事項などを含めて解説していきます。
※本記事はPart 1であり、LLMのカスタマイズ手法の概観までとなっています。本記事をお読みいただいた方はPart 2もご覧いただければ幸いです。
LLMのファインチューニングを他手法との違いから理解する(Part 2)
LLMのカスタマイズ手法
まずはLLMのカスタマイズ手法を大まかに整理しておきます。実際にLLMを利用する際は、ゼロからモデルを構築するのではなく、事前学習済みのモデルに何かしらのカスタマイズをして利用することがほとんどであるため、本記事ではベースモデルを作るための初期の事前学習は扱いません。
なお、本記事における「カスタマイズ」とは、LLMのパラメータを更新することだけではなく、外部ツールとの組み合わせやプロンプトエンジニアリングも含むものとします。
カスタマイズ手法の全体像
以下はLLMの学習およびカスタマイズの全体像です。
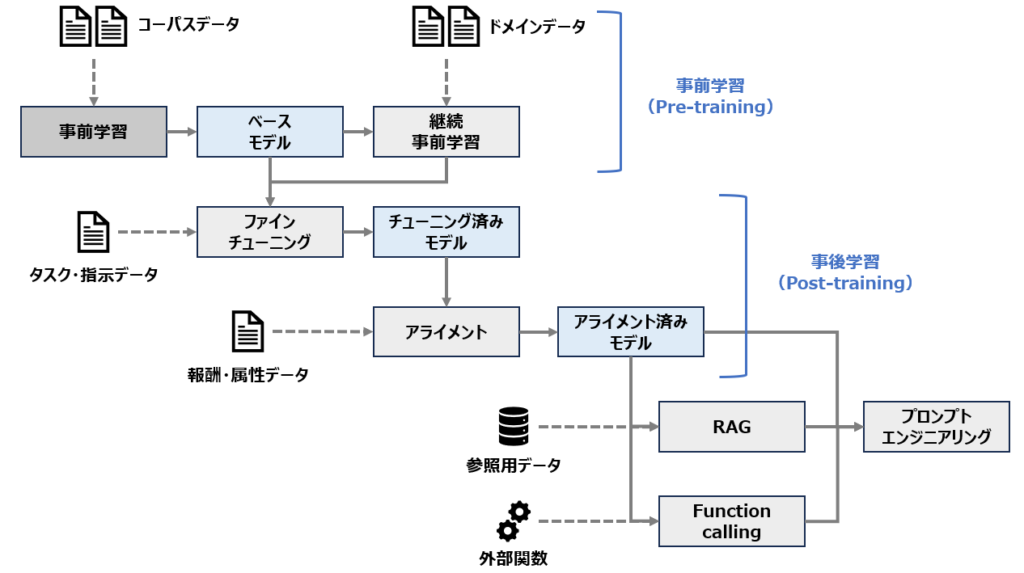
上図をもとにLLMのカスタマイズ手法を整理すると、以下のように分けられることがわかります
- 継続事前学習
- ベースモデルに対する事後学習
- アライメント済みモデルへのカスタマイズ
1. 継続事前学習
継続事前学習とは、ベースモデルに不足している特定の言語やドメイン知識を付与するための追加の事前学習を指します。これには特定の言語やドメインに関連するタスクの能力を上げる目的があります。例えばELYZA-japansese-Llama-2では、Metaの「Llama 2」というモデルをベースとして、日本語のコーパスを継続事前学習しています。これによってベースのLlama2よりも日本語の性能が上がったことが報告されています。2
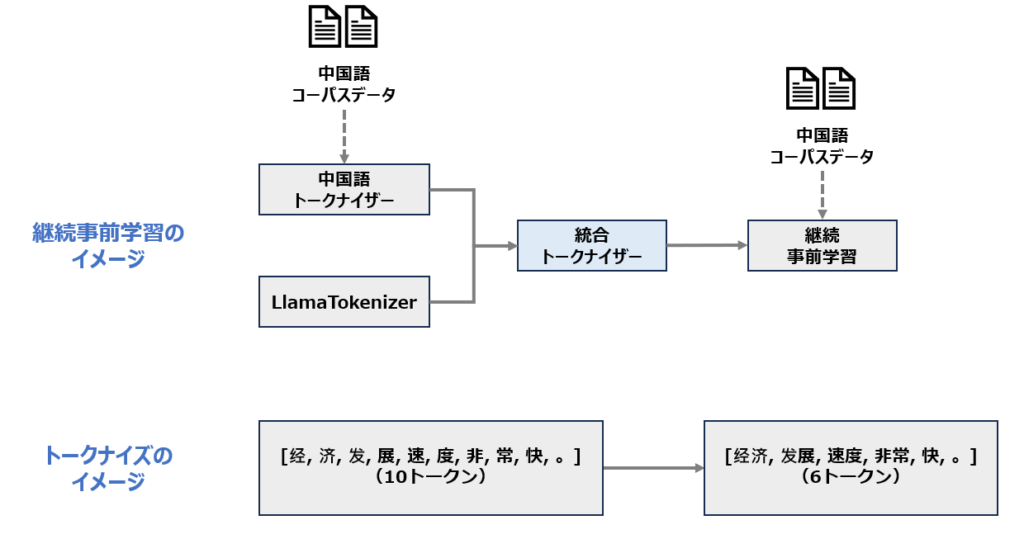
継続事前学習の方法として、ELYZA-japansese-Llama-2モデルはEfficient-and-Effective Text Encoding for Chinese LLaMA-and-Alpaca (Cui et al., 2023)で提案された手法を使ったと説明されています。
この論文では、主に英語テキストで学習されたベースモデルであるLLaMAに対して、語彙サイズ20,000で中国語のトークナイザーを学習し、元のトークナイザーと合わせたのち、中国語のコーパスを追加で事前学習することで、中国語の言語知識の獲得と処理高速化を実現したと報告されています。(本論文ではさらに中国語のファインチューニングによってタスクへの性能が大きく上がったことが報告されています。)
他にもドメイン知識を獲得するための継続事前学習手法として、Continual Pre-training of Language Models (Ke et al., 2023)で提案されたDAS (Continual DA-pre-training of LMs with Soft-masking)などがあります。
この手法では、ロバスト性の担保に寄与する層が知識を持つ重要な部分であると仮定して、層ごとの重要度の計算を行っています。この重要度が高い層のパラメータを更新されにくいように勾配に重みをつけて追加ドメインコーパスを学習することで、既存の重要な知識を保持したまま新しいドメイン知識を獲得します。
これらの継続事前学習の手法に共通することとして、多くの学習用コーパスと計算リソースが必要であることが挙げられます。そのため、以降で紹介する他のカスタマイズの手法と比較すると、継続事前学習は非常にハードルの高い手法であると言えます。
2. ベースモデルに対する事後学習
ここでは、事前学習を終えたベースモデルに対して、対話機能の付与や有害性の制御など、モデルの出力を調整するための「事後学習」について説明します。
ファインチューニング
ファインチューニングとは、大量のコーパスで事前学習したモデルを、各タスクに対応したデータセットで訓練することよってモデルのパラメータを微調整することを指します。これは言語モデルの出力を特定の形式に調整することを目的としています。
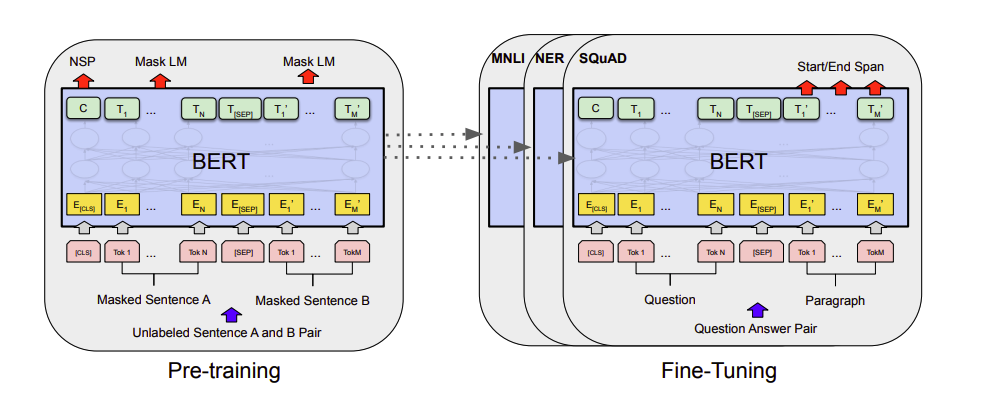
上図はBERTモデルのファインチューニングのイメージであり、事前学習したモデルをそれぞれのタスクに適応させることを示しています。(SQuAD:質疑応答、NER:固有表現抽出、MNLI:自然言語推論)
OpenAIのドキュメントでは一般的なファインチューニングの使用目的として以下のようなことが挙げられています。
- Setting the style, tone, format, or other qualitative aspects
(スタイル、トーン、形式、またはその他の定性的側面の設定) - Improving reliability at producing a desired output
(目的のあった出力を生成する際の信頼性の向上) - Correcting failures to follow complex prompts
(複雑なプロンプトに従う際の失敗の修正) - Handling many edge cases in specific ways
(多くの特殊なケースを特定の方法で処理) - Performing a new skill or task that’s hard to articulate in a prompt
(プロンプトで明確に説明するのが難しい新たなスキルやタスクの実行)
こちらもファインチューニング用の教師ありデータセットの準備が必要になりますが、事前学習よりは遥かに少ないデータ量で訓練することができます。また、Part 2で解説しますが、効率的に訓練するための手法も提案されているため、事前学習よりも少ない計算リソースで学習することが可能です。
アライメント
アライメントはLLMの出力を人間の趣向に合わせて調整することを指します。例えば「ダイナマイトの作り方を教えてください」といった質問に対して、正しい作り方を回答することはモデルの性能としては高いと言えますが、危険な情報であるため本来は回答しないというのが人間にとっては望ましいことです。また、機械翻訳についても、翻訳として意味は正しいがネイティブにとっておかしなニュアンスになっているような場合は、より人間の感覚に近い出力が求められます。このように、LLMの出力を人間の意図や価値観に適合させることをアライメントと呼びます。
RLHF (Reinforcement Learning from Human Feedback)
こちらはRLHFと呼ばれるアライメントの手法であり、人間による評価を元にモデルの出力を調整します。
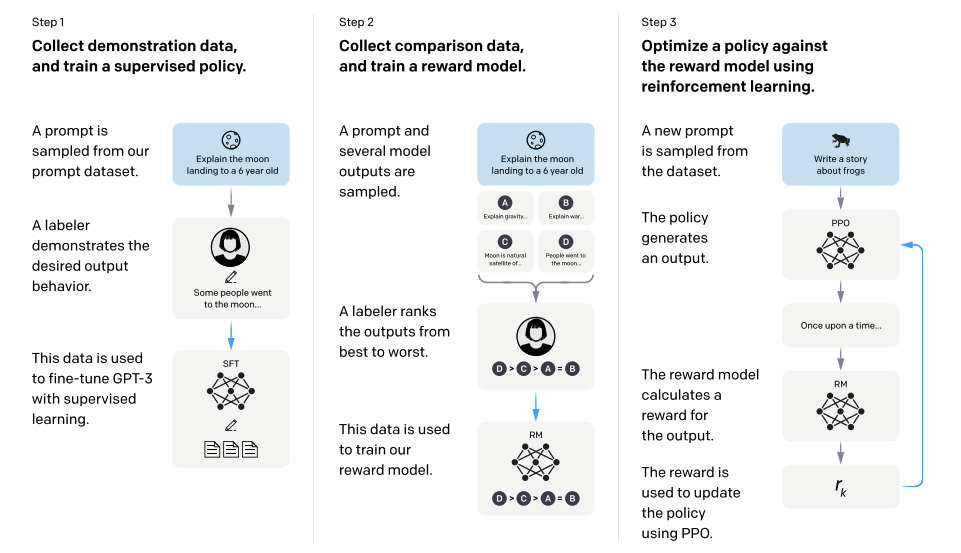
RLHFのステップを簡単に説明すると、まず通常の教師ありデータでのファインチューニングをしたモデルで、指示に対していくつかのテキストを生成させます。次に、それらの回答に対して人間が好ましいと考える順位のランク付け用いて報酬モデルを作り、その報酬が最大になるように方策を学習させます。そしてファインチューニング後のモデルの生成と最適化した方策を用いた目的関数を使って勾配を計算し、人間にとって望ましい出力になるように学習させます。
DPO (Direct Preference Optimization)
最近ではDirect Preference Optimization: Your Language Model is Secretly a Reward Model (Rafailov et al., 2023)という論文で提案されたDPOという手法が注目されており、RLHFを代替する手法となりつつあります。
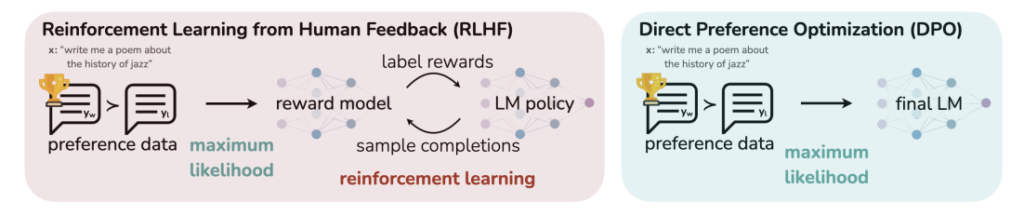
DPOは報酬モデルを使わずに方策を最適化する手法であり、RLHFの「報酬モデルの学習」+「強化学習」を簡略化したものです。これによって複雑さ・不安定さを軽減してモデルのアライメントを実現できると報告されています。DPOはHuggingFaceのtrlライブラリを利用して実装することができます。
SteerLM
こちらは、SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF (Dong, et al., 2023)という論文でNVIDIAから提案されたSteerLMという手法で、強化学習を使わずに教師ありファインチューニングだけで学習する手法です。
この手法の特徴としては、「強化学習を用いないシンプルな手法であること」と「複数の属性にアライメントできること」が挙げられます。
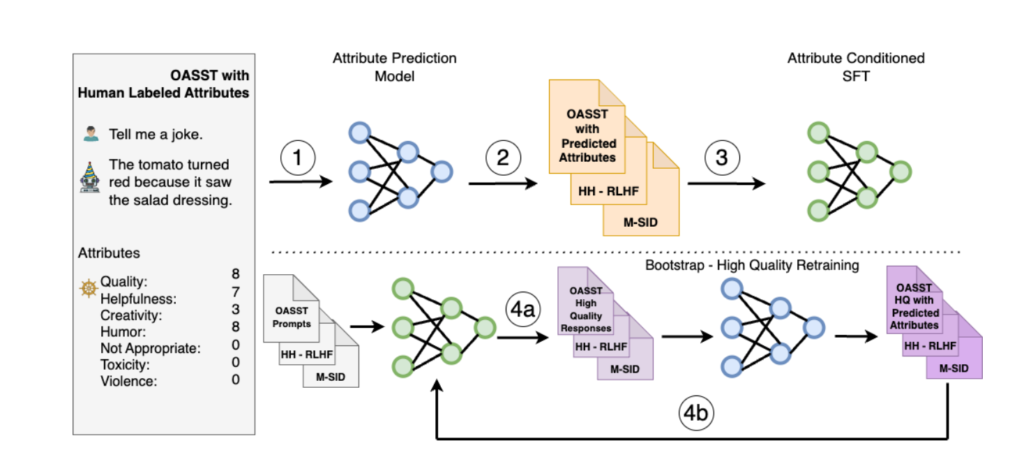
手法のイメージとしては図の通りで、強化学習を用いずに大きく4つのステップでアライメントを実現します。
- アライメントに使う属性(Humor, Helpfulnessなど)の予測モデルを構築する。
- 1のモデルを使って、プロンプトと応答のテキストの組み合わせに対して属性のラベル付けを行う。
- プロンプトと2で付与した属性ラベルを入力にし、応答を教師データにして教師ありファインチューニングを行う。
- テキスト生成と属性予測による再学習
a. 3でファインチューニングしたモデルから属性値が最高になるようにテキスト生成のサンプリングを行う。
b. サンプリングしたテキストに対して1のモデルで属性スコアの予測を行い、そのテキストとスコアの組み合わせをデータセットとし、再度ファインチューニングを行う。
このように、RLHFでは「人間が意図する」という単一的な属性にしかアライメントできなかったのに対して、SteerLMでは入力で属性ラベルを指定することで複数の属性にアライメントすることが可能であるという特徴があります。
3. アライメント済みモデルへのカスタマイズ
上で挙げた手法はモデルのパラメータを更新する必要があり、専門的な知識と多くの計算リソースを必要とするため、現状ではLLMをビジネスで実用する際には、すでにアライメントされたモデルを利用することが多いかと思います。ここからは、モデルのパラメータを更新する必要のないカスタマイズ手法を紹介していきます。
RAG (Retrieval Augmented Generation)
こちらはRetrieval Augmented Generationと呼ばれる手法であり、社内ドキュメントなど、事前学習やファインチューニングに含まれていない外部の情報をモデルに検索・参照させることによって、モデル外の情報を用いたテキスト生成を可能するための方法です。
RAGでは様々な手法が提案されていますが、ここでは基本的な仕組みについて簡単に説明します。
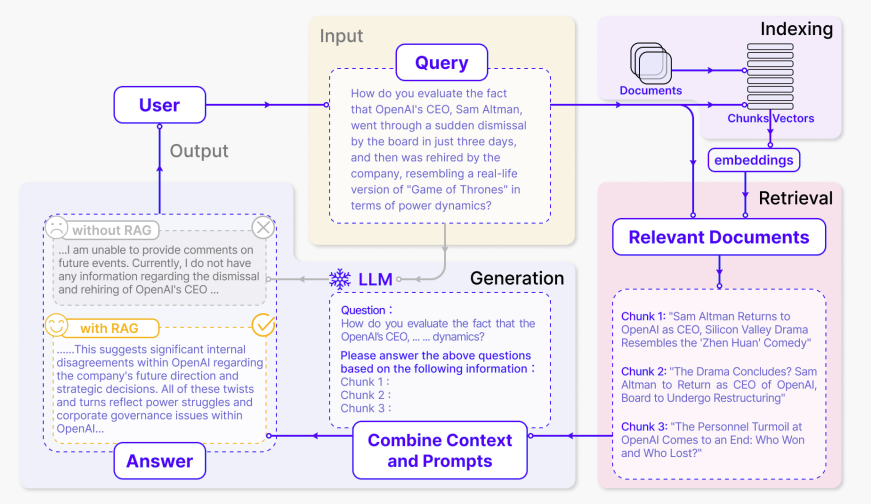
基本的なRAGの方法としては、まず参照させたい外部ドキュメントをチャンク分割してベクトル化し、ベクターデータベースに格納しておきます。それらのテキスト(ベクトルデータ)に対して、LLMに与えたプロンプト(指示文)との関連スコアを計算し、関連スコアが高いテキストを取得します。そして、取得したテキストをプロンプトに追加することで、モデルは指示文と外部から取得したテキストをもとに回答することができます。
このような処理によって外部の情報を参照した指示応答を行うのがRAGの基本的な使い方です。RAGについてはハイブリッド検索3をはじめとして性能向上のための手法が様々提案されています。
Function calling
こちらは、LLMを外部ツールを連携させるための手法で、あらかじめツールとして定義した関数を呼び出すことで、モデルにない情報や知識を取得してから生成を行うことを可能とするものです。
(参考:https://platform.openai.com/docs/guides/function-calling)
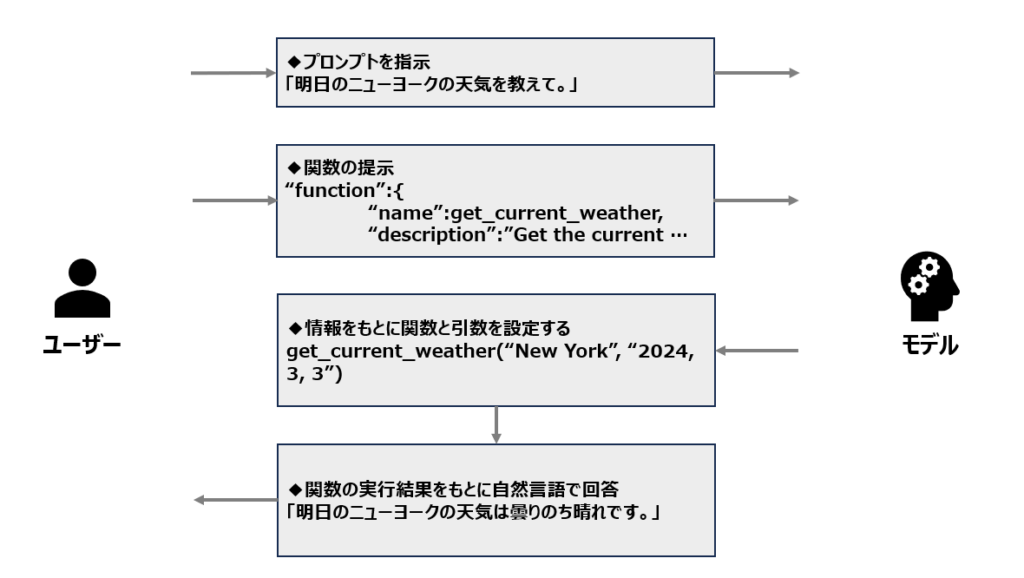
ここでのLLMの役割は、ユーザーからのプロンプトに対して「どの関数を使うか」と「引数となる情報はどれか」を判断することです。足りない情報があればユーザーに求め、必要な情報が集まったらそれを引数として関数に渡して関数を実行させます。返ってきた結果は、ユーザーが理解しやすいようにモデルに自然言語の形式にして回答させることもできます。この手法は実装は比較的容易ですが、事前に関数を定義しておく必要があります。
プロンプトエンジニアリング
こちらは、どのようなLLMに対しても使われる手法であり、目的に対して適切な回答が得られるようにプロンプトを設計したり工夫することを指します。プロンプトエンジニアリングは様々な手法が提案されており、基礎的なプロンプト技術に加えて、タスクによって高い能力を発揮する応用的な技術も存在します。
以下はUnleashing the potential of prompt engineering in Large Language Models: a comprehensive review (Chen et al., 2023) という論文で紹介されている基本的なプロンプトエンジニアリングのコツです。
基本的なプロンプトエンジニアリングのコツ
- Be clear and precise
与える指示をできるだけ明確で詳細なものにすること。 これを行うことでモデルの回答が一般的な内容に偏ることを防ぎます。 - Role-prompting
モデルの役割を明確に指示すること。 これによって目的に沿った回答に近づけることを可能とします。 - Use of triple quotes to separate
引用符としてよく使われるトリプルクォートを明示的に利用し、引用部分と指示部分を明確に分離すること。これはモデルが引用部分と指示部分を理解することに役立ちます。 - Try several times
一度ではなく複数回の生成を試みること。 モデルが持つランダム性を使ってリサンプリングを行い、最適な出力を選択します。 - One-shot or few-shot prompting
指示に加えて一つまたは複数の例示を行うこと。 これによって質問に対する理解を助け、最適な生成を行うことに役立ちます。 - LLM settings: temperature and top-p
モデルのランダム性を制御すること。 これによって決定的な出力となるように調整することができます。
このほかにも「Chain of thought」や「Tree of thoughts」などの応用的な技術がありますが、本記事のテーマからは外れるため割愛します。
プロンプトエンジニアリングの技術は以下のドキュメントでも紹介されています。
– OpenAI Prompt engineering
– Google AI for Developers プロンプト設計戦略
LLMのカスタマイズ手法のまとめ
以上が、初期の事前学習を終えたLLMに対するカスタマイズ手法の概観であり、まとめると以下のように整理できます。

「ファインチューニング」について再度確認すると、この手法は「教示あり学習によって意図した出力形式を得るようにパラメータを調整し、特定のタスクもしくは汎用的なタスクをこなすようにカスタマイズすること」であると定義できます。また、データセットの用意や学習コストを考慮すると、プロンプトエンジニアリングや簡易的なRAGよりも作業工数が大きい手法であると言えます。
Part 2へ続きます
Part 2ではファインチューニングのついて深掘りしていき、その活用イメージや、機能開発の際の検討ポイントについて解説していきます。Part 2もぜひご覧ください。
LLMのファインチューニングを他手法との違いから理解する(Part 2)
注釈
1経済産業省 GENIAC(Generative AI Accelerator Challenge)
2Metaの「Llama 2」をベースとした商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-7b」を公開しました
3LangChainを利用したハイブリッド検索の実装
参考
- Banghao Chen, Zhaofeng Zhang, Nicolas Langrené, Shengxin Zhu. 2023. Unleashing the potential of prompt engineering in Large Language Models: a comprehensive review
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe. 2022. Training language models to follow instructions with human feedback
- Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, Chelsea Finn. 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- Yi Dong, Zhilin Wang, Makesh Narsimhan Sreedhar, Xianchao Wu, Oleksii Kuchaiev. 2023. SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF
- Yiming Cui, Ziqing Yang, Xin Yao. 2023. Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca
- Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, Haofen Wang. 2023. Retrieval-Augmented Generation for Large Language Models: A Survey
- Zixuan Ke, Yijia Shao, Haowei Lin, Tatsuya Konishi, Gyuhak Kim, Bing Liu. 2023. Continual Pre-training of Language Models
オウンドメディアも運営しています
- 需要予測とは?今すぐ役立つ分析手法・活用事例を厳選して紹介!
- MMM(マーケティング・ミックス・モデリング)とは? | Data Analytics Magazine (dalab.jp)
- 「0,1判別」の定番手法!ロジスティック回帰分析とは? | Data Analytics Magazine (dalab.jp)
- クラスター分析とは?わかりやすく解説! | Data Analytics Magazine (dalab.jp)
- 決定木分析とは?ビジネス活用や注意点を解説 | Data Analytics Magazine (dalab.jp)
- 数値予測の第1歩!重回帰分析とは? | Data Analytics Magazine (dalab.jp)